







目前HDFS上日志一部分由MR清洗生成&二次计算,一部分直接从服务器离线上传,但在私有云环境下,离线日志的压缩上传可能会对服务造成性能影响,而且在很多日志已经实时传输到Kafka集群的情况下,考虑Kafka->Hdfs也不失为一条合理的路径。
1. Kafka-Flume-Hdfs
这种方法直接通过Flume-ng的Hdfs-Sink往Hdfs导数据,Hdfs-Sink用来将数据写入Hadoop分布式文件系统(HDFS)中。支持创建text和sequence文件及这2种文件类型的压缩;支持文件周期性滚动(就是关闭当前文件在建立一个新的),滚动可以基于时间、数据大小、事件数量;也支持通过event hearder属性timestamp或host分割数据。HDFS目录路径或文件名支持格式化封装,相应的封装串在Hdfs-Sink生成目录或文件时被恰当的替换。使用HDFSSink需要首先安装hadoop,Hdfs-Sink是通过hadoop jar和HDFS集群通信的。注意Hadoop版本需要支持sync()。具体配置类似:
dataAgent.channels.kafka-piwikGlobal.kafka.producer.type=sync
dataAgent.channels.kafka-piwikGlobal.topic=app_piwik
dataAgent.channels.kafka-piwikGlobal.groupId=AutoCollect-piwikGlobal-1
dataAgent.channels.kafka-piwikGlobal.zookeeperConnect=192.168.1.10:2181,192.168.1.11:2181
dataAgent.channels.kafka-piwikGlobal.brokerList=192.168.1.10:9092,192.168.1.11:9092
dataAgent.channels.kafka-piwikGlobal.is_avro_event=false
dataAgent.channels.kafka-piwikGlobal.transactionCapacity=100000
dataAgent.channels.kafka-piwikGlobal.capacity=6000000
dataAgent.channels.kafka-piwikGlobal.type=org.apache.flume.channel.kafka.KafkaChannel
dataAgent.channels.kafka-piwikGlobal.parseAsFlumeEvent=false
dataAgent.sinks.hdfs-piwikGlobal.channel=kafka-piwikGlobal
dataAgent.sinks.hdfs-piwikGlobal.type=hdfs
#使用gzip压缩算法
dataAgent.sinks.hdfs-piwikGlobal.hdfs.codeC=gzip
dataAgent.sinks.hdfs-piwikGlobal.hdfs.fileType=CompressedStream
#日志保存路径,这里按小时存放
dataAgent.sinks.hdfs-piwikGlobal.hdfs.path=hdfs://argo/data/logs/autoCollect/piwikGlobal/%Y-%m-%d/%H
#文件前缀,也可以使用封装串
dataAgent.sinks.hdfs-piwikGlobal.hdfs.filePrefix=piwikGlobal
#不按时间滚动
dataAgent.sinks.hdfs-piwikGlobal.hdfs.rollInterval=0
#不根据文件大小滚动
dataAgent.sinks.hdfs-piwikGlobal.hdfs.rollSize=0
#按事件条数滚动
dataAgent.sinks.hdfs-piwikGlobal.hdfs.rollCount=1000000
#hadoop集群响应时间较长时需要配置
