








最近终于新采购的硬件性能评测做完了!!!
本次硬件性能测评的操作系统是Linux Ubuntu 14.04,主要从基础测试和专业深度学习框架测试两方面进行的测试。
基础测试用Phoronix Test Suite套件对新采购硬件系统进行了GPU、memory、CPU和IO的测试,并将测试结果上传到OpenBenchmarking.org网站,然后与旧的硬件系统的测试结果以及别人测试结果进行对比。从测试对比结果来看,我们新采购的系统性能处于不错的水平。
专业深度学习框架测试包括caffe和MXnet两个框架。本次主要介绍MXnet相关的测试。
MXnet是一个开源的深度学习计算平台,它是DMLC分布式机器学习通用工具包的重要部分。MXnet的优点是,轻量化、可移植性高、也可轻松扩展到多个GPU和多台机器,并且高效利用显存,同时速度比Caffe快,占用内存也比Caffe小,IO要求也比Caffe低。MXnet 最近被亚马逊AWS 选为官方深度学习平台。
将测试多GPU和单GPU在MXnet的性能表现。
硬件配置:
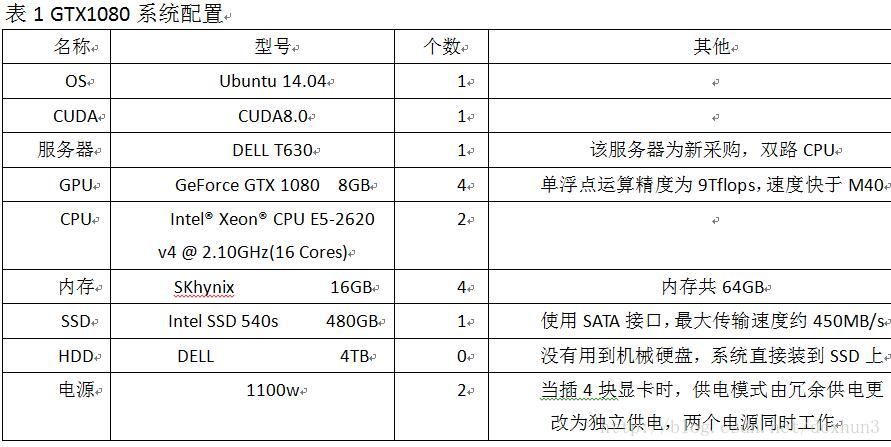
1 准备工作
准备工作需要做好3点:
1)MXnet框架的配置
MXnet的下载、安装参见:http://mxnet.io/get_started/setup.html 。
2) 训练网络的选择
训练网络是Cifar10 example 所用网络(symbol-inception-bn-28-smalle)和VGG16网络。
VGG16正如其名,是一个比较深的16层网络,训练时消耗显存多。该网络主要是为了测试显存大的Tesla M40、M6000与GTX1080的性能区别(表2)。
3) 训练数据的准备
训练数据选了两组:
训练数据1—Cifar10数据用于Cifar10 example,由60000张32*32的RGB彩色图片构成,共10个分类。50000张训练,10000张测试;
训练数据2—与caffe所用训练数据一样,也是12分类、大小约13.5GB的.jpg图像,经转换为MXnet格式的rec数据后,仅为15GB,这是MXnet轻量化的一个体现。
