







from http://blog.csdn.net/qustqustjay/article/details/49507047
1、搭建好Hadoop环境,包括JDK的安装、Hadoop的安装及文件配置、SSH通信的配置、eclipse Java开发环境的配置(具体安装见最后附件Hadoop安装配置)。
2、本环境配置是在ubuntu下建立了三台虚拟机,一台为master,另两台为slave。打开三台虚拟机,在master上启动Hadoop:
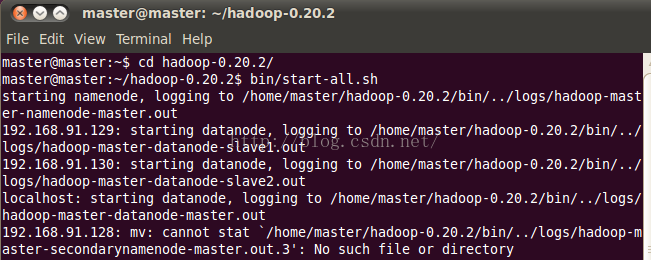
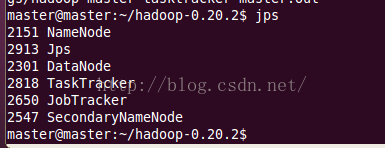
使用jps命令查看结点启动情况,如下表明Hadoop启动成功:
3、打开eclipse,建立工程并配置Hadoop运行(具体安装见最后附件Hadoop安装配置),编程界面如下:
4、MapReduce下分布并行实现多个数相加的程序,代码及详细解释如下:
import java.io.IOException; //异常包
import java.util.StringTokenizer; //分隔字符串,默认用空格来分隔
import org.apache.hadoop.conf.Configured; //任务配置包,配置任务所需的map等函数
import org.apache.hadoop.fs.Path; //设置文件路径
import org.apache.hadoop.io.IntWritable; //Hadoop的数据类型,类似Java中int
import org.apache.hadoop.io.LongWritable; //数据类型,类似Java中long
import org.apache.hadoop.io.Text; //hadoop的数据类型,类似Java中String
import org.apache.hadoop.mapreduce.Job; //控制整个作业运行
import org.apache.hadoop.mapreduce.Mapper; //map接口
import org.apache.hadoop.mapreduce.Reducer; //reduce接口
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; /定义输入路径
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; /定义输入路径
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /输出路径
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; /输出路径
import org.apache.hadoop.util.Tool; //会用到的工具包
import org.apache.hadoop.util.ToolRunner;
public class sumcount extends Configured implements Tool { 实现map函数
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
String line = value.toString(); //file01中的1 2 3等值,转换成string
StringTokenizer tokenizer = new StringTokenizer(line); //以空格为分隔符,分割出各个value
while(tokenizer.hasMoreElements()){//在while循环中,将每个value改写成Hadoop能够处理的(key,value)形式,如(0,1)、(1,2)、(0,3)......
String strSorce0 = tokenizer.nextToken(); //依此取每个value
context.write(new Text("0"), new IntWritable(Integer.parseInt(strSorce0))); //写成(key,value)形式
if(tokenizer.hasMoreElements())
