







数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
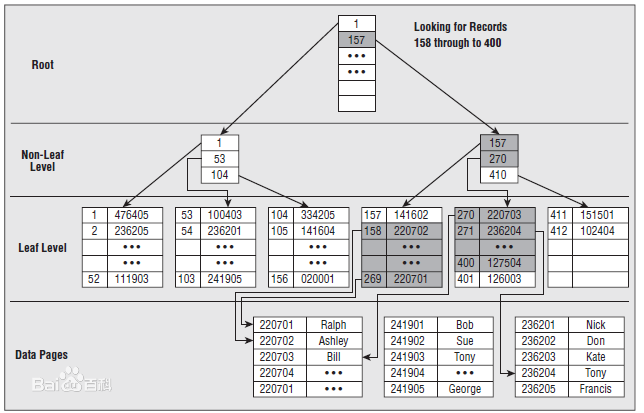
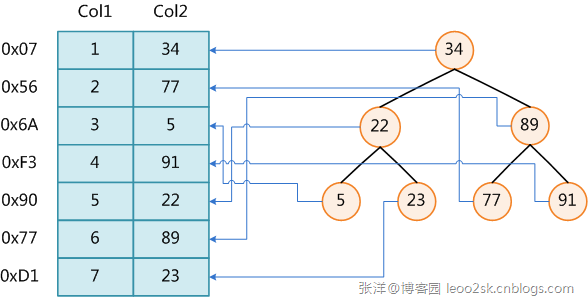
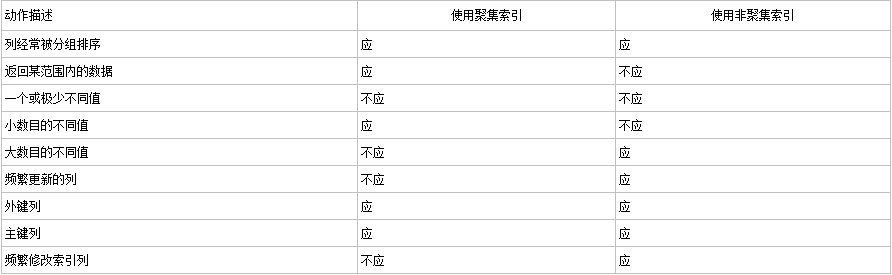
创建索引可以大大提高系统的性能
1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
2. 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
3. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
4. 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
5. 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
增加索引也有许多不利的方面
1. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
3. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
数据库索引类型
逻辑上:
Single column 单行索引
Concatenated 多行索引
Unique 唯一索引
NonUnique 非唯一索引
Function-based函数索引
Domain 域索引
物理上:
Partitioned 分区索引
NonPartitioned 非分区索引
B-tree:
Normal 正常型B树
Rever Key 反转型B树
Bitmap 位图索引
聚集索引结构
在 SQL Server 中,索引是按 B 树结构进行组织的。聚集索引单个分区中的结构:
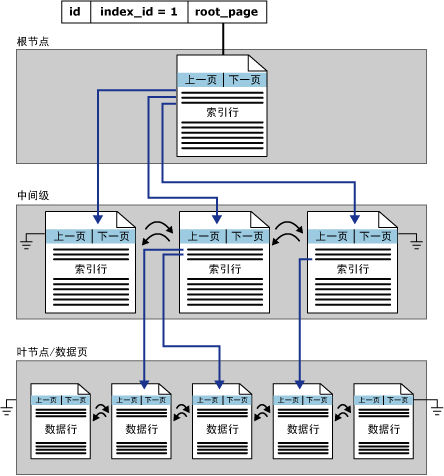
聚集索引(Clustered Index)特点
1. 聚集索引的叶节点就是实际的数据页
2. 聚集索引中的排序顺序仅仅表示数据页链在逻辑上是有序的。而不是按照顺序物理的存储在磁盘上
3. 行的物理位置和行在索引中的位置是相同的
4. 每个表只能有一个聚集索引
5. 聚集索引的平均大小大约为表大小的5%左右
非聚集索引结构
非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点:
1. 基础表的数据行不按非聚集键的顺序排序和存储。
2. 非聚集索引的叶层是由索引页而不是由数据页组成。
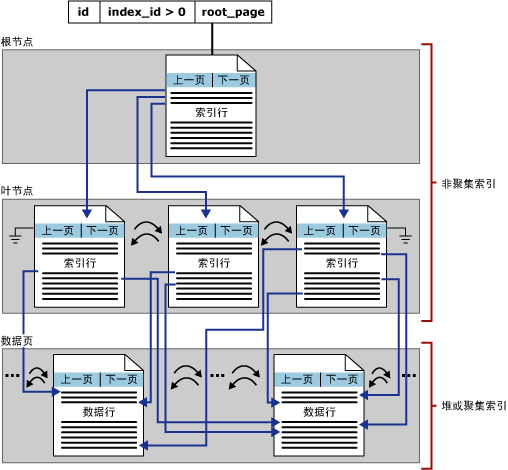
我们有一本汉语字典,可以把它的正文本身看做是一个聚集索引,它是按照汉字拼音的开头字母排序的,不再需要查找其他目录。当遇到不认识的字时,需要结合“部首目录”和“检字表”, 先找到目录中的结果,然后再翻到您所需要的页码。通过这种方法查到的目录中字的排序并不是真正的正文的排序方法。把这种看做是一个非聚集索引。
非聚集索引 (Unclustered Index) 特点
1. 非聚集索引的页,不是数据,而是指向数据页的页。
2. 若未指定索引类型,则默认为非聚集索引。
3. 叶节点页的次序和表的物理存储次序不同
4. 每个表最多可以有249个非聚集索引
5. 在非聚集索引创建之前创建聚集索引(否则会引发索引重建)
使用索引的代价
1. 索引需要占用数据表以外的物理存储空间
2. 创建索引和维护索引要花费一定的时间
3. 当对表进行更新操作时,索引需要被重建,这样降低了数据的维护速度。
实例
use studentsDB
set statistics io on
set statistics time on
USE studentsDB
SELECT * FROM emp_pay where employeeID=5
扫描计数 1,逻辑读取 1 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 无索引查询

索引查询
表 ‘emp_pay’。扫描计数 0,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
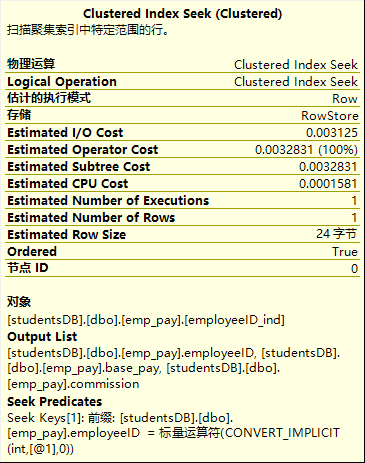
索引为一种特殊的目录。微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)。下面,我们举例来说明一下聚集索引和非聚集索引的区别:
其实,我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音 排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那 么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分 本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的 字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序 并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却 是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上 就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结 果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序。














 1471
1471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









