









判别分析
Table of Contents
1 距离判别分析
- 基本概念
- 判别分析是用以判别个体所属群体的一种统计方法产生于20世纪30年代, 在许多现代自然 科学的各个分支和技术部门中得到了广泛的应用
- 例-心脏病利用计算机对一个人是否有心脏病进行判断时, 可以抽取一批没有心脏病的人, 测量其 $p$个指标的数据, 然后再取一批已知患有心脏病的人, 同样也测得 p 个相同指 标数据, 利用这些数据建立一个判别函数, 并求出相应的临界值, 对新病人可以通过测得其 指标数据, 给出是否患心脏病的结论
- 其他例子
- 化石及文物年代的判断,
- 地质学中, 对是否有矿的判断
- 质量管理中, 对产品是否合格的判断
- 植物学中, 对新发现植物种别的判断
- 判别分析是统计学中经典的分类预测方法。
- 根据已有的训练样本, 确定分类型输出变量与数值型输入变量之间的数量关系, 建立 判别函数,
- 给定新的样本数据, 通过判别函数, 实现对新数据输出变量类别的预测
- 按照判别准则可以分为距离判别法, Fisher判别法和Bayes判别法
- 距离判别法简介
- 模型 设有分别来自 K 个总体的 nk,k=1,⋯,K 个样本, 每份样本都有若干个输入变量 X1,X2,...,Xp , (p<k) 个观测值, 且均为数值型, 服从正态分布
- 距离判别法的主要思路
- 将 nk 个样本数据看做 p 维空间中的点, 分别计算每个类别的类中心和类协方差矩 阵
- 分别计算新数据到各类别中心的Mahalonobis距离,
- 根据距离最近的原则, 将新数据点判给距离最近的类别
- 模型-马氏距离
- 两点间马氏距离 设
X,Y
为总体
G
中抽取的样本,
G
服从
p
维正态分布
N(μ,V)
定义
X,Y
两点之间的马氏距离为
dM(X,Y)=(X−Y)TV−1(X−Y)−−−−−−−−−−−−−−−−−−√
- 新数据点
X
与总体
G
的马氏距离, 设
G
的重心为
μ
, 协方差阵为
V
, 则
dM(X,G)=(X−μ)TV−1(X−μ)−−−−−−−−−−−−−−−−−√
- 两点间马氏距离 设
X,Y
为总体
G
中抽取的样本,
G
服从
p
维正态分布
N(μ,V)
定义
X,Y
两点之间的马氏距离为
- 判别分析以两个类别为例
- 设有两个类别, G1 和 G2 ,
- 从第一个总体中抽取 n 个样本, 从第二个总体中抽取m 个样本,
- 每个样本有 p 个特征, 分别计算每个总体的均值估计和协方差阵的估计
μ1=1n∑i=1nX1i,μ2=1m∑j=1mX2j
- 协方差矩阵的估计分别为
