






正文
为了弥补pcap文件的缺陷,让抓包文件可以容纳更多的信息,pcapng格式应运而生。关于它的介绍详见《PCAP Next Generation Dump File Format》
当前的wireshark/tshark抓取的包默认都被保存为pcapng格式。形而上的论述就不多谈了,直接给出一个pcapng数据包文件的例子:
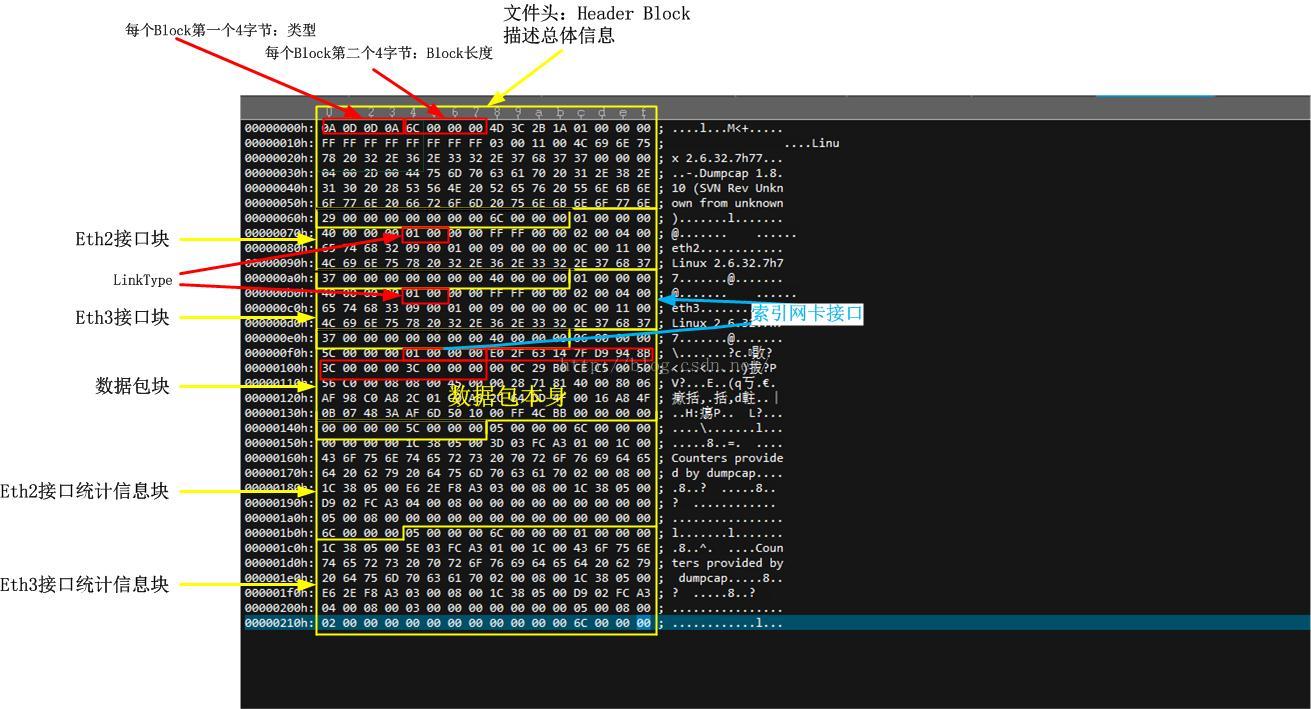
然后我强烈建议,对着《PCAP Next Generation Dump File Format》来把一个实际抓取的pcapng文件里面的每一个字节都对应清除,接下来写一个python脚本,手工构造一个这样的文件,可以用wireshark打开并解析的那种(其实这并不是一件特别难的事情)。这样你就算彻底掌握了这个格式。
还是那个需求,统计一个抓包文件中一个IP地址发出的数据总量,对于pcapng文件,由于其格式已经有了大不同啊大不同,python脚本也就截然不同了,列如下:#!/usr/bin/python
# Default tcpdump buffer size seems to 2M
import sys
import socket
import struct
filename = sys.argv[0]
filename = sys.argv[1]
#print filename
ipaddr = sys.argv[2]
direction = sys.argv[3]
packed = socket.inet_aton(ipaddr)
ip32 = struct.unpack("!L", packed)[0]
file = open(filename, "rb")
pkthdrlen=16
iphdrlen=20
tcphdrlen=20
stdtcp = 20
total = 0
pos = 0
start_seq = 0
end_seq = 0
# Read file header(type and size)
typedata = file.read(8)
(type, size) = struct.unpack("=LL", typedata)
# Skip header description
skipdata = file.read(size-8)
# Read interface desc block
interfacedata = file.read(8)
(type, size) = struct.unpack("=LL", interfacedata)
# Get linktype from int-desc block
ltdata = file.read(4)
(type, ltsize) = struct.unpack("=HH", ltdata)
if ltsize == 0x71:
pkthdrlen = 16
else:
pkthdrlen = 14
# Skip other of int-desc block
skipdata = file.read(size-8-4)
# Read packet block
pktdata = file.read(8)
(type, size) = struct.unpack("=LL", pktdata)
ipcmp = 0
cnt = 0
while pktdata:
# Skip Interface ID
skipdata = file.read(4)
# Get time and length
# sec:
# microsec:
# iplensave:
# origlen:
data = file.read(16)
(sec, microsec, iplensave, origlen) = struct.unpack("=LLLL", data)
# Read linklayer
linkdata = file.read(pkthdrlen)
# Read IP header
ipdata = file.read(iphdrlen)
(vl, tos, tot_len, id, frag_off, ttl, protocol, check, saddr, daddr) = struct.unpack(">ssHHHssHLL", ipdata)
iphdrlen = ord(vl) & 0x0F
