







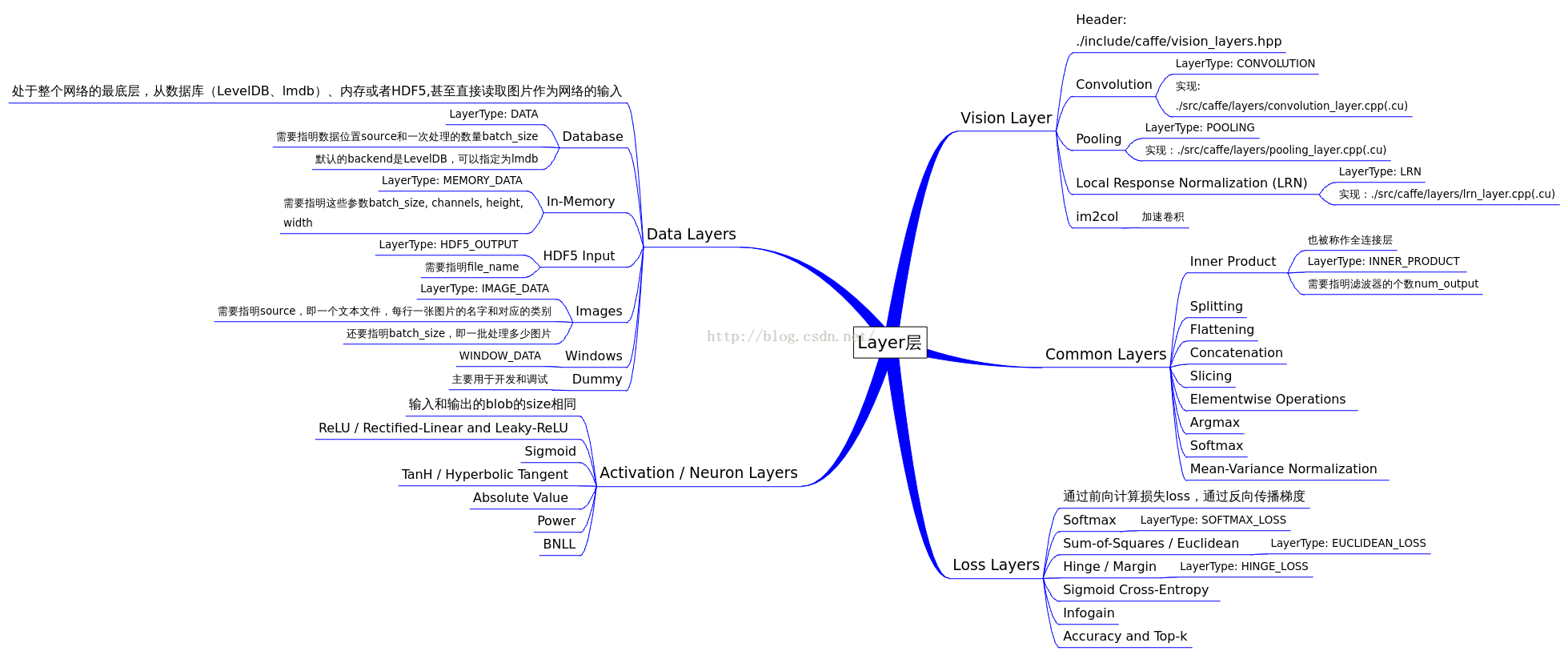
- 要想创建一个Caffe模型,需要在prototxt中定义一个model architecture(模型架构)。
- Caffe自带的Layer及其参数被定义在caffe.proto中。
Vision Layers
- 头文件: ./include/caffe/vision_layers.hpp
Vision layers 通常以图片images作为输入,运算后产生输出的也是图片images。对于图片而言,可能是单通道的(c=1),例如灰度图,或者三通道的 (c=3),例如RGB图。但是,对于Vision layers而言,最重要的特性是输入的spatial structure(空间结构)。2D的几何形状有助于输入处理,大部分的Vision layers工作是对于输入图片中的某一个区域做一个特定的处理,产生一个相应的输出。与此相反,其他大部分的layers会忽略输入的空间结构,而只是将输入视为一个很大的向量,维度为: c*h*w。
Convolution
- 类型(type):Convolution(卷积层)
- CPU 实现: ./src/caffe/layers/convolution_layer.cpp
- CUDA、GPU实现: ./src/caffe/layers/convolution_layer.cu
- 参数 (convolution_param):
- 必要:
- num_output (c_o): the number of filters(滤波器数目)
- kernel_size (or kernel_h and kernel_w): specifies height and width of each filter(每一个滤波器的大小)
- 强烈推荐:
- weight_filler [default type: ‘constant’ value: 0](滤波器权重,默认为0)
-
可选:
- bias_term [default true]: specifies whether to learn and apply a set of additive biases to the filter outputs(是否添加bias-偏置项,默认为True)
- pad (or pad_h and pad_w) [default 0]: specifies the number of pixels to (implicitly) add to each side of the input(为输入添加边界的像素大小,默认为0)
- stride (or stride_h and stride_w) [default 1]: specifies the intervals at which to apply the filters to the input(每一次使用滤波器处理输入图片时,前后两次处理区域的间隔,即“步进”,默认为1)
- group (g) [default 1]: If g > 1, we restrict the connectivity of each filter to a subset of the input. Specifically, the input and output channels are separated into g groups, and the ith output group channels will be only connected to the ith input group channels.(默认为1,如果大于1:将限制每一个滤波器只与输入的一部分连接。输入、输出通道会被分隔为不同的g个groups,并且第i个输出group只会与第i个输出group相关)
-
输入(Input)
- n * c_i * h_i * w_i
- 输出(Output)
-
n * c_o * h_o * w_o,其中h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1;w_o类似
-
例子(详见 ./examples/imagenet/imagenet_train_val.prototxt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
卷积层(The Convolution layer)利用一系列具有学习功能的滤波器(learnable filters)对输入的图像进行卷积操作,每一个滤波器(filter)对于一个特征(feature )会产生一个输出图像(output image)。
Pooling
- 类型(type):Pooling(池化层)
- CPU 实现: ./src/caffe/layers/pooling_layer.cpp
- CUDA、GPU实现: ./src/caffe/layers/pooling_layer.cu
-
参数 (pooling_param):
- 必要:
- kernel_size (or kernel_h and kernel_w): specifies height and width of each filter(每一个滤波器的大小)
- 可选:
- pool [default MAX]: the pooling method. Currently MAX, AVE, or STOCHASTIC(pooling方法,目前有MAX、AVE,和STOCHASTIC三种,默认为MAX)
