






端午假期家人跟朋友一起去惠州那种野海滩度假去了,而我则加了三天班,不是说想表现什么,也不是因为要逃避旅行的劳顿,而是工作中真实的Deadline所迫....下班后
就我自己了,于是在深夜里便可以随意的折腾点电子设备,写写文章,也是很爽的。由于最近工作实在是太忙,所有思考和整理的时间自然就少了很多,不管怎样,还是利用两个晚上吭哧出来了本文,也算是不容易。不管怎样,这个假期有点假。
本文接着上一篇文章,继续介绍队列管理和Bufferbloat相关的内容。
A number of bloat-fighting changes have gone into the kernel over the last year. The CoDel queue management algorithm works to prevent packets from building up in router queues over time. At a much lower level, byte queue limits put a cap on the amount of data that can be waiting to go out a specific network interface. Byte queue limits work only at the device queue level, though, while the networking stack has other places—such as the queueing discipline level—where buffering can happen. So there would be value in an implementation that could limit buffering at levels above the device queue.
Eric Dumazet's TCP small queues patch looks like it should be able to fill at least part of that gap. It limits the amount of data that can be queued for transmission by any given socket regardless of where the data is queued, so it shouldn't be fooled by buffers lurking in the queueing, traffic control, or netfilter code.
......
当然不是!虽然中间节点对端到端的流量无感,但还是有多种队列管理策略可用,值得注意的是,如果队列满了,队列管理策略对到达的溢出当然是只能丢弃,但这并非意味着队列管理策略只能在队列满了之后才采取丢包动作,事实上,早在队列爆满之前,就要采取动作了。正是对“在什么时候丢包”,“丢哪些包”以及“丢多少包”这三个问题的不同回答,决定了队列管理策略之间的不同。
在分析一种叫做CoDel(Controlled Delay)队列管理算法之前,我再次罗嗦一遍队列是干什么的,队列不是干什么的。
0.多路统计复用的分组交换网络必须要有队列
只要是排队系统,因为固定的服务速率和符合泊松分布的到达速率之间存在瞬时差异(按照时间的积分是相同的,瞬时值是不同的),因此需要有一个队列作为缓冲。这个不多扯,排队理论中有详尽的分析。
1.吸收由于链路速率不匹配导致的暂时性良性突发
比如说TCP在慢启动阶段,并不知道网络的实际带宽承载力,因此可能会瞬时突发超过带宽承载力的数据包,此时需要一个队列来暂存这些超发的数据包。之所以中间节点保有如此的善意,完全在于它相信TCP的拥塞控制算法会紧随其后的降低超发量,这是一个信任造成的合作。至于说端到端的TCP如何来知道开始排队了,有很多种方法,比如可以观察RTT的梯度了解到RTT在持续增大,也可以通过测量速率不再随着发包量的增加而增加,另外还可以用经典的方法,即继续增加发包量,直到发现丢包后迅速降速。不管采用哪种手段,全在于TCP的收敛原则,即任何TCP拥塞控制算法都应该是收敛的,而不该是侵略性的。在符合这个收敛原则的世界里,基本不需要队列管理,因为队列和TCP流量可以自发地达到一个动态平衡。
我将符合收敛原则的TCP流量造成的突发称为 良性突发。
3.队列不用用来占据的
网络链路上有一个设备,该设备上配备了一个队列缓存,该队列缓存可以最多存储N个数据包,那是不是意味着作为端节点就一定要“充分利用”这块缓存呢?即将其填满,然后达到“100%的带宽利用率”。大错特错!所有不以上述1,2两点为基准的排队行为都是耍流氓。注意,队列缓存不是带宽的一部分。
我将不以上述1,2为基准的排队行为称为 恶性突发。
----------------------------
队列管理策略是针对恶意突发的!本文用以下的内容来阐述一下队列管理是如何对付恶意突发的!
对于UDP而言,它是原始带有侵略性的,或者对于那些所谓的TCP加速软件,它们会完全摒弃收敛原则,尽可能提高发送速度,针对这种流量,如果不加以管束,便会让互联网变得不再可用,按照自然商品经济的原则来看,劣币驱良币是必然的!道德丧失之后,往往就该法律出场了。
队列管理的目标不是杜绝排队,而是监管排队行为,一个好的队列管理算法的终极目标是要保证每一个数据包通过该队列的时间尽可能的小,即杜绝Bufferbloat。
----------------------------
那么如何设计一个合理的队列管理策略呢?这就衍生出一个单独的领域,即AQM。
早先的RED算法可以在队列长度达到某个预设的阈值时进行一些随机的丢包(Random drop),由此旨在“提醒”各位TCP来降低发送速率,鉴于绝大部分的TCP的实现都是以丢包作为拥塞信号来做降窗降速处理的,所以RED在大多数情况下工作的很好。然而RED不是自适应的,它的问题如下:
1.丢包阈值如何设定?
RED基于队列长度来判断是否要丢包,队列长度取决于当前排队的包量,如果用排队的包量作为衡量是否丢包的标准,那么引入的排队延迟将和每个流的速率相关,同样长度的队列,如果出口速率快,那么引入的排队延迟就小,出口速率小,排队延迟就大。请注意队列管理的终极目标,是要保证排队时延尽可能小,解决Bufferbloat问题,至于说控制队列长度,充其量只是一种实现终极目标的手段而已。
因此,常规的RED采用的队列长度这个衡量是否丢包的这个标准并不合适。
2.丢包率如何设定?
即便采用队列长度作为衡量丢包的标准是合适的,那么下一个问题是丢多少包呢?
很显然的一个回答是采用固定的丢包率。那么如果队列持续在丢包长度阈值附近摆动的话,将无法很好的达到队列管理的终极目标。我们设队列长度阈值为L,恶意的突发流会持续地将队列填充到L的长度,尽可能减少自己的丢包概率,这种侵略行为将在很大程度上饿死良性流量。在这种情况下,常规RED算法无法很好地对持续的侵略行为进行持续的惩罚。
那么引入一个变化的丢包率呢?当然很好,但是实现却是复杂的,丢包率要如何与队列长度,时间等因素进行关联呢?甚至,队列的丢包阈值都可以是变化的,但这会进一步增加算法的复杂性
...
针对以上的问题,有三个明显的需求:
1.以排队延时本身作为衡量是否丢包的标准
直接瞄准队列管理的终极目标非常合理,即队列管理是为了减少数据包的排队时延,限制队列长度只是可能达到这个目标的一个手段,不用这个手段,还会有别的手段达到同样的目标,我们需要的是,要找一种手段,它比限制队列长度要更好地达到目标!