训练数据2用于VGG16的测试,VGG16。
接下来分别针对两组数据及对应的网络进行测试。
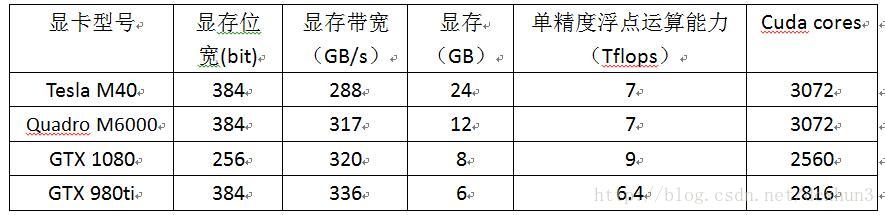
表2 不同显卡的相关参数
2 开始训练
2.1Cifar10的测试
MXnet自带cifar10 example,数据的下载、格式转换以及训练都自动进行,仅需执行下面的命令:
~/mxnet/example/image-classification# python train_cifar10.py –batch-size 128 –gpus 0,1,2,3
该命令的后面两个参数分别是指定batch-size的大小和gpu的id。通过调整这个两个参数,使得多GPU时每个GPU的负载量与单GPU的负载量相同,对比多GPU与单GPU完成cifar10 example测试的性能(图1)。从图1可以看出,当同负载时,完成同一个任务,多GPU相对单GPU的加速几乎接近成倍关系。
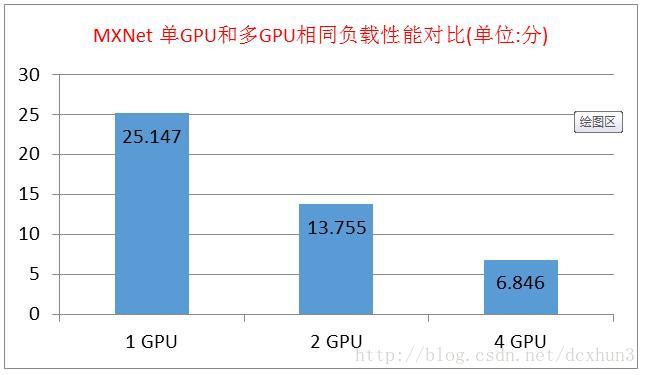
图1 MXNet 单GPU和多GPU相同负载性能对比
2.2 VGG16网络测试
VGG16网络主要是为了测试Tesla M40、M6000、GTX1080及GTX980ti的性能区别。这4种不同型号的显卡的相关参数见表3。由表3可以看出,M40和M6000的显存都相对GTX1080的显存大很多,但是显存带宽和单精度浮点运算能力没有GTX1080的高。因此我们选择4.2.1小节的训练数据2和VGG16测试这几种显卡的性能。
在测试的过程中,我们分别进行了batch_size=32和batch_size=32的两种情况的测试,测试对比结果见图2。从图2可以看出M40的性能反而最差,双GTX1080的性能比M40好很多;同时随着batch_size的增大,单1080则出现显存不足,需要多GTX1080并行计算。出现这样的测试结果,可以说明在显存容量合适的情况下,显存带宽和单精度浮点运算能力对GPU的计算速度影响非常大。
