









随机森林算法是机器学习、计算机视觉等领域内应用较为广泛的一个算法、它不仅可以用来做分类(包括二分类和多分类),也可用来做回归预测,也可以作为一种数据降维的手段。
在随机森林中,将生成很多的决策树,并不像在决策树那样只生成唯一的树。随机森林在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,每个树都是一个独立的判断分支,互相之间彼此独立。随机森林在运算量没有显著提高的前提下提高了预测精度,并且对多元公线性不敏感,判断结果缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用。
当在基于某此属性对一个新的对象进行分类判别时,随机森林中的每一棵树都会给出自己的分类选择,并由此进行“投票”,森林整体的输出将会是票数最多的分类选项;而在回归问题中,随机森林的输出将会是所有决策树输出的平均值。相比于单个决策树算法,它的分类、预测效果更好,不容易出现过度拟合的情况。
决策树的构建及其不足
决策树的构建是一个递归的过程,理想情况下所有的记录都能被精确分类,即生成决策树叶节点都有确定的类型,但现实这种条件往往很难满足,这使得决策树的构建时可能很难停止。即使构建完成,也常常会使得最终的节点数据过多,从而导致过度拟合(overfitting),因此在实际应用中需要设定停止条件,当达到停止条件时,直接停止决策树的构建。但这仍然不能完全解决过度拟合问题,过度拟合的典型表现是决策树对训练数据错误率很低,而对测试数据其错误率却非常高。
过度拟合常见原因有:(1)训练数据中存在噪声;(2)数据不具有代表性。过度拟合的典型表现是决策树的节点过多,因此实际中常常需要对构建好的决策树进行枝叶裁剪(Pumne Tree ),但它不能解决根本问题。随机森林算法的出现能够较好地解决过度拟合问题。
随机森林
随机森林是由多个决策树构成的森林,算法分类结果由这些决策树投票得到,决策树在生成的过程当中分别在行方向和列方向上添加随机过程,行方向上构建决策树时采用放回抽样(bootstraping)得到训练数据,列方向上采用无放回随机抽样得到特征子集,并据此得到其最优切分点,这便是随机森林算法的基本原理。
下图给出了随机森林算法分类原理,从图中可以看到,随机森林是一个组合模型,内部仍然是基于决策树,同单一的决策树分类不同的是,随机森林通过多个决策树投票结果进行分类,算法不容易出现过度拟合问题。
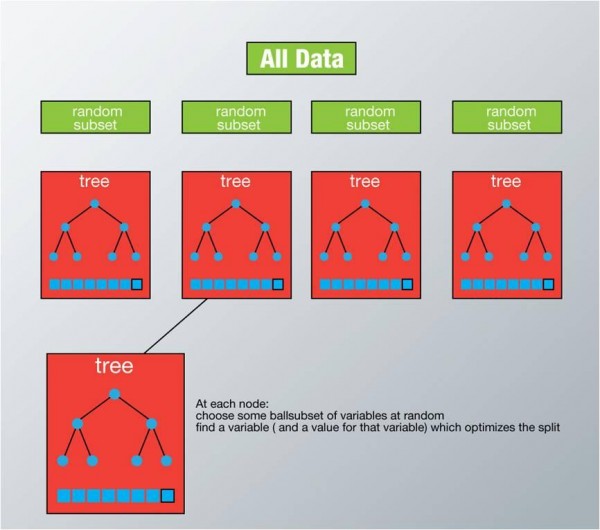
随机森林属于非传统式的机器学习算法,由多颗决策树组成,每棵决策树处理的是一个训练样本子集。训练阶段,通过 决策树的节点分裂来筛选特征,层层对样本进行细分,直至每个训练样本子集分类正确,测试阶段,直接基于训练出的特征进行样本分类,所以测试速度较快(但训练速度较慢)。属于“傻瓜式”的策略(这点和 adaboost很像很像),以下部分是标准随机森林训练阶段的大致流程。
- 1. 假如有N个样本,则有回放的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
- 2.当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m<<M。然后从这m个属性中采用某种策略(如信息增益)来选择一个属性,作为该节点的分裂属性。
- 3.决策树形成过程中,每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚父节点分裂时用过的属性,则该节点已经达到了叶子节点,无需继续分裂)。一直到不能再分裂为止,注意整个决策树形成过程中没有剪枝。
- 4.按步骤1-3建立大量决策树,如此形成随机森林。
从上边的步骤可以看出,随机森林每棵树的训练样本是随机的,数中每个节点的分类属性也是随机选择的,这2个随机的选择过程,保证了随机森林不会产生过拟合现象。
随机森林之“随机‘在哪里
随机森林是一种组合方法,由许多的决策树组成,对于每一颗决策树,随机森林采用的是有放回的对N个样本分N次随机取出N个样本,即这些决策树的形成采用了随机的方法,因此也叫做随机决策树。随机森林中的树之间是没有关联的。当测试数据进入随机森林时,其实就是让每一颗决策树分别进行分类,最后取所有决策树中分类多的那类为最终的结果。
随机森林的另一个"随机"点是对于每一个决策树,节点是按照从样本所有属性中随机抽取一定数量的属性进行分裂的,并不是对所有属性进行考量,按照这种思路,其中不同的决策树就拥有了对样本中某些属性强有力判断的能力,相当于每一颗决策树就是一个精通某些特定领域的专家,所有这些专家组合起来形成“强分类器”对样本进行投票。
以下是Opencv实现的随机森林样本训练、测试的简单说明程序:
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
double trainingData[28][2]={{210.4, 3}, {240.0, 3}, {300.0, 4}, {153.4, 3}, {138.0, 3},
{194.0,4}, {189.0, 3}, {126.8, 3}, {132.0, 2}, {260.9, 4},
{176.7,3}, {160.4, 3}, {389.0, 3}, {145.8, 3}, {160.0, 3},
{141.6,2}, {198.5, 4}, {142.7, 3}, {149.4, 3}, {200.0, 3},
{447.8,5}, {230.0, 4}, {123.6, 3}, {303.1, 4}, {188.8, 2},
{196.2,4}, {110.0, 3}, {252.6, 3} };
CvMat trainingDataCvMat = cvMat( 28, 2, CV_32FC1, trainingData );
float responses[28] = { 399900, 369000, 539900, 314900, 212000, 239999, 329999,
259900, 299900, 499998, 252900, 242900, 573900, 464500,
329900, 232000, 299900, 198999, 242500, 347000, 699900,
449900, 199900, 599000, 255000, 259900, 249900, 469000};
CvMat responsesCvMat = cvMat( 28, 1, CV_32FC1, responses );
CvRTParams params= CvRTParams(10, 2, 0, false,16, 0, true, 0, 100, 0, CV_TERMCRIT_ITER );
CvERTrees etrees;
etrees.train(&trainingDataCvMat, CV_ROW_SAMPLE, &responsesCvMat,
NULL, NULL, NULL, NULL,params);
double sampleData[2]={201.5, 3};
Mat sampleMat(2, 1, CV_32FC1, sampleData);
float r = etrees.predict(sampleMat);
cout<<endl<<"result: "<<r<<endl;
return 0;
} 













 4141
4141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