2.无需外界配置,自适应调整丢包率
有两个流派必须让大家知道,一个流派非常喜欢一切都要是可配置的,这是他们的信仰,另外一个流派则是一切都要自适应,无参数自动化运行,这也是一种信仰,讨论谁对谁错是没有意义的。问题是在什么场景下采用哪种信仰更适合。针对RED队列管理的问题,无疑自适应是合适的,在该场景下,配置化并不能动态适应不断变化的网络流量模型。
3.简单化
实现的简单性永远都是必要的,这是算法可以进一步进化调整所必需的要求。
target:理想情况下,数据包的最长排队延时。
interval:在触发CoDel开始丢包前,持续的数据包排队时间超过target的最长忍耐时间。
CoDel算法并没有严格限制数据包在队列里面待的时间,即排队延时不超过target。而是给予了一个interval时间段的窗口,数据流可以在该时间窗口内观察到RTT的增加,进而采取收敛策略缓解排队。
注意,CoDel完全没有使用队列长度区间阈值或者排队时间区间阈值,而是限制了一个理想的排队延时,同时给了一个排队延时万一超过理想排队延时后的良性收敛机会,只要在给定的机会内收敛了流量,便不会触发CoDel丢包,如果流量依旧不收敛,那么CoDel算法将会对队列里面的数据包所属的流量进行越来越严厉的惩罚,直至其收敛!所谓的越来越严厉的收敛就是越来越激烈地进行丢包,丢包的激烈程度与当前的丢包数正相关,从开始丢包开始计数,丢包数越多,丢包就越激烈,下面展示伪代码时我们会看到定量的公式,在这里仅仅知道这个定性的道理就好了。
以上我们可以看到一个自适应的过程,如果流量坚持着不收敛,那么它将被CoDel算法“逼迫”到要么收敛,要么大家都别过。CoDel算法不设置阈值范围进行控制,而是给一个良性收敛的时间窗口用于让流量悔过收敛,这样无论哪个流量均无法找到一个平衡,除了收敛到每个包排队延迟不超过5ms,没有任何别的出路。反观传统的RED算法,一个恶意抢带宽的流量会拼命占据队列缓存而不退让,最终在迫使其它的良性流量收敛了之后,该恶意流量可以调整其发送速率,巧妙地将BDP控制在以下的值:
RTT_max:采集到的最大RTT
RTT_min:采集到的最小RTT
BW_max:采集到的最大传输带宽
BDP = RTT_min * BW_max + (RTT_max - RTT_min) * BW_max
这将使得恶意竞速流量在队列长度的丢包阈值之间进行“合理判断钻空子”,然而几乎独占整个队列缓存并且持续长期独占,如果它不care丢包(毕竟可以靠附加的重传流量补偿),那么这个节点将会被恶意堵死!然而使用CoDel算法,恶意竞速流量将不会得逞!
......
本节的最后,我用一个时序图解析一下CoDel算法的运行过程:
当有恶意的竞速流量企图堵死节点队列的时候,它将会面临越来越严重的惩罚,直到其收敛!这就是CoDel算法的负反馈过程。
CoDel算法判断流量是否收敛的原则非常简单,只有一个,就是数据包的排队延迟小于target即可,这是恶意流量唯一可以钻空子的“平衡状态”,不过想象一下,默认target为5ms的情况下,恶意流量如何能保持“平衡”,完全占据这5ms的时间窗口呢?
我们假设恶意流量S巧妙控制了它的发送速率和发送量,使得它的数据包在队列中的时间正好处在target即5ms的边界下(这是很难的...),如果只要S一个流通过节点,这非常棒,S流达到了自己的目的,虽然这并没有什么意义!现在考虑多个流共享节点队列的情况。由于S流完全占据了5ms为界限的排队时间窗口,这必然会导致属于其它流的数据包排队延迟超过5ms,由于S流并不懂得退让,那么这个过程将持续,直到超过了CoDel算法给的“收敛机会”,即interval时间。此时会触发丢包...丢哪个流的包呢?丢多少呢?
CoDel算法最直接的丢包策略就是从队列中依次出队数据包并将其丢弃,那么一个流的数据包在队列里占比越多,丢它的数据包的可能性就越大,显然这个正在讨论的场景中会丢弃大量S流的包。下一个问题,丢多少呢?CoDel算法会持续不断的以越来越快的速度丢包,直到发现有数据包的排队延迟小于5ms了才停止,丢包速度与丢包量正相关,即丢包越多,丢包越快。
那么紧接着的问题就是,在什么情况下数据包的排队延迟会再次小于5ms呢?只有一种情况,那就是S流收敛了!
理解这个负反馈过程了吗?先来看一下负反馈和正反馈的通俗解释:
我们看到,在制造这个负反馈的过程中,需要一个正反馈过程来刺激,即丢包越多,丢包越快,用这种正反馈来加速负反馈的反应,达到快速收敛:
相对于传统的RED算法,我更倾向于部署简单直接的CoDel算法来进行队列管理,当竞速流量由于被狠狠地惩罚变得无利可图的时候,它们才会懂得收敛的意义,这是一种多方共赢的博弈,而不是零和博弈!
本节的要点在于,为了让负反馈尽快生效,需要一个正反馈来刺激,请先记住这个结论,下面展示伪代码的时候,会提到一个control_law例程,它展示了正反馈的过程。
本节结束!