- pad (or pad_h and pad_w) [default 0]: specifies the number of pixels to (implicitly) add to each side of the input(为输入添加边界的像素大小,默认为0)
- stride (or stride_h and stride_w) [default 1]: specifies the intervals at which to apply the filters to the input(每一次使用滤波器处理输入图片时,前后两次处理区域的间隔,即“步进”,默认为1)
- 必要:
-
输入(Input)
- n * c_i * h_i * w_i
-
输出(Output)
- n * c_o * h_o * w_o,其中h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1;w_o类似
-
例子(详见 ./examples/imagenet/imagenet_train_val.prototxt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Local Response Normalization (LRN)
- 类型(type):LRN(局部响应归一化层)
- CPU 实现: ./src/caffe/layers/lrn_layer.cpp
- CUDA、GPU实现: ./src/caffe/layers/lrn_layer.cu
- 参数 (lrn_param):
- 可选:
- local_size [default 5]: the number of channels to sum over (for cross channel LRN) or the side length of the square region to sum over (for within channel LRN)(对于cross channel LRN,表示需要求和的channel的数量;对于within channel LRN表示需要求和的空间区域的边长;默认为5)
- alpha [default 1]: the scaling parameter(缩放参数,默认为1)
- beta [default 5]: the exponent(指数,默认为5)
- norm_region [default ACROSS_CHANNELS]: whether to sum over adjacent channels (ACROSS_CHANNELS) or nearby spatial locaitons (WITHIN_CHANNEL)(选择基准区域,是ACROSS_CHANNELS => 相邻channels,还是WITHIN_CHANNEL => 同一 channel下的相邻空间区域;默认为ACROSS_CHANNELS)
- 可选:
LRN Layer对一个局部的输入区域进行归一化,有两种模式。ACROSS_CHANNELS模式,局部区域在相邻的channels之间拓展,不进行空间拓展,所以维度是local_size x 1 x 1。WITHIN_CHANNEL模式,局部区域进行空间拓展,但是是在不同的channels中,所以维度是1 x local_size x local_size。对于每一个输入,都要除以: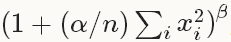
im2col
Im2col 是一个helper方法,用于将图片文件image转化为列矩阵,详细的细节不需要过多的了解。在Caffe中进行卷积操作,做矩阵乘法时,会用到Im2col方法。
Loss Layers
Caffe是通过最小化输出output与目标target之间的cost(loss)来驱动学习的。loss是由forward pass计算得出的,loss的gradient 是由backward pass计算得出的。
Softmax
- 类型(type):SoftmaxWithLoss(广义线性回归分析损失层)
Softmax Loss Layer计算的是输入的多项式回归损失(multinomial logistic loss of the softmax of its inputs)。可以当作是将一个softmax layer和一个multinomial logistic loss layer连接起来,但是计算出的gradient更可靠。
Sum-of-Squares / Euclidean
- 类型(type):EuclideanLoss(欧式损失层)
Euclidean loss layer计算两个不同输入之间的平方差之和,
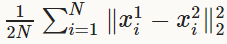
Hinge / Margin
- 类型(type):HingeLoss
- CPU 实现: ./src/caffe/layers/hinge_loss_layer.cpp
- CUDA、GPU实现: 尚无
-
参数 (hinge_loss_param):
- 可选:
- norm [default L1]: the norm used. Currently L1, L2(可以选择使用L1范数或者L2范数;默认为L1)