dataAgent.sinks.hdfs-piwikGlobal.hdfs.callTimeout=40000
#100秒后这个文件还没有被写入数据,就会关闭它然后去掉.tmp,后续的events会新开一个.tmp文件来接收
dataAgent.sinks.hdfs-piwikGlobal.hdfs.idleTimeout=100
dataAgent.sinks.hdfs-piwikGlobal.hdfs.useLocalTimeStamp=true
这种方式在日志量大的情况下,需要启动多个Hdfs-Sink或多个Flume进程,甚至需要部署在多台机器上,不好管理,并且在特定需求下,还需要做定制开发。
2.Kafka-Storm-Hdfs
这种方法通过storm往hdfs写数据,可以做定制开发,可以根据日志量调整并发度,上下线方便,可根据Storm REST Api做监控报警。
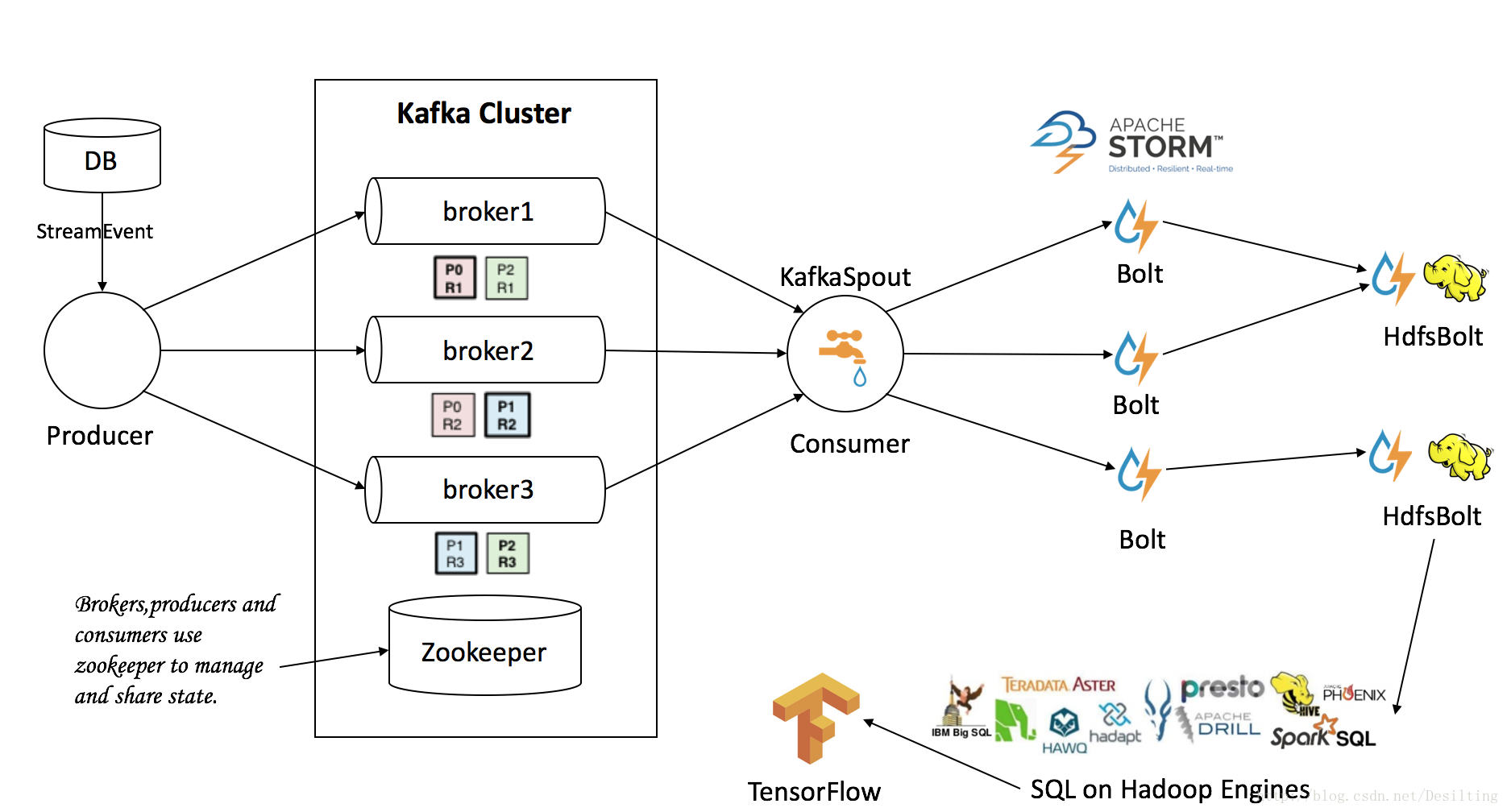
官方源码:https://github.com/apache/storm/tree/master/external/storm-hdfs
主要的类为HdfsBolt和SequenceFileBolt,都在org.apache.storm.hdfs.bolt包中。HdfsBolt用来写text数据, SequenceFileBolt用来写二进制数据。
HdfsBolt的配置参数:
1、RecordFormat:定义字段分隔符,你可以使用换行符\n或者制表符\t;
2、SyncPolicy:定义每次写入的tuple的数量;
3、FileRotationPolicy:定义写入的hdfs文件的轮转策略,你可以以时间轮转(TimedRotationPolicy)、大小轮转(FileSizeRotationPolicy)、不轮转(NoRotationPolicy);
4、FileNameFormat:定义写入文件的路径(withPath)和文件名的前后缀(withPrefix、withExtension);
5、withFsUrl:定义hdfs的地址。
示例:
RecordFormat format = new DelimitedRecordFormat().withFieldDelimiter("|");
SyncPolicy syncPolicy = new CountSyncPolicy(1000);
FileRotationPolicy rotationPolicy = new FileSizeRotationPolicy(5.0f, Units.MB);
FileNameFormat fileNameFormat = new DefaultFileNameFormat()
.withPath("/data/logs");
HdfsBolt bolt = new HdfsBolt()
.withFsUrl("hdfs://localhost:8020")
.withFileNameFormat(fileNameFormat)
.withRecordFormat(format)
.withRotationPolicy(rotationPolicy)
.withSyncPolicy(syncPolicy);
如果要连接开启了HA的Hadoop集群,可以改为withFsURL(“hdfs://nameserviceID”)。
nameserviceID可以在hdfs-site.xml中查到。
<property>
<name>dfs.nameservices</name>
<value>nameserviceID</value>
</property>
这里存在的问题是,一个线程只会写一个文件,不支持压缩存储,无法分目录,因此需要做一些修改。
1)Gzip压缩存储
this.fs = FileSystem.get(URI.create(this.fsUrl), hdfsConfig);
CompressionCodecFactory compressionCodecFactory = new CompressionCodecFactory(new Configuration());