iphdrlen *= 4
# Read TCP standard header
tcpdata = file.read(stdtcp)
(sport, dport, seq, ack_seq, pad1, win, check, urgp) = struct.unpack(">HHLLHHHH", tcpdata)
tcphdrlen = pad1 & 0xF000
tcphdrlen = tcphdrlen >> 12
tcphdrlen = tcphdrlen*4
if direction == 'out':
ipcmp = saddr
else:
ipcmp = daddr
if ipcmp == ip32:
cnt += 1
total += tot_len
total -= iphdrlen + tcphdrlen
if start_seq == 0: # BUG?
start_seq = seq
end_seq = seq
# Skip options and data
skipdata = file.read(size - 8 - 4 - 16 - pkthdrlen - iphdrlen - stdtcp)
# Read next packet
pos += 1
pktdata = file.read(8)
(type, size) = struct.unpack("=LL", pktdata)
if type <> 0x06:
break
# Get interface statistics
if type == 0x05:
skiphdr = file.read(12)
opthdr = file.read(4)
(code, length) = struct.unpack("=HH", opthdr)
while length <> 0:
# 32-bit boundary! BUG?
if code == 5:
opt = file.read(length)
(drops,) = struct.unpack("=Q", opt)
# 不能这么将丢弃的数据包算进去!抓包时就这一个流吗?每个被丢弃的包都是携带数据的吗?...
# 所以,pcapng仅仅统计被丢弃的数据包的数量,不够!怎么才够?不知道!!
# total += drops*1460
elif code == 7:
opt = file.read(length)
(drops,) = struct.unpack("=Q", opt)
# total += drops*1460
else:
skipopt = file.read(length)
opthdr = file.read(4)
(code, length) = struct.unpack("=HH", opthdr)
print pos, 'Actual:'+str(total), 'ideal:'+str(end_seq-start_seq)执行方式与《 pcap文件的python解析实例》针对pcap文件的解析完全一样。
pcapng文件的内容还有很多,这里不再赘述了。本文并没有谈及关于每一个Block里都可以携带的Options信息,那个东西可以再写一篇的。
也许python高手会笑我,为什么我非要用python去解析这么底层的pcap/pcapng文件,用dpkt库不是更好吗?是的,如果本着我文中所提的需求而言,用dpkt固然更好,但是用dpkt的话,你无法知道pcap/pcapng文件格式的全貌,甚至都不可能见一斑!我用python直接解析pcap/pcapng文件,目的有二,首先我要学python,其次我要趁机了解一下pcap/pcapng的细节!我可不想成为女司机那样的。诚然,最高效的方案解决问题最可取,然而,在我这里没有什么问题是要解决的,仅仅是玩玩!
仅仅是玩玩,这也是我折腾了这么久的原因。不过还是很有收获的。
附录
抓包丢弃的问题:dropped by kernel释义与避免
如果你纵观pcap的文件格式(在《 pcap文件的python解析实例》中有),你会发现,整个文件只是记录了数据包本身,而丝毫没有涉及那些”由于系统处理能力所限而不得不丢弃的数据包“,而这就造成了统计上的困难。以下仅举一例以说明。数据发送端为S,数据接收端为C,用我的pcapng-parser.py分析后,数据显示了令人惊讶的结果:
接收端接收的数据总量大于发送端发送的数据总量!!