- 可选:
-
输入(Input)
- n * c * h * w Predictions(预测值)
- n * 1 * 1 * 1 Labels(标签值)
-
输出(Output)
- 1 * 1 * 1 * 1 Computed Loss(计算得出的loss值)
-
例子
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 关于范数:

Sigmoid Cross-Entropy
- 类型(type):SigmoidCrossEntropyLoss
- (没有详解)
Infogain
- 类型(type):InfogainLoss
- (没有详解)
Accuracy and Top-k
- 类型(type):Accuracy
- 计算输出的准确率(相对于target),事实上这不是一个loss layer,并且也没有backward pass。
Activation / Neuron Layers
激励层的操作都是element-wise的操作(针对每一个输入blob产生一个相同大小的输出):
- 输入(Input)
- n * c * h * w
- 输出(Output)
- n * c * h * w
ReLU / Rectified-Linear and Leaky-ReLU
- 类型(type):ReLU
- CPU 实现: ./src/caffe/layers/relu_layer.cpp
- CUDA、GPU实现: ./src/caffe/layers/relu_layer.cu
-
参数 (relu_param):
- 可选:
- negative_slope [default 0]: specifies whether to leak the negative part by multiplying it with the slope value rather than setting it to 0.(但当输入x小于0时,指定输出为negative_slope * x;默认值为0)
- 可选:
-
例子(详见 ./examples/imagenet/imagenet_train_val.prototxt)
- 1
- 2
- 3
- 4
- 5
- 6
给定一个输入值x,ReLU layer的输出为:x > 0 ? x : negative_slope * x,如未给定参数negative_slope 的值,则为标准ReLU方法:max(x, 0)。ReLU layer支持in-place计算,输出会覆盖输入,以节省内存空间。
Sigmoid
- 类型(type):Sigmoid
- CPU 实现: ./src/caffe/layers/sigmoid_layer.cpp
-
CUDA、GPU实现: ./src/caffe/layers/sigmoid_layer.cu
-
例子(详见 ./examples/mnist/mnist_autoencoder.prototxt)
- 1
- 2
- 3
- 4
- 5
- 6
对于每一个输入值x,Sigmoid layer的输出为sigmoid(x)。
TanH / Hyperbolic Tangent
- 类型(type):TanH
- CPU 实现: ./src/caffe/layers/tanh_layer.cpp
-
CUDA、GPU实现: ./src/caffe/layers/tanh_layer.cu
-
例子
- 1
- 2
- 3
- 4
- 5
- 6
对于每一个输入值x,TanH layer的输出为tanh(x)。
Absolute Value
- 类型(type):AbsVal
- CPU 实现: ./src/caffe/layers/absval_layer.cpp
-
CUDA、GPU实现: ./src/caffe/layers/absval_layer.cu
-
例子
- 1
- 2
- 3
- 4
- 5
- 6
对于每一个输入值x,AbsVal layer的输出为abs(x)。
Power
- 类型(type):Power
- CPU 实现: ./src/caffe/layers/power_layer.cpp
- CUDA、GPU实现: ./src/caffe/layers/power_layer.cu
-
参数 (power_param):
- 可选:
- power [default 1](指数,默认为1)
- scale [default 1](比例,默认为1)
- shift [default 0](偏移,默认为0)
- 可选:
-
例子
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对于每一个输入值x,Power layer的输出为(shift + scale * x) ^ power。
BNLL
- 类型(type):BNLL(二项正态对数似然,binomial normal log likelihood)
- CPU 实现: ./src/caffe/layers/bnll_layer.cpp
- CUDA、GPU实现: ./src/caffe/layers/bnll_layer.cu
- 例子
- 1
- 2
- 3
- 4
- 5
- 6
对于每一个输入值x,BNLL layer的输出为log(1 + exp(x))。