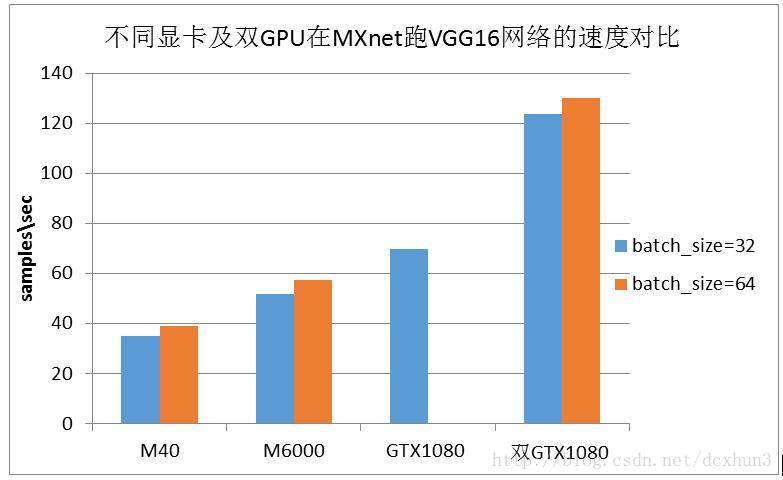
图2 不同显卡及双GPU的速度对比
由于GTX980ti的显存太小,无法测试VGG16网络。为了对比GTX980ti和其他型号的显卡在测试相对小的网络和数据的性能,我们选择cifar10进行测试对比,对比结果见图3。从图3可以看出,在小网络和小数据的情况下,GTX980ti的性能表现与GTX1080的性能表现不差上下,好于M40和M6000。
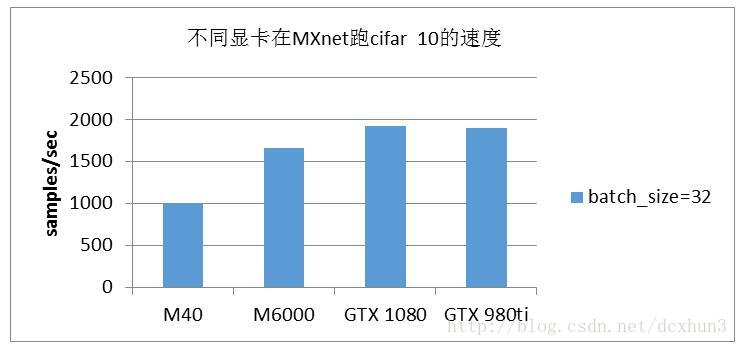
图3 不同显卡在MXnet跑cifar 10的速度对比
2.3分析IO和Memory
在GTX1080上测试VGG16网络时,打开NMON监视器,结束训练后打开监视结果(图4、图5),从图4和图5可以看出,MXnet即使在训练大网络时对IO和Memory的需求很小,与MXnet的官网描述是一致的(轻量化、可移植性高、也可轻松扩展到多个GPU和多台机器,并且高效利用显存)。
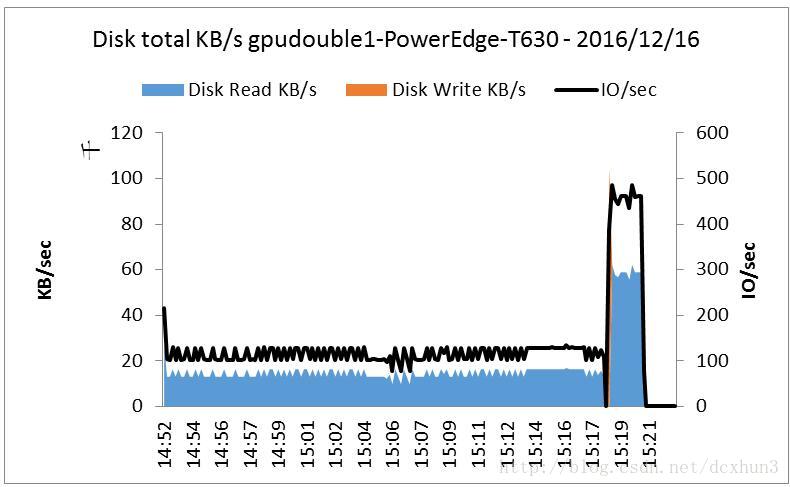
图4nmon监视IO的使用情况
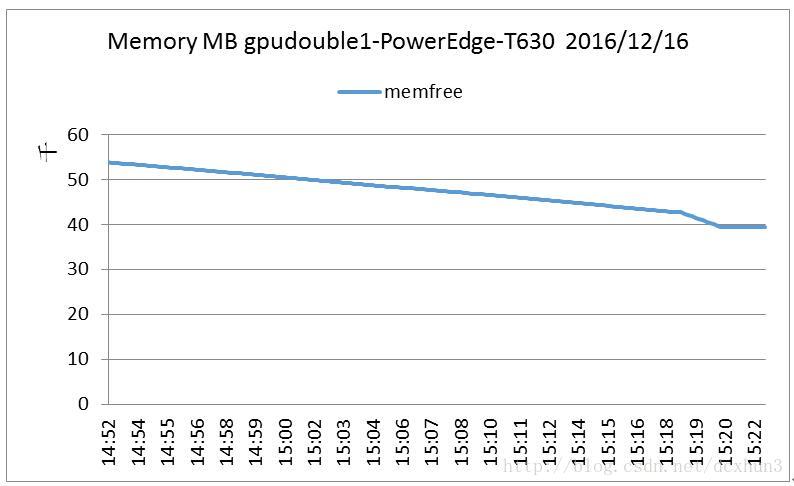
图5 nmon监视memory的使用情况
3小结
通过在MXnet框架的测试,得出以下结论:
1) 验证了在MXnet框架下,多GPU相对单GPU可以达到成倍的加速关系;
2) 同时M40、M6000在VGG16网络和cifar example的表现都不如GTX1080的表现,但随着batch_size的增大,单GTX1080会出现显存不足问题,用双GPU并行可以解决。
3) MXnet对IO和Memory的需求很小,即使数据在单块SSD中,也不会出现IO瓶颈问题。速度比Caffe快,占用内存也比Caffe小,IO要求也比Caffe低。














 7754
7754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