我先给出CoDel伪代码的链接: http://queue.acm.org/appendices/codel.html
然后我简单分析一下这个代码。
我简化了上述链接中的代码,去掉了异常判断,假设场景如下:
1.节点拥有无限长容量的队列,且队列永不为空;
2.只有一个队列入口,即enque例程;
time_t drop_next; Time to drop next packet
uint32_t count; Packets dropped since going into drop state
flag_t dropping; Equal to 1 if in drop state
---------------------------------------------
time_t target = MS2TIME(5); Target queue delay (5 ms)
time_t interval = MS2TIME(100); Sliding minimum time window width (100 ms)
掌握了上述伪代码里蕴含的那个状态机,就理解了CoDel算法的实质。其实这个AQM机制是非常简单的,想理解原理的,直接看伪代码基本上不到10分钟就能搞定,然而任何简单的东西,其背后的思想却不是一两句话就能说清的,理解背后的思想和理解眼前的原理,其意义完全不同。
传统的TCP拥塞算法是对带宽实际情况无感知的,它们都是基于一个“数学上收敛的模型”,即AIMD模型运作的,在AI过程中,基本上都是盲目的探测,而MD过程又是过激地降速,这个过程往往会造成很多可用带宽的消耗或者说浪费,一方面丢包作为拥塞信号,重传数据包会消耗部分本来可以传输新数据的带宽,另一方面,在结束了MD过程后,一个新的缓慢AI的过程只有在丢包前夕的那一刻才能有效利用所有带宽,其余时刻都是谨慎又盲目的上探过程,剩余的空闲带宽便无法被利用。这便是传统拥塞算法的症结之根本。
由于这个症结的存在,排队现象是不可避免的!实际上,传统的TCP拥塞算法误用了节点的队列缓存。队列的存在会让传统的TCP拥塞算法误认为是剩余可用带宽,它们并不能意识到队列的存在,所以即便它们都是收敛的流量,CoDel算法也无法“匡正”它们的“错觉”。因此,在传统TCP拥塞算法上部署CoDel算法,依然会出现锯齿状的全局同步现象,事实上,这种现象是可以消除的,CoDel的本意也是在于消除这种现象。
BBR根治了传统TCP拥塞算法的症结。
BBR采集了时间窗口(用于老化数据样本)的历史中最大带宽,以及最小的RTT,并且在另一个时间窗口内“坚持使用该最小RTT”,这就意味着在一个时间窗口内,BBR估算的BDP是不变的,BBR由于采集到了真实的带宽和RTT数据并基于此数据调节发送速率,这便不再需要盲目探测的过程了。BBR采集到的最小RTT便是不排队的RTT,因此在正常情况下,队列缓存不会被使用,CoDel算法几乎不会触发丢包。
我们先来看下传统的TCP拥塞算法和BBR分别是怎么使用队列的:
在没有恶意的竞速流量,只存在BBR流量的情况下,如果在同一条链路上进入了一个新的流,那么BBR自身的Probe RTT机制会使得最终两条流收敛到均分带宽,如上图的结果。这是怎么做到的呢?我们知道在BBR坚持使用采集到的最小RTT时间超过默认的10s期间,没有采集到至少是持平或者更小的RTT,BBR会进入Probe RTT状态,将发送量减少为4个窗口,重新采集RTT,而此时由于已经有2个流共享同一链路了,BBR自身在退出Probe RTT后会避免形成队列,所以最终它们采集到的最小RTT均不会包括排队延迟,这是一件非常爽的事情。那么在此期间,CoDel的作用是什么呢?
你会发现,其实不用CoDel算法,BBR也依然可以收敛到不排队状态,期间可能会经历最多10s(默认配置)的轻微排队状态。好像是CoDel变得多此一举了。事实上,我觉得在纯BBR的情况下,CoDel存在的价值恰恰就在于为BBR提供一个良好环境,CoDel是BBR的保护者,而非限制者,也非监管者,CoDel保护BBR免受传统的TCP拥塞控制算法盲目探测之害,同时也在一定程度上阻止了恶意的竞速流量侵占宝贵的带宽。
CoDel旨在解决Bufferbloat,BBR也是解决了Bufferbloat,目标相同,效果自然相同,可以相当好的携手紧密配合。
CoDel (Controlled Delay Management) has three major innovations that distinguish it from prior AQMs. First, CoDel’s algorithm is not based on queue size, queue-size averages, queue-size thresholds, rate measurements, link utilization, drop rate or queue occupancy time. Starting from Van Jacobson’s 2006 insight, we used the local minimum queue as a more accurate and robust measure of standing queue. Then we observed that it is sufficient to keep a single-state variable of how long the minimum has been above or below the target value for standing queue delay rather than keeping a window of values to compute the minimum. Finally, rather than measuring queue size in bytes or packets, we used the packet-sojourn time through the queue. Use of the actual delay experienced by each packet is independent of link rate, gives superior performance to use of buffer size, and is directly related to the user-visible performance.
这就是双维度的CoDel算法,第一个维度在于“数据包排队多久是可以接受的”,第二个维度是“如果排队已经不可接受,这种不可接受能忍受多久”...
--------------------------------
----写于令屈原心如刀割的端午之夜
周末快乐!
就我自己了,于是在深夜里便可以随意的折腾点电子设备,写写文章,也是很爽的。由于最近工作实在是太忙,所有思考和整理的时间自然就少了很多,不管怎样,还是利用两个晚上吭哧出来了本文,也算是不容易。不管怎样,这个假期有点假。
本文接着上一篇文章,继续介绍队列管理和Bufferbloat相关的内容。
使用TSQ解决本地Bufferbloat
在上一篇文章《 TCP BBR算法中Pacing,cwnd,fq以及TSQ对RTT的影响》中,我分析了TSQ对本地Qdisc队列中TCP测量RTT的影响,又进一步分析了BBR算法是如何利用这一影响的。然而并没有给出一个总的框图来说明这一切结合在一起是如何运作的。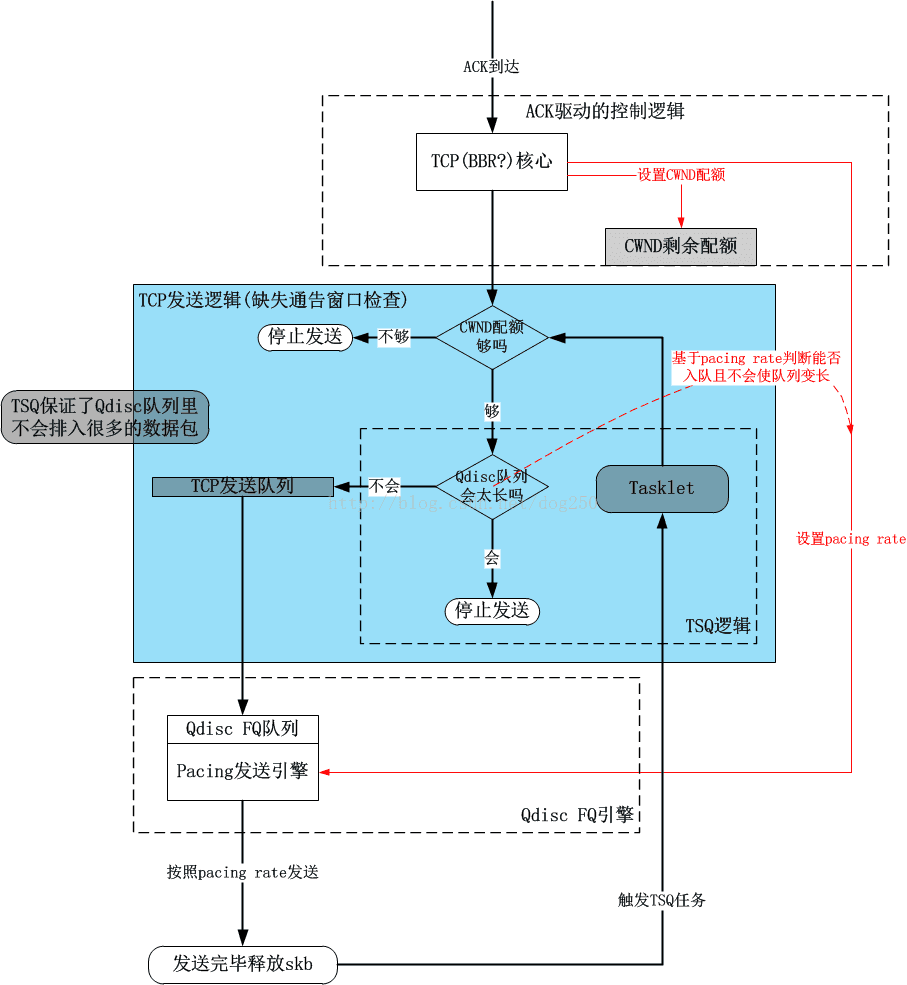
A number of bloat-fighting changes have gone into the kernel over the last year. The CoDel queue management algorithm works to prevent packets from building up in router queues over time. At a much lower level, byte queue limits put a cap on the amount of data that can be waiting to go out a specific network interface. Byte queue limits work only at the device queue level, though, while the networking stack has other places—such as the queueing discipline level—where buffering can happen. So there would be value in an implementation that could limit buffering at levels above the device queue.