Data Layers
Data 通过Data Layers进入Caffe,Data Layers位于Net的底部。
Data 可以来自:1、高效的数据库(LevelDB 或 LMDB);2、内存;3、HDF5或image文件(效率低)。
基本的输入预处理(例如:减去均值,缩放,随机裁剪,镜像处理)可以通过指定TransformationParameter达到。
Database
- 类型(type):Data(数据库)
- 参数:
- 必要:
- source: the name of the directory containing the database(数据库名称)
- batch_size: the number of inputs to process at one time(每次处理的输入的数据量)
- 可选:
- rand_skip: skip up to this number of inputs at the beginning; useful for asynchronous sgd(在开始的时候跳过这个数值量的输入;这对于异步随机梯度下降是非常有用的)
- backend [default LEVELDB]: choose whether to use a LEVELDB or LMDB(选择使用LEVELDB 数据库还是LMDB数据库,默认为LEVELDB)
- 必要:
In-Memory
- 类型(type):MemoryData
- 参数:
- 必要:
- batch_size, channels, height, width: specify the size of input chunks to read from memory(4个值,确定每次读取输入数据量的大小)
- 必要:
Memory Data Layer从内存直接读取数据(而不是复制数据)。使用Memory Data Layer之前,必须先调用,MemoryDataLayer::Reset(C++方法)或Net.set_input_arrays(Python方法)以指定一个source来读取一个连续的数据块(4D,按行排列),每次读取大小由batch_size决定。
HDF5 Input
- 类型(type):HDF5Data
- 参数:
- 必要:
- source: the name of the file to read from(读取的文件的名称)
- batch_size(每次处理的输入的数据量)
- 必要:
HDF5 Output
- 类型(type):HDF5Output
-
参数:
- 必要:
- file_name: name of file to write to(写入的文件的名称)
HDF5 output layer与这部分的其他layer的功能正好相反,不是读取而是写入。
- 必要:
Images
- 类型(type):ImageData
- 参数:
- 必要:
- source: name of a text file, with each line giving an image filename and label(一个text文件的名称,每一行指定一个image文件名和label)
- batch_size: number of images to batch together(每次处理的image的数据)
- 可选:
- rand_skip: (在开始的时候跳过这个数值量的输入)
- shuffle [default false](是否随机乱序,默认为否)
-new_height, new_width: if provided, resize all images to this size(缩放所有的image到新的大小)
- 必要:
Windows
- 类型(type):WindowData
- (没有详解)
Dummy
- 类型(type):DummyData
DummyData 用于开发和测试,详见DummyDataParameter(没有给出链接)。
Common Layers
Inner Product
- 类型(type):Inner Product(全连接层)
- CPU 实现: ./src/caffe/layers/inner_product_layer.cpp
- CUDA、GPU实现: ./src/caffe/layers/inner_product_layer.cu
-
参数 (inner_product_param):
- 必要:
- num_output (c_o): the number of filters(滤波器数目)
- 强烈推荐:
- weight_filler [default type: ‘constant’ value: 0](滤波器权重;默认类型为constant,默认值为0)
- 可选:
- bias_filler [default type: ‘constant’ value: 0](bias-偏置项的值,默认类型为constant,默认值为0)
- bias_term [default true]: specifies whether to learn and apply a set of additive biases to the filter outputs(是否添加bias-偏置项,默认为True)
- 必要:
-
输入(Input)
- n * c_i * h_i * w_i
-
输出(Output)
