



 ifb驱动作为Linux内核的一部分,主要用于资源分享,如队列策略的共享和入站流量的队列管理。它是一个虚拟网卡,可以在不改变数据包方向的情况下应用TC过滤。本文介绍ifb的工作原理、队列管理和多网卡共享策略。
ifb驱动作为Linux内核的一部分,主要用于资源分享,如队列策略的共享和入站流量的队列管理。它是一个虚拟网卡,可以在不改变数据包方向的情况下应用TC过滤。本文介绍ifb的工作原理、队列管理和多网卡共享策略。
首先贴上Linux内核的ifb.c的文件头注释:
for sharing of resources:
1) qdiscs/policies that are per device as opposed to system wide.
ifb allows for a device which can be redirected to thus providing
an impression of sharing.
2) Allows for queueing incoming traffic for shaping instead of
dropping.
The original concept is based on what is known as the IMQ
driver initially written by Martin Devera, later rewritten
by Patrick McHardy and then maintained by Andre Correa.
You need the tc action mirror or redirect to feed this device
packets.
This program is free software; you can redistribute it and/or
modify it under the terms of the GNU General Public License
as published by the Free Software Foundation; either version
2 of the License, or (at your option) any later version.
Authors: Jamal Hadi Salim (2005)
ifb驱动太简单,以至于很短的话就可以将其说清,然后上一幅全景图,最后留下一点如何使用它的技巧,本文就完了。
ifb驱动模拟一块虚拟网卡,它可以被看作是一个只有TC过滤功能的虚拟网卡,说它只有过滤功能,是因为它并不改变数据包的方向,即对于往外发的数据包被重定向到ifb之后,经过ifb的TC过滤之后,依然是通过重定向之前的网卡发出去,对于一个网卡接收的数据包,被重定向到ifb之后,经过ifb的TC过滤之后,依然被重定向之前的网卡继续进行接收处理,不管是从一块网卡发送数据包还是从一块网卡接收数据包,重定向到ifb之后,都要经过一个经由ifb虚拟网卡的dev_queue_xmit操作。说了这么多,看个图就明白了:
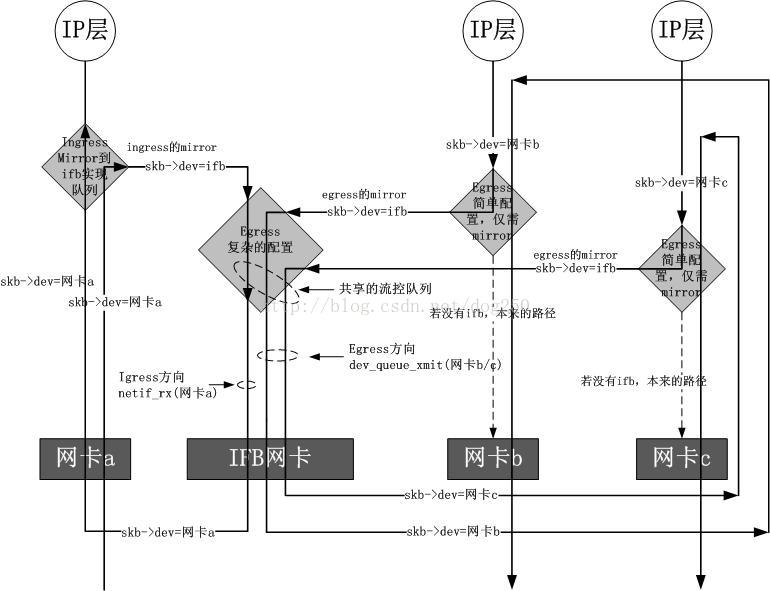
ingress队列
Linux TC是一个控发不控收的框架,然而这是对于TC所置于的位置而言的,而不是TC本身的限制,事实上,你完全可以自己在ingress点上实现一个队列机制,说TC控发不控收只是因为Linux TC目前的实现没有实现ingress队列而已。Linux的协议栈上有诸多的钩子点,Netfilter当然是最显然的了,它不但可以实现防火墙和NAT,也可以将一个数据包在PREROUTING钩子点上queue到一个队列,然后再将此队列的数据包发往一个虚拟网卡,虚拟网卡的xmit回调函数将数据包重新放回Netfilter将数据包STOLEN走的点上,在发往虚拟网卡的时候做发送流控从而变相地实现ingress队列,这就是IMQ的原理,它工作地不错,但是需要在skb中增加字段,使用起来也要牵扯到Netfilter的配置,不是那么纯粹,于是在这个思想的基础上实现了ifb驱动,这个驱动直接挂在TC本身的ingress钩子上,并不和Netfilter发生关系,但是由于TC的钩子机制并没有将一个数据包偷走再放回的机制,于是只有在做完ifb的流控后在ifb网卡的xmit函数中重新调用实际网卡的rx一次,这个实现和Linux Bridge的实现中完成local deliver的实现如出一辙。
Qdisc的多网卡共享
除了ingress队列之外,在多个网卡之间共享一个根Qdisc是ifb实现的另一个初衷,可以从文件头的注释中看出来。如果你有10块网卡,想在这10块网卡上实现相同的流控策略,你需要配置10遍吗?将相同的东西抽出来,实现一个ifb虚拟网卡,然后将这10块网卡的流量全部重定向到这个ifb虚拟网卡上,此时只需要在这个虚拟网卡上配置一个Qdisc就可以了。性能问题
也许你觉得,将多块网卡的流量重定向到一块ifb网卡,这岂不是要将所有的本属于不同的网卡队列被不同CPU处理的数据包排队到ifb虚拟网卡的一个队列被一个CPU处理吗?事实上,这种担心是多余的。是的,ifb虚拟网卡只有一个网卡接收队列和发送队列,但是这个队列并非被一个CPU处理的,而是被原来处理该数据包的CPU(只是尽量,但不能保证就是原来处理该数据包的那个CPU)继续处理,怎么做到的呢?事实上ifb采用了tasklet来对待数据包的发送和接收,在数据包进入fib的xmit函数之后,将数据包排入队列,然后在本CPU上,注意这个CPU就是原来处理数据包的那个CPU,在本CPU上调度一个tasklet,当tasklet被执行的时候,会取出队列中的数据包进行处理,如果是egress上被重定向到了ifb,就调用原始网卡的xmit,如果是ingress上被重定向到了ifb,就调用原始网卡的rx。当然,tasklet中只是在队列中取出第一个数据包,这个数据包不一定就是在这个CPU上被排入的,这也许会损失一点cache的高利用率带来的性能提升,但不管怎样,如果是多CPU系统,那么显然tasklet不会只在一个CPU上被调度执行。另外,开销还是有一点的,那就是操作单一队列时的自旋锁开销。
优化方式是显然的,那就是将队列实现成“每CPU”的,这样不但可以保证cache的高利用率,也免去了操作单一队列的锁开销。

















 4406
4406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