CompressionCodec compressionCodec = compressionCodecFactory.getCodecByClassName("org.apache.hadoop.io.compress.GzipCodec");
FSDataOutputStream out = this.fs.create(new Path(parentPath, new Path(childStrPath)));
CompressionOutputStream compressionOutput = compressionCodec.createOutputStream(out, compressionCodec.createCompressor());
#写数据
compressionOutput.write(bulkStr.toString().getBytes());
Flush操作也需要做些修改,太过频繁会影响写入性能:
try {
compressionOutput.flush();
if (out instanceof HdfsDataOutputStream) {
((HdfsDataOutputStream) out).hsync(EnumSet.of(HdfsDataOutputStream.SyncFlag.UPDATE_LENGTH));
} else {
out.hsync();
}
} catch (IOException e) {
LOG.error("flush error:{}",e.getMessage());
}
如果worker异常终止,造成gzip文件非正常关闭,通过hdfs -text命令是可以正常查看的,但一般MR程序无法读取此类文件,指标不治本的方法,可以简单设置mapred.max.map.failures.percent来跳过异常文件,或者自己实现InputStream类。
2)分目录写入
比如对于接收到的每一条日志,需要解析时间或类型,按/type/day/hour的方式存储,这就会导致一个hdfsBolt线程需要打开多个不同目录下的文件进行写入。
#每个目录对应一个Path对象,以防重复创建
private Map<String, Path> parentPathObjMap = Maps.newHashMap();
#每个目录对应一个CompressionOutputStream对象,判断日志需要写入哪一个目录,则获取相应对象写入
private Map<String, CompressionOutputStream> pathToCompWriter = Maps.newHashMap();
#每个目录对应一个StringBuilder对象,积攒一批日志写入,以提高性能
private Map<String, StringBuilder> pathToCache = Maps.newHashMap();
#每个目录对应一个Long对象,判断积攒日志量是否满足写入阈值
private Map<String, Long> pathToCacheLineNum = Maps.newHashMap();
#每个目录对应一个文件轮转对象
private Map<String, FileRotationPolicy> fileRotationMap = Maps.newHashMap();
#每个目录写入的日志字节数,用来判断是否轮转
private Map<String, Long> offsetMap = Maps.newHashMap();
#每个目录上次写入的时间,超过一定时间没有数据写入,则关闭文件
private Map<String, Long> lastFlushTimeMap = Maps.newHashMap();
因为一个线程在一个目录下只会往一个文件写,因此这些Map的key值都为目录路径。
在程序运行过程本来将日志解析单独作为一个bolt,后来将其融入HdfsBolt,以配置正则表达式的方式,减少网络传输开销,来提高性能。














 3659
3659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