Σ1Σ2=1n∑i=1n(X1i−μ1)(X1i−μ1)T=1m∑j=1m(X2j−μ2)(X2j−μ2)T
- 计算马氏距离
D2(X,Gi)=(X−μi)′(Σ1)−1(X−μi), i=1,2显然, 马氏距离是点 X 到类中心向量的协方差阵逆加权后的距离。
- 判别规则
- 如果 D2(X,G1)<D2(X,G2) , 则 X∈G1
- 如果 D2(X,G1)>D2(X,G2) , 则 X∈G2
- 如果 D2(X,G1)=D2(X,G2) , 则 待判断
进一步可以构造判别函数 W(X)=D2(X,G2)−D2(X,G1) ,则相应的判别规则为
- 如果 W(X)>0 则 X∈G1
- 如果 W(X)<0 则 X∈G2
- 如果 W(X)=0 则 待判断
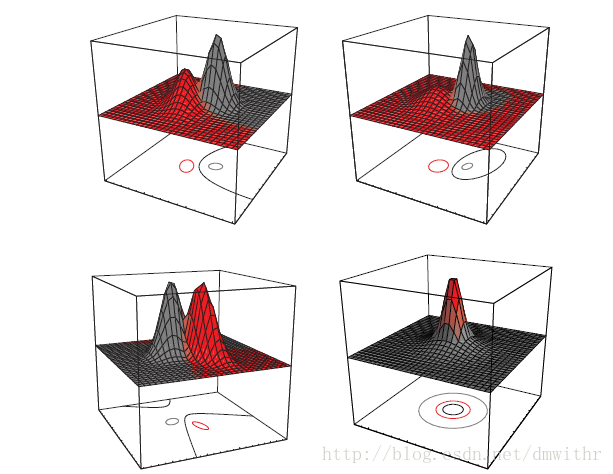
- 协方差相同时的线性判别函数–二维情形

- 协方差相同时的线性判别函数–二维情形

- 协方差阵不同时–非线性判别函数
判别函数 W(X)=D2(X,G2)−D2(X,G1) 是一个二次判别函数, 是一个分割曲线或超曲面
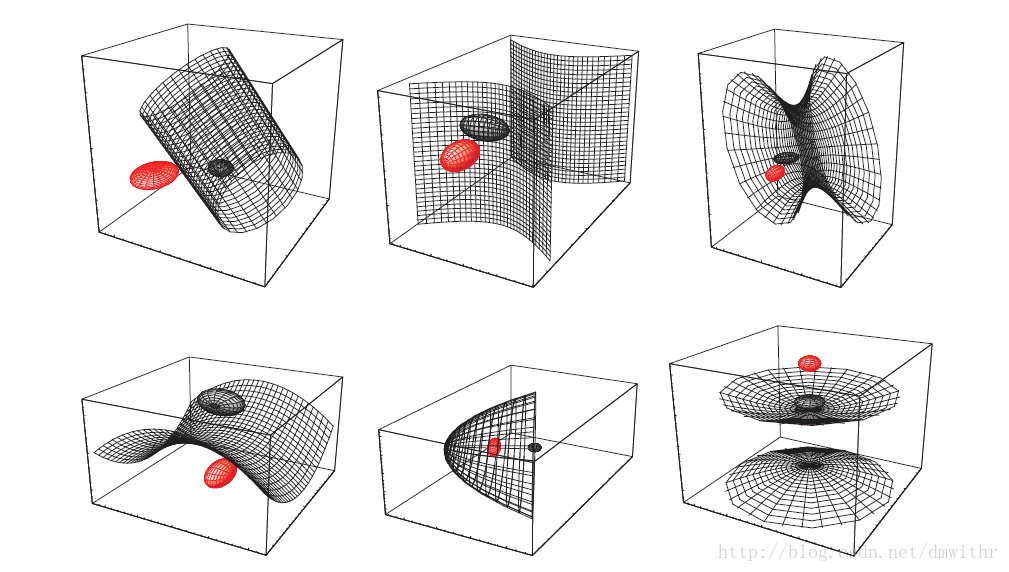
- 协方差阵不同时, 三维情形
2 Fisher判别分析
- Fisher判别法
- Fisher 判别法基本思想: R. A. Fisher1932年提出 先投影再判别, 其中投影是Fisher判别的核心思想,
- 投影的含义是进行线性变换, 之后在低维空间中寻找更好的判别方法
- 投影法则
- 从两个总体中抽取具有 p 个指标的样品观测数据, 记为 X1,⋯,Xp ,
- 借助于方差分析的思想,构造线性判别函数
y=b0+b1X1+...+bpXp
- 系数 bi 称为判别系数,表示各输入变量对于判别函数的影响,
- bi 的确定规则是两组间的组间离差最大, 而每个组的组内离差最小
- 寻找最理想的分类判别效果
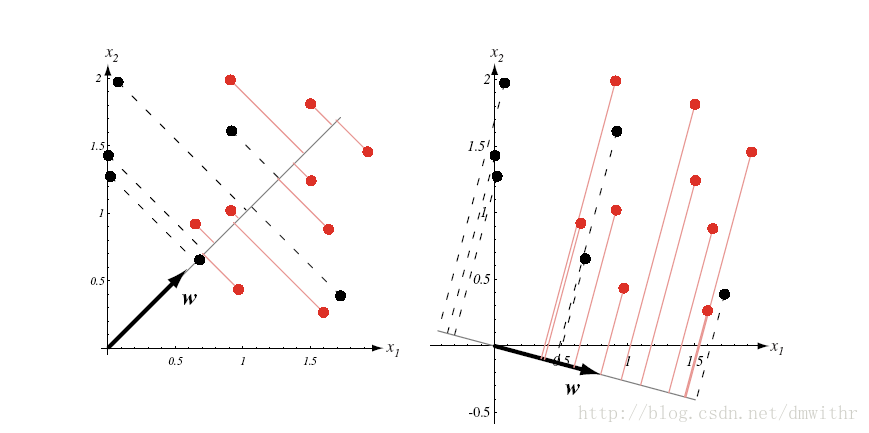
二维数据投影到一维空间中
- 高维情形
三维数据投影到二维空间中
- 理论分析
- 首先应该在输入变量的p维空间中, 找到某个线性组合, 使各类别间的差异最大(和组内差异 相比较而言), 作为第一维度, 代表输入变量组间方差中的最大部分, 得到第一判别函数
- 然后, 按照同样规则依次找到第二判别函数、
- 第三判别函数,
- 且各判别函数之间尽可能独立
- 求解-矩阵形式表示(以两组判别为例)
- 设原始数据为 xki, i=1,⋅,nk,k=1,⋯,K
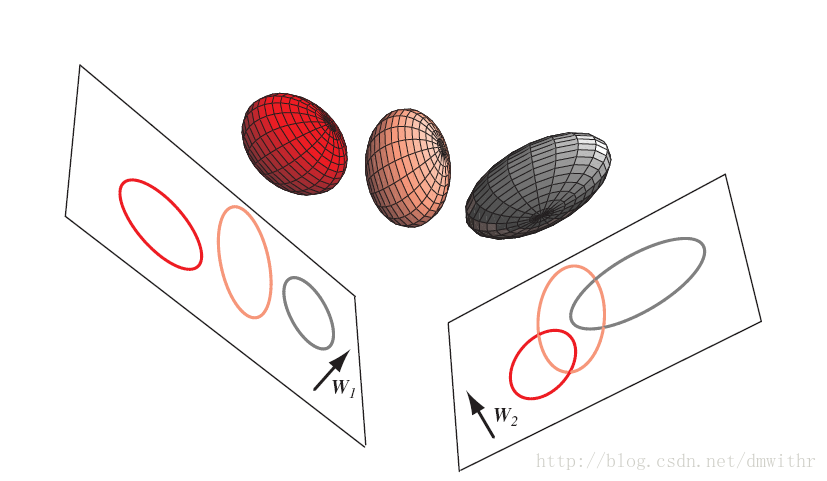