我们排除数据包被中间可耻的运营商重放这种可能,因为我是在自己的环境下测试!这显而易见是由于发送端抓包抓漏了或者或两边都抓漏了,只是发送端漏的更多而导致!然而我们无法证实这种情况。非常明确的是,在你结束抓包的时候,会打印出”XXX packets dropped by kernel“这种信息,很显然,内核并没有成功抓取所有的包(抓包由PACKET套接字驱动,后者受限于套接字接收缓存!)这可怎么办?
pcapng帮了大忙!
pcapng可以把抓包过程中被丢弃的数据包的数量统计在一个section里最终导出给用户看,我们注意到pcapng文件格式的section类型中有一个”Interface Statistics Block“的可选字段,其中统计了在整个抓包过程中的以下信息:

但是这些够了吗?
有的时候,我可能会一次性抓取所有的数据包保存为一个超级大的pcapng文件,然后利用wireshark/tshark的析取功能去析出那些感兴趣的数据流,此时被析取的数据流的大小已经很小了,但是”Interface Statistics Block“依然保持不变,因为在抓包这个层次上,系统根本没有办法去区分数据流!这可怎么办?!没有办法!
即便我知道了”在该数据流中丢弃了几个数据包“,我也没有办法计算出丢弃了多少个字节,因为这涉及到了MSS!诚然,你可以使用肉眼,然而你无敌的肉眼只能在wireshark界面里去看那些”previous segment is not captured.“周边的序列号,然后拿这些缺失的字节数去和pcapng保存的统计值去做四则混合运算!!够了!(以上信息,如欲知详情,请点击wireshark的”统计“菜单的第一项!)
我们怎样可以避免抓包丢失呢?或者说即便不可避免,我们怎样可以最小化抓包丢失(这样可以减小我们的估算难度!)呢?幸运的是,tcpdump/tshark可以指定抓取数据包的长度以及PACKET套接字(使用RING/NetMap会更好)缓存的大小,”-s“选项可以限制抓取数据包的大小:
-s Snarf snaplen bytes of data from each packet rather than the
default of 65535 bytes. Packets truncated because of a limited snapshot
are indicated in the output with ``[|proto]'', where proto is the name of
the protocol level at which the truncation has occurred. Note that taking
larger snapshots both increases the amount of time it takes to
process packets and, effectively, decreases the amount of packet buffering.
This may cause packets to be lost. You should limit snaplen to the
smallest number that will capture the protocol information you're
interested in. Setting snaplen to 0 sets it to the default of 65535, for
back-wards compatibility with recent older versions of tcpdump.
限定数据包的大小大多数情况下并不影响我们抓包的目的,毕竟我们大多数情况下抓包都是为了分析内核问题,用户态的问题我们可以通过应用程序的日志来获得,因此我们几乎不用抓取应用层的数据,而应用层以下的所有协议头长度加在一起也不是一个很大的数字,一般而言128字节以内就可以满足需求!所以-s 128这个选项可以让同样大小的缓冲区容纳更多的数据包。除此之外,”-B“选项则可以指定抓包套接字接收缓冲区的大小。两者双管齐下,解决抓包丢弃问题自然不在话下了。
总有人质疑,这是人之本性,我是人,我也会这样,这是亚里士多德的理论,是吗?是的!由于抓包丢失我无法统计出精确的数据包发送的数值,谁能精确统计以及怎么统计?请回答,如果不能回答,请沉默。
我不沉默,因为我有办法统计。我可以对照TCP的序列号,就像wireshark发现抓包丢失那样发现抓包丢失,但是我并不认为这是有用的,这毫无意义!
pcapng的统计补遗
pcapng文件格式已经足够我容纳尽可能多的数据了,然而问题在PACKET套接字!看Linux内核的packet_rcv函数,我们可看到,内核除了数据包本身之外并没有提供更多的信息。比如,如果我想知道发送某一个TCP数据包的时候,其拥塞窗口是多大?我除了借助于tcpprobe而别无他法!但是,我还是有办法的。
我们在packet_rcv函数里将数据包交给PACKET套接字的时候,不是截断了数据包吗?此时我完全可以将与这个数据包相关的socket的统计信息作为替换加到后面,这些信息包括:当前的拥塞窗口,当前的ssthresh...这样,我们就可以用强大的wireshark/tshark工具来解析这些信息了,而且还可以画出图形呢。
pcap与pcapng之间的转换
说了这么多,其实就统计传输字节数这个需求而言,针对pcap文件和pcapng文件而言完全没有必要用两个脚本!因为pcap和pcapng文件可以互相转换。最简单的方式,用wireshark打开一个文件,然后”另存为“即可,次好的方式,使用editcap命令也可以完成两者间的转换,只需要”-F“选项,就可以完成你需要的,具体操作,请man!














 2260
2260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