{
String strSorce1 = tokenizer.nextToken();
context.write(new Text("1"), new IntWritable(Integer.parseInt(strSorce1))); //因为只配置了两台从属机器,所以我把奇数数字放到了slave1机器上去运行加法,把偶数数字放到了slave2机器上去运行加法,实际中可以根据key值自动分配,相同key值得肯定放到同一台机器上运行,同一机器上也可以放不同key值得value。
}
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { //实现reduce函数
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0; //运算结果,数字相加总和
for (IntWritable sorce : values) { //使用迭代器按key值依次取value值,并求和。
sum+=sorce.get();
}
context.write(new Text("sum="), new IntWritable((int)(sum)));//结果同样以(key,value)形式写回,如(sum=,25)、(sum=,20)
}
}
public int run(String[] arg0) throws Exception { //运行配置
Job job = new Job(getConf()); //实例化一道作业
job.setJobName("sumcount"); //设置任务名
job.setOutputKeyClass(Text.class); //设置该作业的输出key
job.setOutputValueClass(IntWritable.class);//设置该作业的输出value
job.setMapperClass(Map.class); //设置该作业的map类
job.setReducerClass(Reduce.class); //设置该作业的reduce类
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(arg0[0])); //设置该作业的输入路径
FileOutputFormat.setOutputPath(job, new Path(arg0[1])); //设置该作业的输出路径
boolean success = job.waitForCompletion(true);
return success ? 0 : 1;
}
public static void main(String[] args) throws Exception { //main函数中调用该配置好的作用
int ret = ToolRunner.run(new sumcount(), args);
System.exit(ret);
}
}
5、运行:
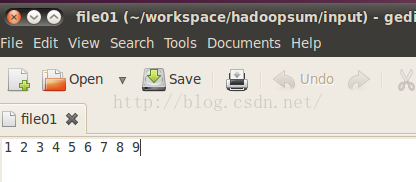
在工作目录下建立输入文件夹input,里面放入文件file01,该文件中是一系列数字,是用来做加法的:
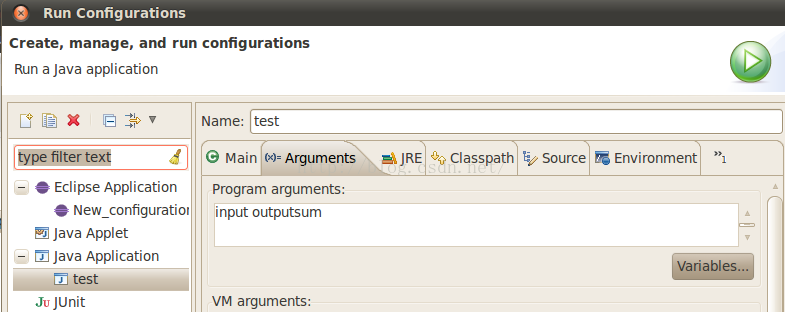
在工程上右键,打开Run Configuration运行配置对话框,填写输入文件夹input和输出文件夹outputsum,如下:
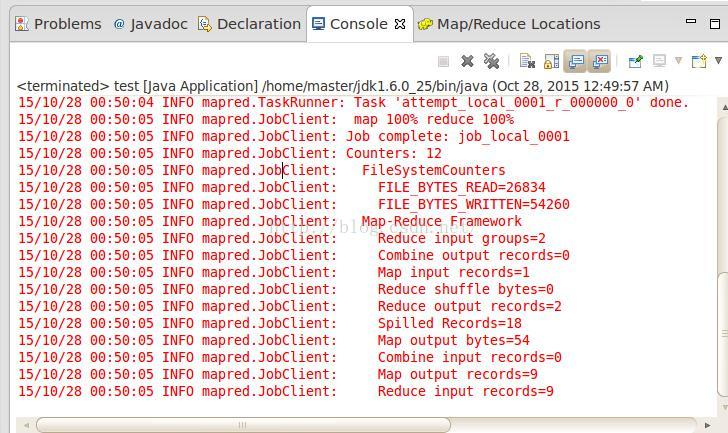
点击运行,结果界面如下:
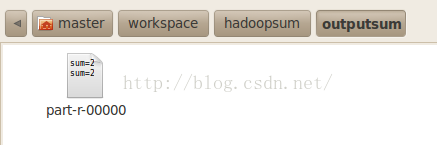
此时再去工程目录下查看,会发现多了一个outputsum输出文件夹,打开后可以看到输出结果:
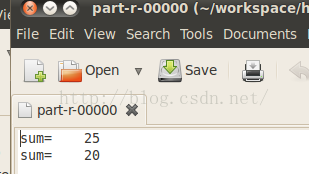
解释一下:
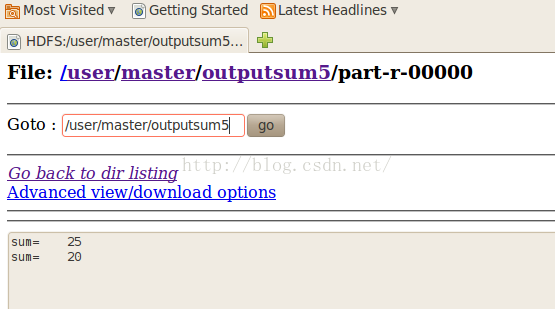
输入文件夹内容为:1 2 3 4 5 6 7 8 9
Master把数字1 3 5 7 9分配给了slave1,把数字2 4 6 8分配给了slave2,所以在输出文件夹中给出的结果是:slave1返回了1+3+5+7+9=25,slave2返回了2+4+6+8=20.