- 点 x 的以a为法方向的投影为 a′x 则各组数据的投影为 a′xk1,a′xk2,...,a′xknk,k=1,⋯,K ,记 Gk 组投影的均值为 a′x¯(k)=1nk∑i=1nka′x¯(k)i,k=1,⋯,K ,
- 则 K 组数据投影的总均值为 a′x¯=1n∑k=1K∑i=1nma′x¯(m)i
- 组间平方和 记为SSG
SSG=∑m=1knm(a′x¯(m)−a′x¯)2=a′[∑m=1knm(x¯(m)−x¯)(x¯(m)−x¯)′]a=a′Ba- 其中 B=[∑m=1knm(x¯(m)−x¯)(x¯(m)−x¯)′] 代表了各组均值和总 均值的差异
- 称为组间 SSCP(Sums of Squares and Cross-product Matrix)
- 组内离差平方和记为SSE
SSE==∑m=1k∑i=1nm(a′x(m)i−x¯(m))2a′[∑m=1k∑i=1nm(x(m)i−x¯(m))(x(m)i−x¯(m))′]a=a′Ea- 其中 E=∑m=1k∑i=1nm(x(m)i−x¯(m))(x(m)i−x¯(m))′ 为组内SSCP
- 注意上述的 E,B 都可以通过数据直接计算得出
- 寻找 a 使得SSG尽可能大 而SSE尽可能小,
考虑SSG和SSE的比值,
Δ(a)=a′Baa′Ea→max可以证明使 Δ(a) 达到最大的值为 方程 |B−λE|=0 的最大 特征根 λ1 记 方程 |B−λE|=0 的全部特征根为 λ1≥λ2≥⋯≥λr>0 , 相应的特征变量为 ν1,ν2,⋯,νr 则判别函数为 yi(x)=ν′ix
- Fisher 线性判别函数的求法
- 不妨记 B=SSG 代表组间离差阵, A=SSE 代表组内离差阵
- 求
a
使得
a′Baa′Aa=defΔ(a)
达到最大。
- 显然这样的 a 只与方向有关, 因此假设附加条件为 a′Aa=1
- 此时问题转化为求 a ,使得 Δ(a)=a′Ba 在条件 a′Aa=1 的条件下达到最大
- 构造拉格朗日目标函数为
φ(a)=a′Ba−λ(a′Aa−1)
- 拉格朗日乘子法
- 关于 a 和
λ
求导得
⎧⎩⎨⎪⎪⎪⎪∂φ∂a=2(B−λA)a=0,∂φ∂λ=1−a′Aa=0
- 由上述方程组的第一个方程知, λ 是 A−1B 的特征根, a 是相应的特征 向量, 且可以证明 λ=Δ(a) , 实际上 Δ(a)=a′Ba=λa′Aa=λ
- 因此上述条件极值问题转化为求 A−1B 的最大特征根和相应特征向量问题
- 设 A−1B 的非零特征值为 λ1≥λ2≥⋯≥λr>0 ,相应的满足约束条件的特征向量为 l1,⋯,lr .