Eric Dumazet's TCP small queues patch looks like it should be able to fill at least part of that gap. It limits the amount of data that can be queued for transmission by any given socket regardless of where the data is queued, so it shouldn't be fooled by buffers lurking in the queueing, traffic control, or netfilter code.
......
非本地队列的Bufferbloat解除
当TCP数据包离开了本地,在到达对端之前,会经过多跳的节点,每一个节点可以抽象成一个队列(我在这里就不扯排队论了,原理分析之前说过很多,可以去翻我之前的博客),那么这些节点只处理到协议的IP层,并不持有端到端的TCP连接信息,这意味着这些节点无法采用TSQ的方法来保证队列使用的高效性和公平性,那是不是就意味着端到端的TCP就可以对这些中间节点的队列丝毫无感呢?是不是意味着端到端的TCP就可以无节制地发包,听天由命地任由处置呢?当然不是!虽然中间节点对端到端的流量无感,但还是有多种队列管理策略可用,值得注意的是,如果队列满了,队列管理策略对到达的溢出当然是只能丢弃,但这并非意味着队列管理策略只能在队列满了之后才采取丢包动作,事实上,早在队列爆满之前,就要采取动作了。正是对“在什么时候丢包”,“丢哪些包”以及“丢多少包”这三个问题的不同回答,决定了队列管理策略之间的不同。
在分析一种叫做CoDel(Controlled Delay)队列管理算法之前,我再次罗嗦一遍队列是干什么的,队列不是干什么的。
0.多路统计复用的分组交换网络必须要有队列
只要是排队系统,因为固定的服务速率和符合泊松分布的到达速率之间存在瞬时差异(按照时间的积分是相同的,瞬时值是不同的),因此需要有一个队列作为缓冲。这个不多扯,排队理论中有详尽的分析。
1.吸收由于链路速率不匹配导致的暂时性良性突发
比如说TCP在慢启动阶段,并不知道网络的实际带宽承载力,因此可能会瞬时突发超过带宽承载力的数据包,此时需要一个队列来暂存这些超发的数据包。之所以中间节点保有如此的善意,完全在于它相信TCP的拥塞控制算法会紧随其后的降低超发量,这是一个信任造成的合作。至于说端到端的TCP如何来知道开始排队了,有很多种方法,比如可以观察RTT的梯度了解到RTT在持续增大,也可以通过测量速率不再随着发包量的增加而增加,另外还可以用经典的方法,即继续增加发包量,直到发现丢包后迅速降速。不管采用哪种手段,全在于TCP的收敛原则,即任何TCP拥塞控制算法都应该是收敛的,而不该是侵略性的。在符合这个收敛原则的世界里,基本不需要队列管理,因为队列和TCP流量可以自发地达到一个动态平衡。
我将符合收敛原则的TCP流量造成的突发称为 良性突发。
3.队列不用用来占据的
网络链路上有一个设备,该设备上配备了一个队列缓存,该队列缓存可以最多存储N个数据包,那是不是意味着作为端节点就一定要“充分利用”这块缓存呢?即将其填满,然后达到“100%的带宽利用率”。大错特错!所有不以上述1,2两点为基准的排队行为都是耍流氓。注意,队列缓存不是带宽的一部分。
我将不以上述1,2为基准的排队行为称为 恶性突发。
----------------------------
队列管理策略是针对恶意突发的!本文用以下的内容来阐述一下队列管理是如何对付恶意突发的!
对于UDP而言,它是原始带有侵略性的,或者对于那些所谓的TCP加速软件,它们会完全摒弃收敛原则,尽可能提高发送速度,针对这种流量,如果不加以管束,便会让互联网变得不再可用,按照自然商品经济的原则来看,劣币驱良币是必然的!道德丧失之后,往往就该法律出场了。
队列管理的目标不是杜绝排队,而是监管排队行为,一个好的队列管理算法的终极目标是要保证每一个数据包通过该队列的时间尽可能的小,即杜绝Bufferbloat。
----------------------------
那么如何设计一个合理的队列管理策略呢?这就衍生出一个单独的领域,即AQM。
AQM概述-传统RED与CoDel
CoDel算法只是诸多AQM策略算法中的一个,当然,它并不一定是全局最优的,但却是合理的。在我的眼里,CoDel算法要比大部分其它的队列算法要好,所以本文着重讨论这个算法。早先的RED算法可以在队列长度达到某个预设的阈值时进行一些随机的丢包(Random drop),由此旨在“提醒”各位TCP来降低发送速率,鉴于绝大部分的TCP的实现都是以丢包作为拥塞信号来做降窗降速处理的,所以RED在大多数情况下工作的很好。然而RED不是自适应的,它的问题如下:
1.丢包阈值如何设定?