- n * c_o * 1 * 1
-
例子
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
InnerProduct layer(常被称为全连接层)将输入视为一个vector,输出也是一个vector(height和width被设为1)
Splitting
- 类型(type):Split
Split layer用于将一个输入的blob分离成多个输出的blob。这用于当需要将一个blob输入至多个输出layer时。
Flattening
- 类型(type):Flatten
Flatten layer用于把一个维度为n * c * h * w的输入转化为一个维度为 n * (c*h*w)的向量输出。
Reshape
- 类型(type):Reshape
- CPU 实现: ./src/caffe/layers/reshape_layer.cpp
- CUDA、GPU实现: 尚无
-
参数 (reshape_param):
- 可选:
- shape(改变后的维度,详见下面解释)
- 可选:
-
输入(Input)
- a single blob with arbitrary dimensions(一个任意维度的blob)
-
输出(Output)
- the same blob, with modified dimensions, as specified by reshape_param(相同内容的blob,但维度根据reshape_param改变)
-
例子
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Reshape layer只改变输入数据的维度,但内容不变,也没有数据复制的过程,与Flatten layer类似。
输出维度由reshape_param 指定,正整数直接指定维度大小,下面两个特殊的值:
- 0 => 表示copy the respective dimension of the bottom layer,复制输入相应维度的值。
- -1 => 表示infer this from the other dimensions,根据其他维度自动推测维度大小。reshape_param中至多只能有一个-1。
再举一个例子:如果指定reshape_param参数为:{ shape { dim: 0 dim: -1 } } ,那么输出和Flattening layer的输出是完全一样的。
Concatenation
- 类型(type):Concat(连结层)
- CPU 实现: ./src/caffe/layers/concat_layer.cpp
- CUDA、GPU实现: ./src/caffe/layers/concat_layer.cu
-
参数 (concat_param):
- 可选:
- axis [default 1]: 0 for concatenation along num and 1 for channels.(0代表连结num,1代表连结channel)
- 可选:
-
输入(Input)
-n_i * c_i * h * w for each input blob i from 1 to K.(第i个blob的维度是n_i * c_i * h * w,共K个) -
输出(Output)
- if axis = 0: (n_1 + n_2 + … + n_K) * c_1 * h * w, and all input c_i should be the same.(axis = 0时,输出 blob的维度为(n_1 + n_2 + … + n_K) * c_1 * h * w,要求所有的input的channel相同)
- if axis = 1: n_1 * (c_1 + c_2 + … + c_K) * h * w, and all input n_i should be the same.(axis = 0时,输出 blob的维度为n_1 * (c_1 + c_2 + … + c_K) * h * w,要求所有的input的num相同)
-
例子
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Concat layer用于把多个输入blob连结成一个输出blob。
Slicing
Slice layer用于将一个input layer分割成多个output layers,根据给定的维度(目前只能指定num或者channel)。
- 类型(type):Slice
- 例子
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
axis表明是哪一个维度,slice_point是该维度的索引,slice_point的数量必须是top blobs的数量减1.
Elementwise Operations
- 类型(type): Eltwise
- (没有详解)
Argmax
- 类型(type):ArgMax
- (没有详解)
Softmax
- 类型(type):Softmax
- (没有详解)
Mean-Variance Normalization
- 类型(type):MVN
- (没有详解)














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









