






Memcached和Redis作为两种Inmemory的key-value数据库,在设计和思想方面有着很多共通的地方,功能和应用方面在很多场合下(作为分布式缓存服务器使用等)也很相似,在这里把两者放在一起做一下对比的介绍
Memcached
Memcached采用客户端-服务器的架构,客户端和服务器端的通讯使用自定义的协议标准,只要满足协议格式要求,客户端Library可以用任何语言实现。
从用户的角度来说,服务器维护了一个键-值关系的数据表,服务器之间相互独立,互相之间不共享数据也不做任何通讯操作。客户端需要知道所有的服务器,并自行负责管理数据在各个服务器间的分配。
在服务器端,内部的数据存储,使用基于Slab的内存管理方式,有利于减少内存碎片和频繁分配销毁内存所带来的开销。各个Slab按需动态分配一个page的内存(和4Kpage的概念不同,这里默认page为1M),page内部按照不同slab class的尺寸再划分为内存chunk供服务器存储KV键值对使用

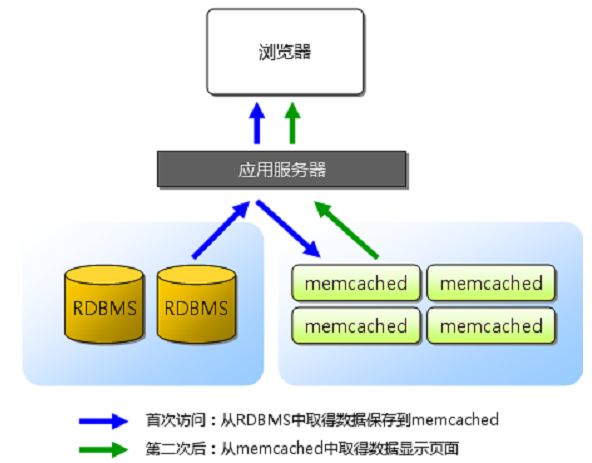
Memcached的基本应用模型如下图所示
Redis内部的数据结构最终也会落实到key-Value对应的形式,不过从暴露给用户的数据结构来看,要比memcached丰富,除了标准的通常意义的键值对,Redis还支持List,Set, Hashes,Sorted Set等数据结构。
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached。
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 Redis支持数据的备份,即master-slave模式的数据备份。
3 Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。Redis只会缓存所有的 key的信息,如果Redis发现内存的使用量超过了某一个阀值,将触发swap的操作,Redis根据“swappability = age*log(size_in_memory)”计算出哪些key对应的value需要swap到磁盘。然后再将这些key对应的value持久化到磁盘中,同时在内存中清除。
使用Redis特有内存模型前后的情况对比:
VM off: 300k keys, 4096 bytes values: 1.3G used
VM on: 300k keys, 4096 bytes values: 73M used
VM off: 1 million keys, 256 bytes values: 430.12M used
VM on: 1 million keys, 256 bytes values: 160.09M used
VM on: 1 million keys, values as large as you want, still: 160.09M used
当从Redis中读取数据的时候,如果读取的key对应的value不在内存中,那么Redis就需要从swap文件中加载相应数据,然后再返回给请求方。 所以Redis运行我们设置I/O线程池的大小,对需要从swap文件中加载相应数据的读取请求进行并发操作,减少阻塞的时间。
如果希望在海量数据的环境中使用好Redis,我相信理解Redis的内存设计和阻塞的情况是不可缺少的。
数据备份,有效性,持久化等
memcached不保证存储的数据的有效性,Slab内部基于LRU也会自动淘汰旧数据,客户端不能假设数据在服务器端的当前状态,这应该说是Memcached的Feature设定,用户不必太多关心或者自己管理数据的淘汰更新工作,当然是否适合你的应用,取决于具体的需求,它也可能成为你需要精确自行控制Cache生命周期的一个障碍
Memcached也不做数据的持久化工作,但是有许多基于memcached协议的项目实现了数据的持久化,例如memcacheDB使用BerkeleyDB进行数据存储,但本质上它已经不是一个Cache Server,而只是一个兼容Memcached的协议key-valueData Store了
Redis可以以master-slave的方式配置服务器,Slave节点对数据进行replica备份,Slave节点也可以充当Read only的节点分担数据读取的工作
Redis除了作为存储之外还提供了一些其它方面的功能,比如聚合计算、pubsub、scripting等,对于此类功能需要了解其实现原理,清楚地了解到它的局限性后,才能正确的使用,比如pubsub功能,这个实际是没有任何持久化支持的,消费方连接闪断或重连之间过来的消息是会全部丢失的,又比如聚合计算和scripting等功能受Redis单线程模型所限,是不可能达到很高的吞吐量的,需要谨慎使用。
总的来说Redis作者是一位非常勤奋的开发者,可以经常看到作者在尝试着各种不同的新鲜想法和思路,针对这些方面的功能就要求我们需要深入了解后再使用。
总结:
1.Redis使用最佳方式是全部数据in-memory。
2.Redis更多场景是作为Memcached的替代者来使用。
3.当需要除key/value之外的更多数据类型支持时,使用Redis更合适。
4.当存储的数据不能被剔除时,使用Redis更合适。














 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