RED基于队列长度来判断是否要丢包,队列长度取决于当前排队的包量,如果用排队的包量作为衡量是否丢包的标准,那么引入的排队延迟将和每个流的速率相关,同样长度的队列,如果出口速率快,那么引入的排队延迟就小,出口速率小,排队延迟就大。请注意队列管理的终极目标,是要保证排队时延尽可能小,解决Bufferbloat问题,至于说控制队列长度,充其量只是一种实现终极目标的手段而已。
因此,常规的RED采用的队列长度这个衡量是否丢包的这个标准并不合适。
2.丢包率如何设定?
即便采用队列长度作为衡量丢包的标准是合适的,那么下一个问题是丢多少包呢?
很显然的一个回答是采用固定的丢包率。那么如果队列持续在丢包长度阈值附近摆动的话,将无法很好的达到队列管理的终极目标。我们设队列长度阈值为L,恶意的突发流会持续地将队列填充到L的长度,尽可能减少自己的丢包概率,这种侵略行为将在很大程度上饿死良性流量。在这种情况下,常规RED算法无法很好地对持续的侵略行为进行持续的惩罚。
那么引入一个变化的丢包率呢?当然很好,但是实现却是复杂的,丢包率要如何与队列长度,时间等因素进行关联呢?甚至,队列的丢包阈值都可以是变化的,但这会进一步增加算法的复杂性
...
针对以上的问题,有三个明显的需求:
1.以排队延时本身作为衡量是否丢包的标准
直接瞄准队列管理的终极目标非常合理,即队列管理是为了减少数据包的排队时延,限制队列长度只是可能达到这个目标的一个手段,不用这个手段,还会有别的手段达到同样的目标,我们需要的是,要找一种手段,它比限制队列长度要更好地达到目标!
2.无需外界配置,自适应调整丢包率
有两个流派必须让大家知道,一个流派非常喜欢一切都要是可配置的,这是他们的信仰,另外一个流派则是一切都要自适应,无参数自动化运行,这也是一种信仰,讨论谁对谁错是没有意义的。问题是在什么场景下采用哪种信仰更适合。针对RED队列管理的问题,无疑自适应是合适的,在该场景下,配置化并不能动态适应不断变化的网络流量模型。
3.简单化
实现的简单性永远都是必要的,这是算法可以进一步进化调整所必需的要求。
CoDel的运作机制-对比传统RED
CoDel的运行仅仅需要两个参数,即target和interval:target:理想情况下,数据包的最长排队延时。
interval:在触发CoDel开始丢包前,持续的数据包排队时间超过target的最长忍耐时间。
CoDel算法并没有严格限制数据包在队列里面待的时间,即排队延时不超过target。而是给予了一个interval时间段的窗口,数据流可以在该时间窗口内观察到RTT的增加,进而采取收敛策略缓解排队。
注意,CoDel完全没有使用队列长度区间阈值或者排队时间区间阈值,而是限制了一个理想的排队延时,同时给了一个排队延时万一超过理想排队延时后的良性收敛机会,只要在给定的机会内收敛了流量,便不会触发CoDel丢包,如果流量依旧不收敛,那么CoDel算法将会对队列里面的数据包所属的流量进行越来越严厉的惩罚,直至其收敛!所谓的越来越严厉的收敛就是越来越激烈地进行丢包,丢包的激烈程度与当前的丢包数正相关,从开始丢包开始计数,丢包数越多,丢包就越激烈,下面展示伪代码时我们会看到定量的公式,在这里仅仅知道这个定性的道理就好了。
