










学习hadoop以及工作快两年了,刚开始自学的时候,看了很多的视频、文档什么的,也没注意总结过,拿着能用就行,但学的东西越多,越觉得乱,正好趁最近工作不忙,想写一点Mapreduce的程序,第一为了给自己回顾一下以前的知识,第二也是想给如果能对新入门的同学有一点帮忙那也是很好的,这里的写大部分,程序都是来自一些教学视频,以及一些书籍中的实例,但都通过自己实践可行,也同进加入了一些自己的见解。目的是巩固学习,如有不足之处请大神多多指正。如果有侵权行为请联系本人删除博客。
首先是我们就来写写mapreduce中的helloword来自hadoop权威指南中的实例。
map函数:这里不做过多的解释,
基本的使用就是继承org.apache.hadoop.mapreduce.Mapper类并实现其核心的方法map()方法(也就是我们实现业务逻辑的方法),
Mapper类中的其它方法我们后面的实例中会讲到
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 0067011990999991950051507004888888880500001N9+00781+9999999999999999999999
* 数据说明:
* 第15-19个字符是year
* 第45-50位是温度表示,+表示零上 -表示零下,且温度的值不能是9999,9999表示异常数据
* 第50位值只能是0、1、4、5、9几个数字
* @author Administrator
*/
public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* 定义异常数据常量
*/
private static final int FAIL_DATA = 9999;
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
/**
* 取出温度的正负号
*/
String tmp = line.substring(45, 46);
int temp = 0;
/**
* 判断温度为正还是负并在原始串中取出值
*/
if( "+".equals(tmp)) {
temp = Integer.valueOf(line.substring(46, 50));
} else {
temp = Integer.valueOf(line.substring(45, 50));
}
/**
* 判断温度是否异常,且第50位的标志位是否正常
*/
if( temp != FAIL_DATA && line.substring(50, 51).matches("[01459]")){
/**
* 所有判断通过则输出年 温度到Reduce
*/
context.write(new Text(year), new IntWritable(temp));
}
}
/**
* 一般写Mapreduce时都可以假设数据是以什么形式进入map或者reduce以便
* 检验逻辑是否正确
* @param args
*/
public static void main(String[] args) {
String line = "0067011990999991950051507004888888880500001N9-99991+9999999999999999999999";
String year = line.substring(15, 19);
String tmp = line.substring(45, 46);
int temp = 0;
if( "+".equals(tmp)) {
temp = Integer.valueOf(line.substring(46, 50));
} else {
temp = Integer.valueOf(line.substring(45, 50));
}
if( Integer.valueOf(line.substring(46, 50)) != FAIL_DATA && line.substring(50, 51).matches("[01459]")){
System.out.println(year + " " + temp);
}
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
/**
* reduce端的业务就比较简单了,因为通partion阶段同一年份的
* 温度已经被归到同一个迭代器中(对于partion的部分后面会详解),
* 所以reduce就只需要把筛选出
* 最高的温度进行输出就行
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int max_temp = Integer.MIN_VALUE;
/**
* 找出迭代器中传入年份的最高温度
*/
for(IntWritable value : values) {
max_temp = Math.max(max_temp, value.get());
}
/**
* 输出年份 以及该年份的最高温度
*/
context.write(key, new IntWritable(max_temp));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobMain {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = new Job(configuration,"max_temp_job");
job.setJarByClass(JobMain.class);
job.setMapperClass(MaxTemperatureMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileSystem fs = FileSystem.get(configuration);
Path outputDir = new Path(args[1]);
if(fs.exists(outputDir)) {
fs.delete(outputDir,true);
System.out.println("the outputDir is exist,but it has been deleteed!");
}
FileOutputFormat.setOutputPath(job, outputDir);
System.exit(job.waitForCompletion(true)? 0: 1);
}
}
实验数据:
0067011990999991950051507004888888889999999N9+00001+9999999999999999999999
0067011990999991950051512004888888889999999N9+00221+9999999999999999999999
0067011990999991950051518004888888889999999N9-00111+9999999999999999999999
0067011990999991949032412004888888889999999N9+01111+9999999999999999999999
0067011990999991950032418004888888880500001N9+00001+9999999999999999999999
0067011990999991950051507004888888880500001N9+00781+9999999999999999999999
集群运行情况:

运行命令:
$HADOOP_HOME/bin/hadoop jar mr.jar com.seven.mapreduce.one.JobMain /input/one /output/one
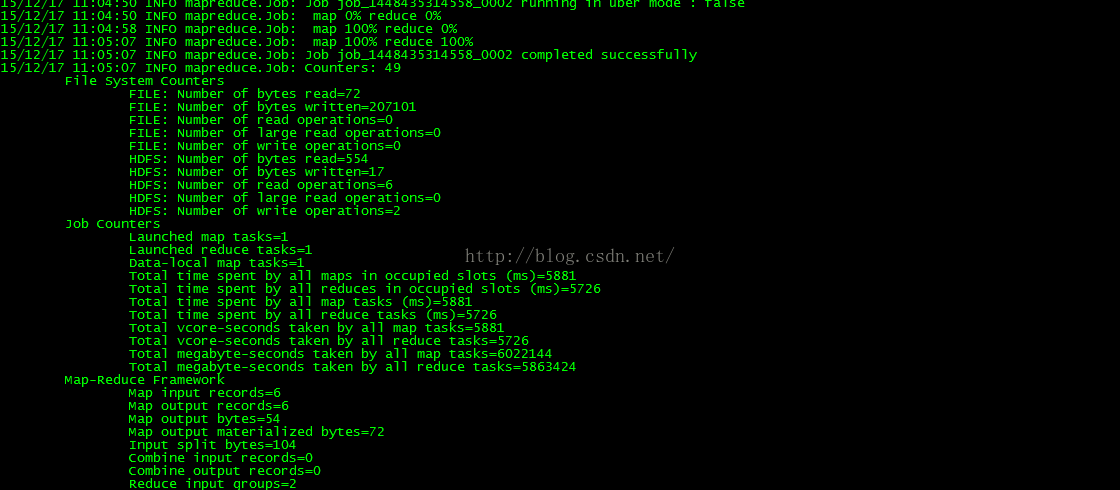
运行结果:















 3050
3050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