6、另一种方式:不直接在eclipse下运行,而是在命令行下运行该程序:
首先要先将该程序打成jar包(具体方法见最后附件Hadoop安装配置),并放到Hadoop-0.20.2目录下,如下为打好的jar包:sumcount.jar
a、把数字放到输入文件file0中:echo “1 2 3 4 5 6 7 8 9” > file0
b、将文件fileo放到HDFS中的inputsum文件夹中:
hadoop fs -put /home/master/hadoop-0.20.2/file0 inputsum
放进去后效果如下:
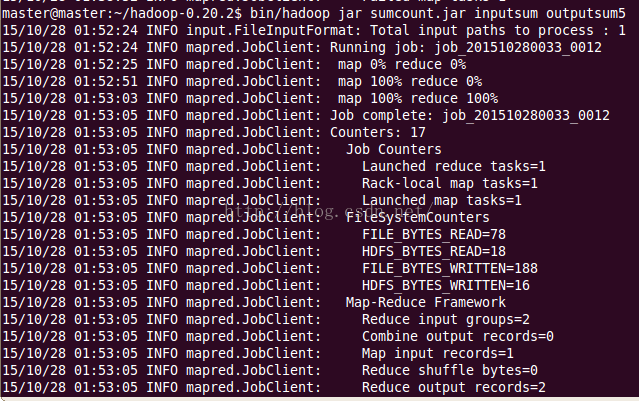
c、在命令行中运行该程序:bin/hadoop jar sumcount.jar inputsum outputsum5,其中的outputsum5为HDFS中的输出文件夹,运行效果如下:

d、运行完后,在命令行查看结果:hadoop fs -cat outputsum5/*

或者在在HDFS中查看结果,可以看到文件夹outputsum5:
点开outputsum5后,效果如下:
附件:Hadoop安装配置
一、安装Linux操作系统
对系统做一下更新:$sudo apt-get update
二、修改机器名,并与IP地址绑定
每当Ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。步骤如下:
1、$ sudo gedit /etc/hostname,将/etc/hostname文件中的ubuntu改为master。再$ sudo gedit /etc/hosts,将里面的名字也改为master,重启系统后才会生效,或者$sudo source /etc/hostname更新一下文件。其他节点一样修改;
2、测试两台机器之间是否连通:$ ifconfig 查看机器IP地址,$ping 192.168.160.132,并在所有的机器上的"/etc/hosts"文件中都要添加如下内容:
192.168.160.128 master
192.168.160.132 slave
$Ping slave 看看是否绑定成功;
三、在Ubuntu下安装JDK
1、将jdk-6u25-linux-i586.bin拷贝到/home/jay目录下:执行命令jay@master:~$ chmod u+x jdk-6u25-linux-i586.bin,将bin文件修改为可执行文件;
2、运行:$./jdk-6u25-linux-i586.bin,安装文件;
3、打开文件:$sudo gedit /etc/profile 添加如下信息:
export JAVA_HOME=/home/jay/jdk1.6.0_25
export JRE_HOME=/home/jay/jdk1.6.0_25/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH ;
4、然后$source /etc/profile,使文件内容生效;
5、重启,执行命令:$java -version,查看是否安装成功。若显示:
java version "1.6.0_25"
Java(TM) SE Runtime Environment (build 1.6.0_25-b06)
Java HotSpot(TM) Client VM (build 20.0-b11, mixed mode, sharing),则安装成功。
四、安装ssh服务
ssh可以实现远程登录和管理,是主节点master和各个从几点slave1、slave2之间可以互相通信,传输数据。
1、验证SSH安装,在所有节点上都执行$sudo apt-get install ssh,更新安装;$which ssh、$which sshd、$which ssh-keygen,查看这三个文件是否存在;
2、生成SSH密钥对:使用主节点上的ssh-keygen来生成一个RSA密钥对,jay@master:~$ssh-keygen -t rsa;
3、生成授权文件jay@master:~$cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys , $more /home/test/.ssh/id_rsa.pub ,该命令用来查看密钥(可不执行);
4、将主节点上的公钥分布到各从节点:逐一将公钥复制到每个从节点上,$scp ~/.ssh/id_rsa.pub jay@slave:~/.ssh/192.168.160.128 ;