以上我们可以看到一个自适应的过程,如果流量坚持着不收敛,那么它将被CoDel算法“逼迫”到要么收敛,要么大家都别过。CoDel算法不设置阈值范围进行控制,而是给一个良性收敛的时间窗口用于让流量悔过收敛,这样无论哪个流量均无法找到一个平衡,除了收敛到每个包排队延迟不超过5ms,没有任何别的出路。反观传统的RED算法,一个恶意抢带宽的流量会拼命占据队列缓存而不退让,最终在迫使其它的良性流量收敛了之后,该恶意流量可以调整其发送速率,巧妙地将BDP控制在以下的值:
RTT_max:采集到的最大RTT
RTT_min:采集到的最小RTT
BW_max:采集到的最大传输带宽
BDP = RTT_min * BW_max + (RTT_max - RTT_min) * BW_max
这将使得恶意竞速流量在队列长度的丢包阈值之间进行“合理判断钻空子”,然而几乎独占整个队列缓存并且持续长期独占,如果它不care丢包(毕竟可以靠附加的重传流量补偿),那么这个节点将会被恶意堵死!然而使用CoDel算法,恶意竞速流量将不会得逞!
......
本节的最后,我用一个时序图解析一下CoDel算法的运行过程:
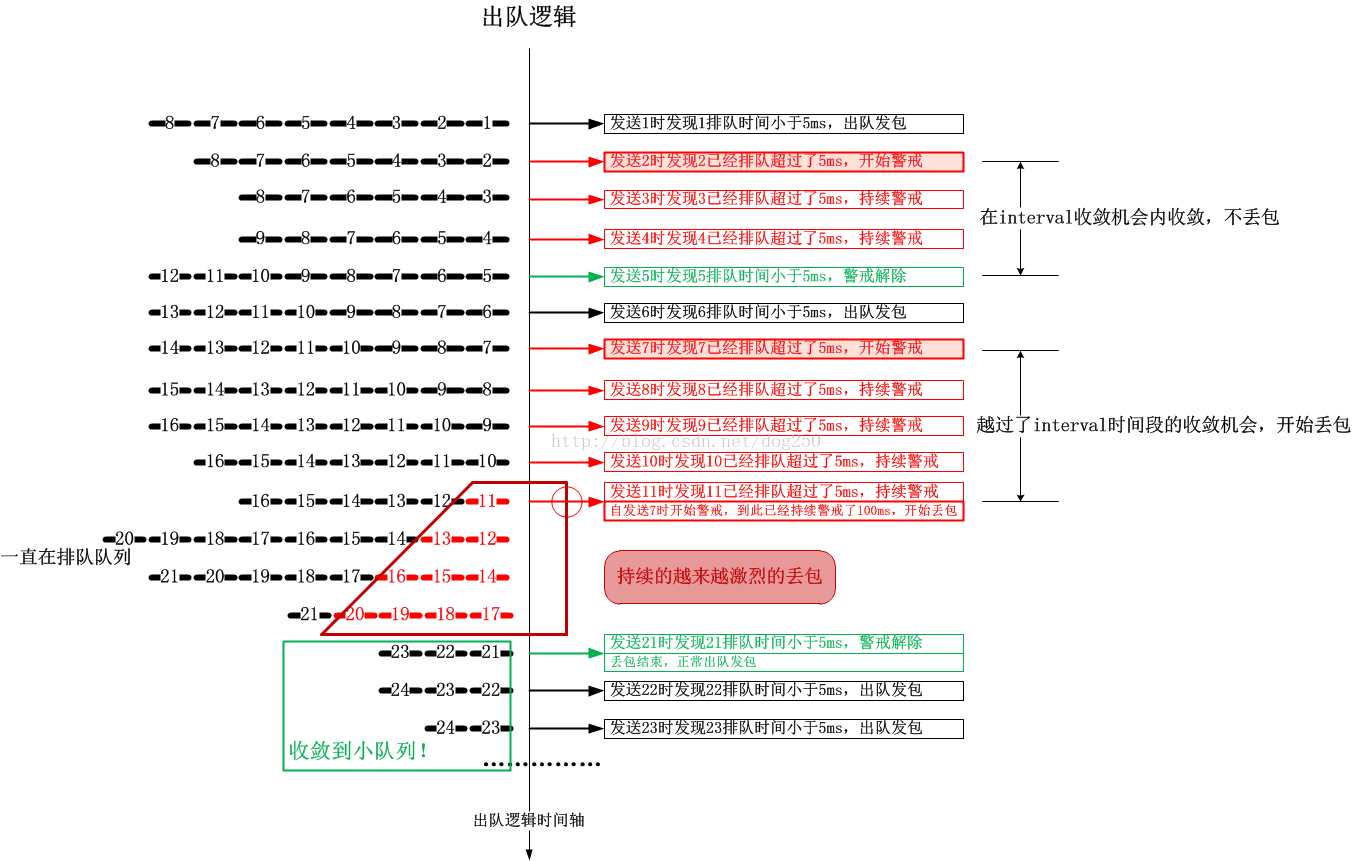
强调CoDel算法的负反馈过程
恕我直言,将竞速流量全部看作是不知收敛的恶意流量。当有恶意的竞速流量企图堵死节点队列的时候,它将会面临越来越严重的惩罚,直到其收敛!这就是CoDel算法的负反馈过程。
CoDel算法判断流量是否收敛的原则非常简单,只有一个,就是数据包的排队延迟小于target即可,这是恶意流量唯一可以钻空子的“平衡状态”,不过想象一下,默认target为5ms的情况下,恶意流量如何能保持“平衡”,完全占据这5ms的时间窗口呢?
我们假设恶意流量S巧妙控制了它的发送速率和发送量,使得它的数据包在队列中的时间正好处在target即5ms的边界下(这是很难的...),如果只要S一个流通过节点,这非常棒,S流达到了自己的目的,虽然这并没有什么意义!现在考虑多个流共享节点队列的情况。由于S流完全占据了5ms为界限的排队时间窗口,这必然会导致属于其它流的数据包排队延迟超过5ms,由于S流并不懂得退让,那么这个过程将持续,直到超过了CoDel算法给的“收敛机会”,即interval时间。此时会触发丢包...丢哪个流的包呢?丢多少呢?
CoDel算法最直接的丢包策略就是从队列中依次出队数据包并将其丢弃,那么一个流的数据包在队列里占比越多,丢它的数据包的可能性就越大,显然这个正在讨论的场景中会丢弃大量S流的包。下一个问题,丢多少呢?CoDel算法会持续不断的以越来越快的速度丢包,直到发现有数据包的排队延迟小于5ms了才停止,丢包速度与丢包量正相关,即丢包越多,丢包越快。
那么紧接着的问题就是,在什么情况下数据包的排队延迟会再次小于5ms呢?只有一种情况,那就是S流收敛了!
理解这个负反馈过程了吗?先来看一下负反馈和正反馈的通俗解释:
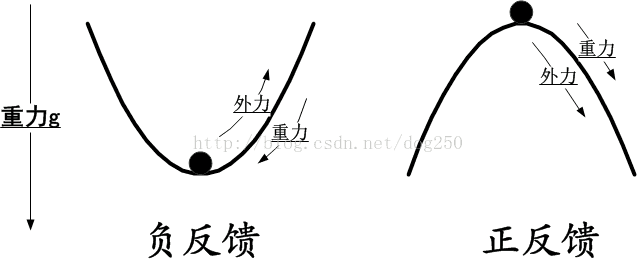
我们看到,在制造这个负反馈的过程中,需要一个正反馈过程来刺激,即丢包越多,丢包越快,用这种正反馈来加速负反馈的反应,达到快速收敛:
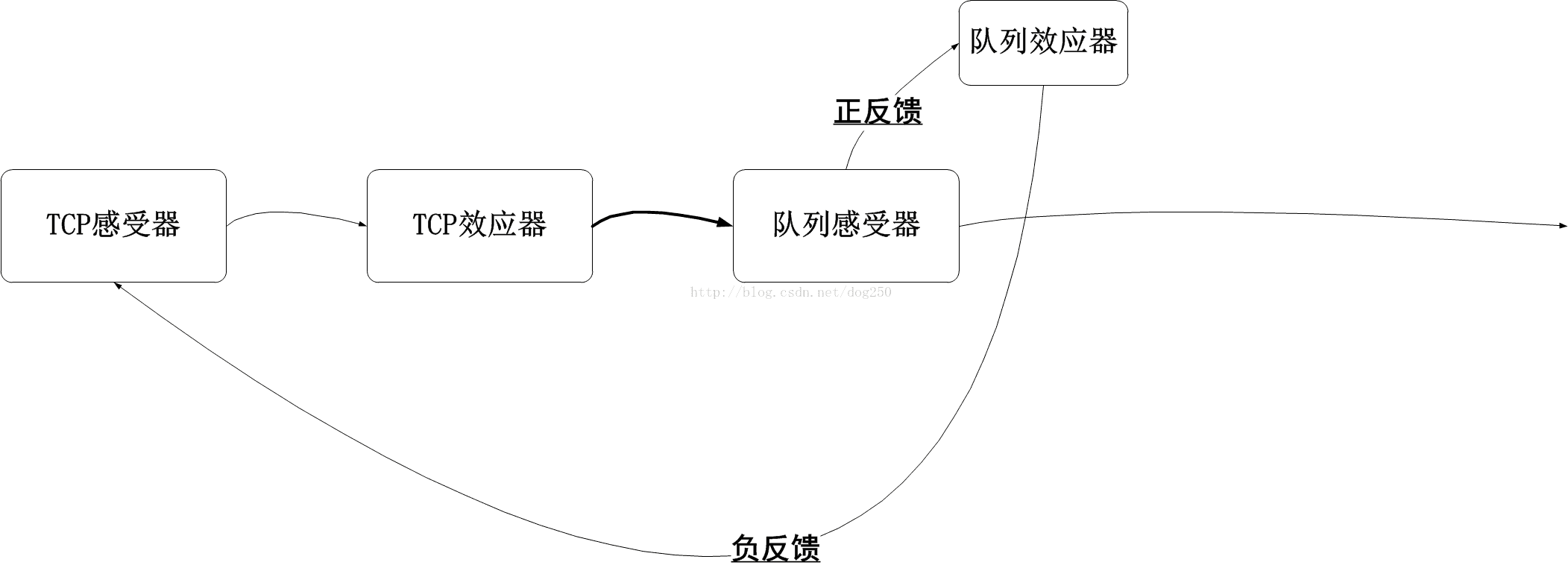
相对于传统的RED算法,我更倾向于部署简单直接的CoDel算法来进行队列管理,当竞速流量由于被狠狠地惩罚变得无利可图的时候,它们才会懂得收敛的意义,这是一种多方共赢的博弈,而不是零和博弈!