- 取 a=l1 时 Δ(a) 可以达到最大, 最大值为 λ1
- Δ(a) 的大小可以衡量判别函数 u(X)=a′X 的判别效果
- 定义 λ1/∑i=1rλi 称为线性判别函数 u1(X)=l11X 的判别能力
- 关于 a 和
λ
求导得
- 判别能力的定义
- pi 为第i个判别函数的判别能力
pi=λi∑h=1rλh- 前m个判别函数的判别能力为
∑i=1mpi=∑i=1mλi∑h=1rλh可依据两个标准决定最终取几个判别函数
- 指定取特征值大于 1 的特征根
- 前m个判别函数的判别能力达到指定的百分比,一般采用 85\%
- Fisher 判别法的进行步骤
- 首先计算Y空间中样本所属类别的中心
- 对于新样本, 计算其Fisher 判别函数值, 以及Y空间中与各类别中心的距离
- 然后利用距离判别法, 判别其归属的类别
W(Y)=(Y−Y¯)′Σ−1(Y¯i−Y¯(j))Y¯=12(Y¯i+Y¯(j))
当 W(y)>0 时, 新样本 X属于第 i 类
3 判别分析实现(Using R)
- Iris数据简介
- 数据150条,包含三类鸢尾花数据, 每样50个
- Iris Setosa
- Iris Versicolour
- Iris Virginica
- 四个变量分别为
- 花萼(sepal) 的长度(length)
- 宽度 (width)
- 花瓣(petal) 的长度(length)
- 宽度 (width)
- 数据150条,包含三类鸢尾花数据, 每样50个
- 数据展示
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa
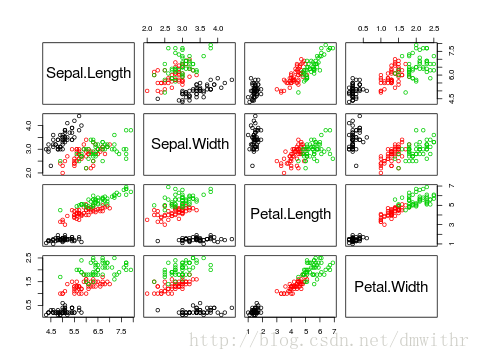
- 数据图形展示
plot(iris[,1:4],col=as.numeric(iris[,5]))
- Fisher 线性判别分析实现(Using R)
- 在R中实现线性判别分析的命令是 MASS 包中的LDA函数(linear discriminant Analysis)
- 下面以 Iris 数据为例进行判别分析, 首先从150条数据中抽取75条数据建立判别函数
require("MASS") set.seed(1314) train <- sample(1:150, 90) table(iris$Species[train])
setosa versicolor virginica 30 31 29 - 进行线性判别分析,并预测剩余60个样品的类别号
z <- lda(Species ~ ., iris, prior = c(1,1,1)/3, subset = train) test.sp<-predict(z, iris[-train, ])$class test.true<-iris[-train,5] table(test.true,test.sp)
test.sp test.true setosa versicolor virginica setosa 20 0 0 versicolor 0 18 1 virginica 0 1 20
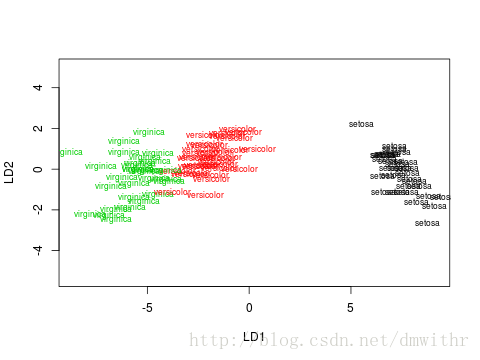
- 线性判别分析的结果
Call: lda(Species ~ ., data = iris, prior = c(1, 1, 1)/3, subset = train) Group means: Sepal.Length Sepal.Width Petal.Length Petal.Width setosa 5.013333 3.456667 1.440000 0.2366667 versicolor 5.967742 2.832258 4.287097 1.3451613 virginica 6.582759 2.986207 5.582759 1.9827586 Coefficients of linear discriminants: LD1 LD2 Sepal.Length 0.8095703 0.2655179 Sepal.Width 1.4207588 -2.4118265 Petal.Length -2.0779530 0.5599844 Petal.Width -2.9318010 -2.3536921 Proportion of trace: LD1 LD2 0.9943 0.0057 - 线性判别分析的投影效果
plot(z,col=as.numeric(iris[train,5]))














 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