5、手动登录到从节点,并设置密钥为授权密钥,如下执行[jay@slave2]$ mkdir ~/.ssh、$chmod 700 ~/.ssh、$mv ~/.ssh/192.168.160.128 ~/.ssh/authorized_keys、$chmod 600 ~/.ssh/authorized_keys;生成该密钥后,可以尝试从主节点登录到目标节点来验证它的准确性:[jay@master]$ ssh 192.168.160.132.或者[jay@master]$ ssh slave。
SSH通信原理:以namenode到datanode为例子:Namenode作为客户端,要实现无密码公钥认证,连接到服务端datanode上时,需要在namenode上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥发布到datanode上。当namenode通过ssh连接datanode时,datanode就会生成一个随机数并用namenode的公钥对随机数进行加密,并发送给namenode。namenode收到加密数之后再用私钥进行解密,并将解密数回传给datanode,datanode确认解密数无误之后就允许namenode进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端namenode公钥复制到datanode上。
五、安装hadoop
第一步:将hadoop-0.20.1.tar.gz文件拷贝到/home/jay目录下。
第二步:jay@master:$ tar -xzvf hadoop-0.20.1.tar.gz //将文件解压。
第三步:jay@master:$ chown jay:jay hadoop-0.20.1//将文件所有者改成jay。
第四步:jay@master:$ sudo gedit /etc/profile进入文件将如下信息加到文件里:
export HADOOP_HOME=/home/jay/hadoop-0.20.1
export PATH=$HADOOP_HOME/bin:$PATH
第五步:更改conf目录下的conf/core-site.xml, conf/hdfs-site.xml,conf/mapred-site.xml,conf/hadoop-env.sh,conf/masters,conf/slaves 文件。
a、jay@master:~/home/jay/hadoop-0.20.1/conf/$sudo gedit hadoop-env.sh
进入文件加入如下信息:
export JAVA_HOME=/home/jay/jdk1.6.0_25
b、jay@master:~/home/jay/hadoop-0.20.1/conf/$sudo gedit masters
进入文件加入如下信息:
192.168.160.128
c、jay@master:~/home/jay/hadoop-0.20.1/conf/$sudo gedit slaves
进入文件加入如下信息:
192.168.160.132
d、jay@master:~/home/jay/hadoop-0.20.1/conf/$sudo gedit core-site.xml
进入文件加入如下信息:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/jay/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.160.128:9000</value>
</property>
</configuration>
e、jay@master:~/home/jay/hadoop-0.20.1/conf/$sudo gedit hdfs-site.xml
进入文件加入如下信息:(replication默认是3,如果不修改,datanode少于三台就会报错)。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
f、jay@master:~/home/jay/hadoop-0.20.1/conf/$sudo gedit mapred-site.xml
进入文件加入如下信息:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.160.128:9001</value>
</property>
</configuration>
第六步:执行jay@master:~/$ scp hadoop-0.20.1 jay@slave:/home/jay/hadoop-0.20.1 //将文件hadoop-0.20.1拷贝到其它两个虚拟机上就可以了。
六、运行hadoop自带的wordcount程序