本节的要点在于,为了让负反馈尽快生效,需要一个正反馈来刺激,请先记住这个结论,下面展示伪代码的时候,会提到一个control_law例程,它展示了正反馈的过程。
本节结束!
Codel算法伪代码
如果在原理上看CoDel有些不直观,那么给出伪代码或许是更好的方式,因为它更直接。Talk is cheap,show me the code!我先给出CoDel伪代码的链接: http://queue.acm.org/appendices/codel.html
然后我简单分析一下这个代码。
我简化了上述链接中的代码,去掉了异常判断,假设场景如下:
1.节点拥有无限长容量的队列,且队列永不为空;
2.只有一个队列入口,即enque例程;
3.只有一个队列出口,即dequeue例程。
time_t drop_next; Time to drop next packet
uint32_t count; Packets dropped since going into drop state
flag_t dropping; Equal to 1 if in drop state
---------------------------------------------
time_t target = MS2TIME(5); Target queue delay (5 ms)
time_t interval = MS2TIME(100); Sliding minimum time window width (100 ms)
void codel_queue_t::enque(packet_t* pkt)
{
pkt->tstamp = clock();
queue_t::enque(pkt);
}
// 这个control_law例程决定了CoDel以何种速率进行丢包,可以看出它是进入丢包状态开始到当前为止丢包数量的一个函数,与丢包数量正相关,即丢的越多,丢的越快,用暂时正反馈
来触发流量的收敛,形成全局的负反馈。
time_t codel_queue_t::control_law(time_t t)
{
return t + interval / sqrt(count);
}
typedef struct {
packet_t* p;
flag_t ok_to_drop;
} dodeque_result;
dodeque_result codel_queue_t::dodeque(time_t now)
{
// 拉取队头的一个数据包P
dodeque_result r = {queue::deque(), 0};
// 计算P在队列中待了多久
time_t sojourn_time = now - r.p->tstamp;
// 如果P在队列中待的时间不超过5ms,则意味着它可以直接通过队列
if (sojourn_time < target) {
// went below so we'll stay below for at least interval
first_above_time = 0;
} else {
// 如果P在队列里的时间大于5ms了,此时分两种情况:
// 1).如果这是第一个在队列里待的时间超过5ms的包,只是记录该时间戳,作为检查的开始。
// 2).如果已经处在检查阶段,那么判断检查期是否超过了interval,即100ms,若是,则开始丢包。
if (first_above_time == 0) { // 情况1
first_above_time = now + interval;
} else if (now >= first_above_time) { // 情况2
r.ok_to_drop = 1;
}
}
return r;
}
packet_t* codel_queue_t::deque()
{
time_t now = clock();
dodeque_result r = dodeque();
if (dropping) {
if (! r.ok_to_drop) { // 如果结束了丢包状态,则P可以直接通过。
dropping = 0;
} else if (now >= drop_next) {
// 这个while循环体现了CoDel以越来越快的速度丢包的逻辑
while (now >= drop_next && dropping) {
drop(r.p);
++count;
r = dodeque();
if (! r.ok_to_drop)
// 状态机转换
dropping = 0;
else
// 参见关于control_law例程的注释
drop_next = control_law(drop_next);
}
}
} else if (r.ok_to_drop) {
drop(r.p);
r = dodeque();
dropping = 1;
count = 1;
drop_next = control_law(now);
}
return (r.p);
}掌握了上述伪代码里蕴含的那个状态机,就理解了CoDel算法的实质。其实这个AQM机制是非常简单的,想理解原理的,直接看伪代码基本上不到10分钟就能搞定,然而任何简单的东西,其背后的思想却不是一两句话就能说清的,理解背后的思想和理解眼前的原理,其意义完全不同。
CoDel算法与TCP BBR
