







笔者之前曾经写过一篇Sybase ASE在JDBC -Statement和PreparedStatement两种SQL执行方式下执行效率和监控指标的对比文章,本文沿用类似的方法,在Oracle 11gR2数据库中继续验证两种方式在SQL效率和数据库指标上的差异。
一、 Oracle SQL执行过程
借用《Pro OracleSQL》书中对Oracle中SQL语句执行过程的截图:
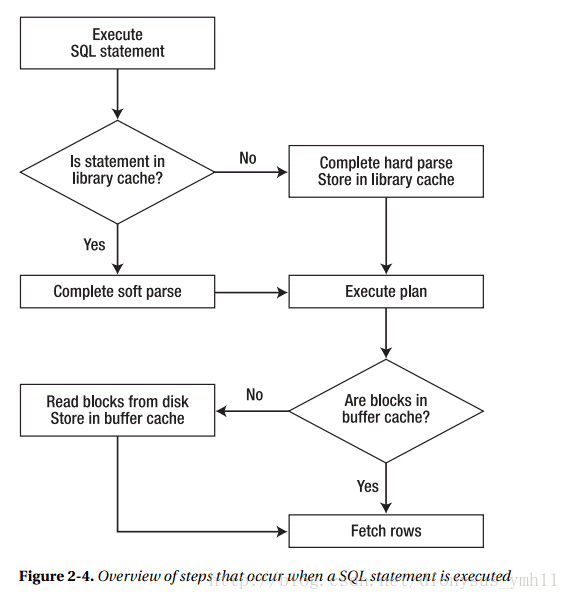
AskTom网站对hard parse、soft parse和fast parse(soft soft parse)的解释如下:
HARD parse -- the query has neverbeen seen before, isn't in the shared pool. We must parse it, hash it, look inthe shared pool for it, don't find it, security check it, optimize it, etc(lots of work).
SOFT parse -- the query has beenseen before, is in the shared poo. We have to parse it, hash it, look inthe shared pool for it and find it (less work then a hard parse but work nonethe less)
a kinder, softer SOFT parse -- youare using session_cached_cursors (search this site for that word forinfo). We take your query, look in the sessions cursor cache -- find thecursor and reuse it. Very very little work.
由此可见,一条SQL传入Oracle后,如果它从没有被执行过,则会经过语法、语义检查,分析并产生执行计划等多个步骤,耗时耗资源(hard parse);
如果这条SQL语句已经被执行过,则相应的执行计划已被缓存,Oracle仅经过语法、语义检查即可,这条SQL的执行计划可以在library cache中找到并直接使用;
如果Oracle设置了SESSION_CACHED_CURSORS,则SQL的执行计划在PGA的private sql area中还好保留副本,且直接被使用,较soft parse更快。本次实验同使用JDBC –Statement和PreparedStatement两种SQL执行方式对SQL解析进行验证。
试验中使用Oracle11gR2,创建一个多字段的表,插入50w条随机数据。与Oracle的JDBC连接访问使用LoadRunner Java Vuser协议调用Oracle提供的ojdbc6.jar驱动,SQL语句的提交通过LoadRunner的参数化尽量实现动态。压力场景采用10并发(进程模式)执行5分钟,Oracle AWR SnapShot采集场景执行1分钟和4分钟左右的结果。
二、 数据库环境
1. 数据库基本配置
l Oracle数据库相关配置参数如下:
l optimizer_features_enable:11.2.0.1
l optimizer_mode:ALL_ROWS
l CPU count:4
l memory_max_target:1232 MB
l memory_target:1232 MB
l sga_max_size:744 MB
l sga_target:0 MB(Oracle自动管理)
l session_cached_cursors:50
l open_cursors:300
l cursor_space_for_time:FALSE
l cursor_sharing:EXACT
2. 创建数据库表
CREATE TABLE HR.LOT_TEST
(
"LOT_DATE" INTEGER NOT NULL,
"RED_1" INTEGER NOTNULL,
"RED_2" INTEGER NOTNULL,
"RED_3" INTEGER NOTNULL,
"RED_4" INTEGER NOTNULL,
"RED_5" INTEGER NOT NULL,
"RED_6" INTEGER NOTNULL,
"BLUE" INTEGER NOTNULL
)
ORGANIZATION HEAP
TABLESPACE USERS
NOLOGGING
PCTFREE 10
PCTUSED 40
INITRANS 1
MAXTRANS 255
STORAGE(PCTINCREASE 0
BUFFER_POOL DEFAULT)
NOPARALLEL
CACHE
/
CREATE INDEX HR.IDX_LOT_BLUE
ON HR.LOT_TEST("BLUE")
TABLESPACE SYSTEM
PCTFREE 10
INITRANS 2
MAXTRANS 255
STORAGE(INITIAL 64K
PCTINCREASE 0
BUFFER_POOL DEFAULT)
NOPARALLEL
NOCOMPRESS
/
ALTER TABLE HR.LOT_TEST
ADD CONSTRAINT PK_LOT_DATE
PRIMARY KEY ("LOT_DATE")
USING INDEX TABLESPACE SYSTEM
PCTFREE 10
INITRANS 2
MAXTRANS 255
STORAGE(PCTINCREASE 0
BUFFER_POOL DEFAULT)
ENABLE
VALIDATE
/
3. 创建SEQUENCE,用以向字段LOT_DATE中插入自增值
CREATE SEQUENCE HR.S_LOT_DATE
START WITH 1
INCREMENT BY 1
NOMINVALUE
NOMAXVALUE
NOCYCLE
CACHE 20
NOORDER
/
4. 创建插入随机数据的存储过程
CREATE OR REPLACE PROCEDUREHR.PROC_LOT_INSERT
AS
I INT;
BEGIN
I:=1;
WHILE I<50000 LOOP
INSERT INTO HR.LOT_TESTVALUES(HR.S_LOT_DATE.NEXTVAL,DBMS_RANDOM.VALUE(1,50000),DBMS_RANDOM.VALUE(1,50000),DBMS_RANDOM.VALUE(1,10000),DBMS_RANDOM.VALUE(1,10000),DBMS_RANDOM.VALUE(1,5000),DBMS_RANDOM.VALUE(1,5000),DBMS_RANDOM.VALUE(1,50));
I:=I+1;
END LOOP;
COMMIT;
END;
插入50w条记录,其中个字段随机取值的范围不同。
三、 LoadRunner JDBC脚本
编写LoadRunner JDBC连接Oracle的脚本,Run-time settings的Classpath中加入Oracle 11gR2提供的JDBC包(本例中使用的是ojdbc6.jar),同时在本机安装1.6的JVM。查询LOT_TEST表中的列,对查询列的值进行随机参数化。
1. Statement方式
LoadRunner脚本暂略,如有需要请和我联系。
2. PreparedStatement方式
LoadRunner脚本暂略,如有需要请和我联系。四、 测试结果–限制迭代间隔
第一个测试场景限制了LoadRunnerAction的迭代间隔,在相同TPS下观察Oracle AWR中关于解析方面的各指标值,设置10VUsers,执行5分钟,脚本pacing为fixed 1秒。
场景执行到1分钟左右时手工生成第一个Oracle SnapShot,4分钟左右生成第二个SnapShot,AWR取两个SnapShot之间的结果:
1. JDBC Statement
| 测试项 |
VUser数量 |
测试执行时间 |
Query平均TPS |
Query平均响应时间 |
| Statement |
10 |
5 |
10 |
0.013 |
| Update平均TPS |
Update平均响应时间 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