第一步:jay@master:~/hadoop-0.20.1/bin/$ hadoop namenode –format //格式化文件系统,新建一个文件系统;
第二步:jay@master:~/hadoop-0.20.1/$ start-all.sh //启动hadoop的所有守护进程;
第三步:jay@master:~/hadoop-0.20.1/$ jps //查看进程,master虚拟机上的结果。要让6个守护进程(namenode、datanode、jobtracker、tasktracker、jps、scendarynamenode)全部启动才可以;在slave2 虚拟机上 jay@slave2:~/hadoop-0.20.1/$ jps,slave节点上启动3个守护进程;
第四步:先在本地磁盘建立两个输入文件file01 和file02:执行命令jsj@master:~$ echo “Hello World Bye World” > file01、jsj@master:~$ echo “Hello Hadoop Goodbye Hadoop” > file02
第五步:
先建立个文件夹jay@master:~/hadoop-0.20.1$ hadoop fs -mkdir input;
jay@master:~/hadoop-0.20.1$ bin/hadoop fs -put /home/jay/file1 inputTest//把文件file01和file02放到hdfs文件系统中;
jay@master:~/hadoop-0.20.1$ bin/hadoop jar hadoop-0.20.1-examples.jar wordcount inputTest outputTest //执行wordcount程序。
第六步:jsj@master:~/hadoop-0.20.1$ hadoop fs -cat outputTest/* //查看结果:
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
至此hadoop运行环境已经全部搭建完成。如果要按照此方法搭建请注意每次运行命令的用户和路径。
七、eclipse的安装与配置
Eclipse安装Hadoop插件方法:
a、在Hadoop-0.20.2包中--contrib--eclipse-plugin--hadoop-0.20.2-eclipse-plugin.jar包放入到Eclipse--plugins中,重启Eclipse。
b、新建一个工程,file--new--project--Java project--project name--finish。New--class--name--finish。
c、加入Hadoop自带的jar包:工程上右键--build path--configure build path--libraries--add library--user library--next--user library--new--name--ok--add external JARS--Hadoop-0.20.2中的jar包--ok--finish--ok。
d、Eclipse中使用Hadoop:window--open perspective--other--map/reduce。在下方有个大象图标--右键--edit Hadoop location--主机名、用户名、端口号(和conf配置中一致即可)、IP地址--ok。
e、运行:在项目中run configurations--arguments设置参数(也就是上面讲的建立input和output文件夹)--运行,去Java的workplace查看结果。
八、eclipse中将写好的程序打成jar包
1、在工程Hadoopsum上右键,点击export,选择JAR file如下:
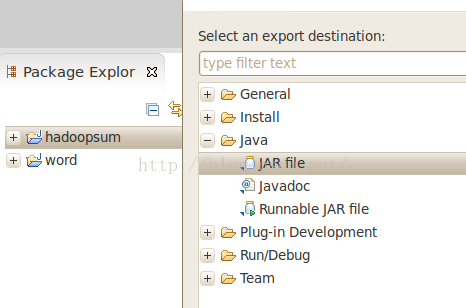
点击下一步后,选择要打成jar包的程序sumcount,java,并指定打好的jar包存放路径:
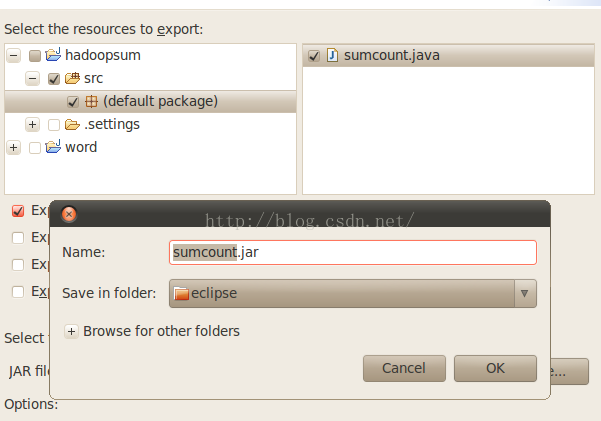
点击下一步后,选择Hadoop运行该程序的入口sumcount.class:
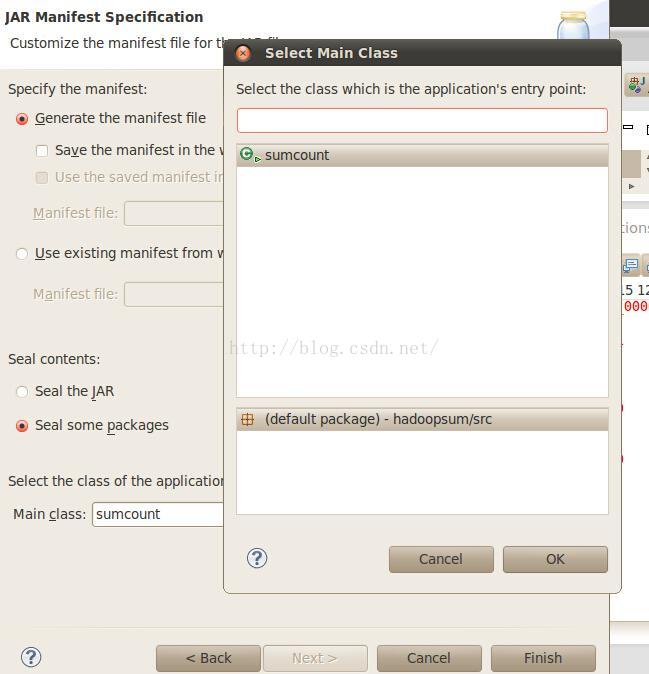
点击finish。到指定目录中寻找该jar包,之后放到Hadoop-0.20.2目录中,就可在命令行下使用该jar包了。















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