和传统的TCP拥塞算法相比,BBR可以更好地与CoDel进行适配。本节好好说说这个事。传统的TCP拥塞算法是对带宽实际情况无感知的,它们都是基于一个“数学上收敛的模型”,即AIMD模型运作的,在AI过程中,基本上都是盲目的探测,而MD过程又是过激地降速,这个过程往往会造成很多可用带宽的消耗或者说浪费,一方面丢包作为拥塞信号,重传数据包会消耗部分本来可以传输新数据的带宽,另一方面,在结束了MD过程后,一个新的缓慢AI的过程只有在丢包前夕的那一刻才能有效利用所有带宽,其余时刻都是谨慎又盲目的上探过程,剩余的空闲带宽便无法被利用。这便是传统拥塞算法的症结之根本。
由于这个症结的存在,排队现象是不可避免的!实际上,传统的TCP拥塞算法误用了节点的队列缓存。队列的存在会让传统的TCP拥塞算法误认为是剩余可用带宽,它们并不能意识到队列的存在,所以即便它们都是收敛的流量,CoDel算法也无法“匡正”它们的“错觉”。因此,在传统TCP拥塞算法上部署CoDel算法,依然会出现锯齿状的全局同步现象,事实上,这种现象是可以消除的,CoDel的本意也是在于消除这种现象。
BBR根治了传统TCP拥塞算法的症结。
BBR采集了时间窗口(用于老化数据样本)的历史中最大带宽,以及最小的RTT,并且在另一个时间窗口内“坚持使用该最小RTT”,这就意味着在一个时间窗口内,BBR估算的BDP是不变的,BBR由于采集到了真实的带宽和RTT数据并基于此数据调节发送速率,这便不再需要盲目探测的过程了。BBR采集到的最小RTT便是不排队的RTT,因此在正常情况下,队列缓存不会被使用,CoDel算法几乎不会触发丢包。
我们先来看下传统的TCP拥塞算法和BBR分别是怎么使用队列的:
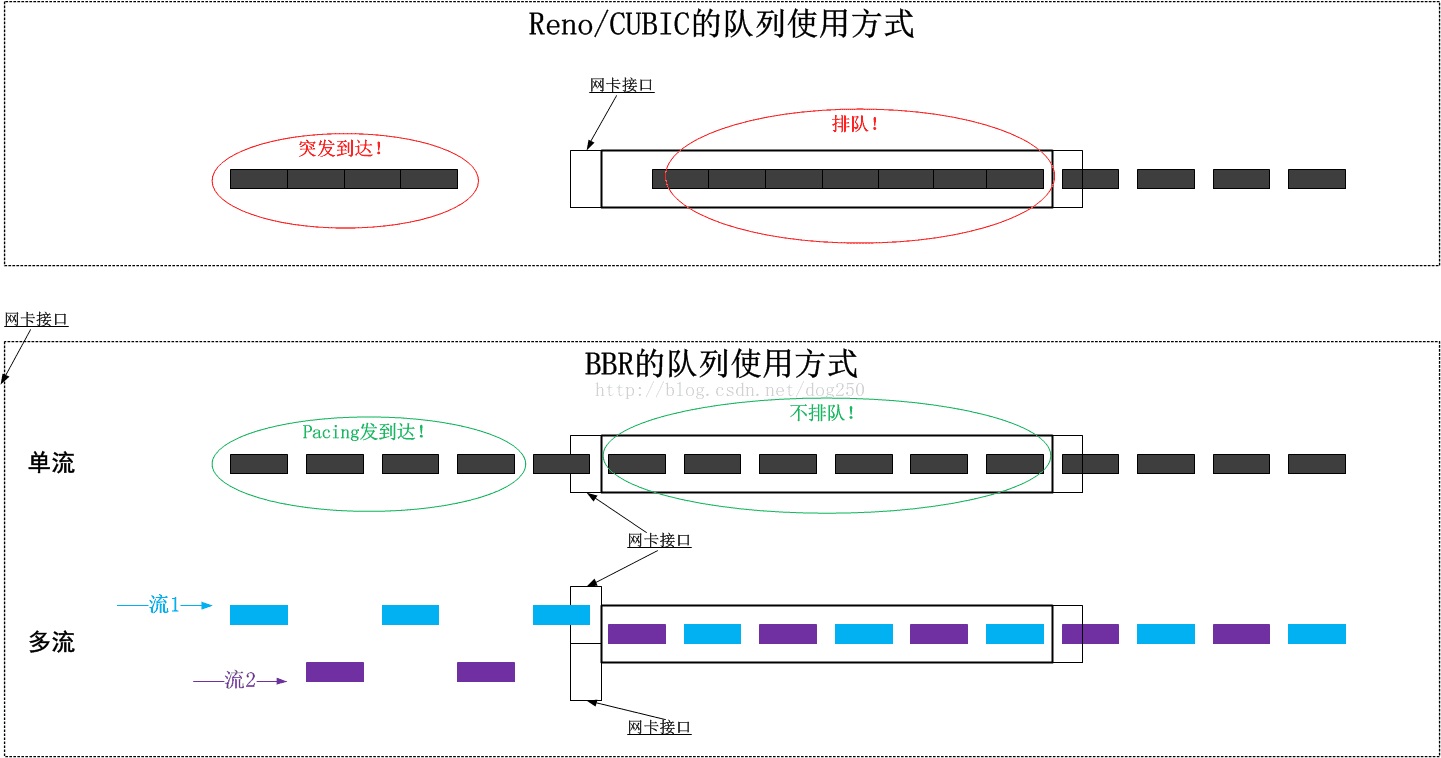
在没有恶意的竞速流量,只存在BBR流量的情况下,如果在同一条链路上进入了一个新的流,那么BBR自身的Probe RTT机制会使得最终两条流收敛到均分带宽,如上图的结果。这是怎么做到的呢?我们知道在BBR坚持使用采集到的最小RTT时间超过默认的10s期间,没有采集到至少是持平或者更小的RTT,BBR会进入Probe RTT状态,将发送量减少为4个窗口,重新采集RTT,而此时由于已经有2个流共享同一链路了,BBR自身在退出Probe RTT后会避免形成队列,所以最终它们采集到的最小RTT均不会包括排队延迟,这是一件非常爽的事情。那么在此期间,CoDel的作用是什么呢?
你会发现,其实不用CoDel算法,BBR也依然可以收敛到不排队状态,期间可能会经历最多10s(默认配置)的轻微排队状态。好像是CoDel变得多此一举了。事实上,我觉得在纯BBR的情况下,CoDel存在的价值恰恰就在于为BBR提供一个良好环境,CoDel是BBR的保护者,而非限制者,也非监管者,CoDel保护BBR免受传统的TCP拥塞控制算法盲目探测之害,同时也在一定程度上阻止了恶意的竞速流量侵占宝贵的带宽。
CoDel旨在解决Bufferbloat,BBR也是解决了Bufferbloat,目标相同,效果自然相同,可以相当好的携手紧密配合。
CoDel AQM算法总结
本文的最后,引用一段来自《 Nichols, Jacobson: Controlling Queue Delay》的一段精确描述总结一下CoDel算法:CoDel (Controlled Delay Management) has three major innovations that distinguish it from prior AQMs. First, CoDel’s algorithm is not based on queue size, queue-size averages, queue-size thresholds, rate measurements, link utilization, drop rate or queue occupancy time. Starting from Van Jacobson’s 2006 insight, we used the local minimum queue as a more accurate and robust measure of standing queue. Then we observed that it is sufficient to keep a single-state variable of how long the minimum has been above or below the target value for standing queue delay rather than keeping a window of values to compute the minimum. Finally, rather than measuring queue size in bytes or packets, we used the packet-sojourn time through the queue. Use of the actual delay experienced by each packet is independent of link rate, gives superior performance to use of buffer size, and is directly related to the user-visible performance.
这就是双维度的CoDel算法,第一个维度在于“数据包排队多久是可以接受的”,第二个维度是“如果排队已经不可接受,这种不可接受能忍受多久”...
--------------------------------
----写于令屈原心如刀割的端午之夜
周末快乐!














 2854
2854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









