






初识TUN/TAP虚拟网卡是因为OpenVPN,至今已有八个年头了,后来断断续续跟这块网卡打交道,从OpenVPN,到用户态协议栈,再到packetdrill。不管怎么说,我觉得这块虚拟网卡是那种可以让人眼前一亮的东西,小巧,简单,用它可以做很多比较复杂的事情。
也因此,我曾经几乎没有关注过它的性能。随它去吧,毕竟就这么个小东西,怎么指望它能匹敌那些个物理网卡,正如没人会指望netcat跑出G级线速却又不失其可玩性一样…到了后来,当我开始关注它的性能的时候,我也早已不再做OpenVPN相关的工作了,最近一次是在大约一个月前搞packetdrill并发改造的时候,发现了TUN/TAP网卡传输的一个热点,深究了一下,得出了结论,然后最近跟两位朋友的技术交流中,又get到两个点,所以就写这篇作文备忘以记之。
TUN/TAP网卡的Lockless
不管什么类型的网卡,其发包时都要经过dev_queue_xmit函数,其中我们注意以下片段:
int dev_queue_xmit(struct sk_buff *skb)
{
if (dev->flags & IFF_UP) {
int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) {
if (__this_cpu_read(xmit_recursion) > RECURSION_LIMIT)
goto recursion_alert;
// 注意!注意!
HARD_TX_LOCK(dev, txq, cpu);
... // 传输核心逻辑
HARD_TX_UNLOCK(dev, txq);
} else {
/* Recursion is detected! It is possible,
...
}
...
}注意到HARD_TX_LOCK和HARD_TX_UNLOCK,它们的实现如下:
#define HARD_TX_LOCK(dev, txq, cpu) { \
if ((dev->features & NETIF_F_LLTX) == 0) { \
__netif_tx_lock(txq, cpu); \
} \
}
#define HARD_TX_UNLOCK(dev, txq) { \
if ((dev->features & NETIF_F_LLTX) == 0) { \
__netif_tx_unlock(txq); \
} \
}在数据通路上拦截两个这样的调用,在没有启用Lockless的情况下,在多核心同时像一个网卡队列传输数据的时候,传输逻辑无疑被串行化了。这便是我在测试订制化packetdrill的时候,找到的那个热点。于是想办法要移掉它!顺便说一句,之所以会有一个NETIF_F_LLTX标记作为网卡的features,是因为它确实是可配置的,一般的实现了硬件队列的物理网卡在硬件层面会有机制保护数据包从SMP并行下来而不冲突,但是也有在硬件层面没有实现该features的网卡,为了能绝对安全保护队列SMP不冲突,引出这个NETIF_F_LLTX features,如果你的网卡能保证安全,就set它,如果不能,则内核函数dev_queue_xmit帮你保证SMP安全性,显然TUN/TAP网卡自己是能保证队列安全的,因此是要set上NETIF_F_LLTX 这个flag的。
非常幸运,在4.x等高版本内核上,这个热点已经不存在了!社区代码已经修复了这个“bug”(如果能称为bug的话…),详情参见:
[net-next] tun: don’t require serialization lock on tx:http://patchwork.ozlabs.org/patch/610532/
这个问题其实非常简单,解决方案也非常直观。我很后悔之前搞OpenVPN性能优化的时候没有get到这个点!非常之遗憾!
关于这个话题,忍不住多说几句。还记得IMQ这个好玩的driver吗?它的目标是实现ingress的qdisc,但是这个IMQ需要重新patch内核,使人不得开心颜,于是又出现一个IFB,关于这两个小玩意儿参见:
Linux下使用虚拟网卡的ingress流控(入口流控):https://blog.csdn.net/dog250/article/details/17202199
Linux TC的ifb原理以及ingress流控:https://blog.csdn.net/dog250/article/details/40680765
IMQ的项目地址:https://github.com/imq
我曾经说IMQ和IFB有一个单通道瓶颈,说的就是这个关于NETIF_F_LLTX标记的热点,但我却忽略了TUN/TAP,该打该打!此外,关于VLAN slave,曾经也有这个问题,但是已经修复了。
看来,Linux kernel协议栈实现里遍布各地的lock需要清理的还真不少,这种工作统一做起来完全就是体力活,也就只能见招拆招了。类似的问题还有nf_conntrack里面那个unconfirmed list的全局spinlock修正为per cpu的lock,以及nf_nat里的全局spinlock修正为per conntrack的lock,这一切貌似一个lock分层认领接管的过程,也就是最终会形成一个层级结构,总之,原则就是谁的逻辑谁的lock,lock不委托,最终形成I一个“附庸的附庸不是我的附庸,领主的领主不是我的领主”这样一个内核生态系统。
OK,下一个话题。
TUN/TAP网卡的mmap
就在前几天,跟朋友聊天,问我为什么TUN/TAP没有做mmap。在我的论述之前,先贴一个讨论:(TUN/TAP/character device read()/write() performance)https://www.spinics.net/lists/newbies/msg16816.html
至于我的看法,我觉得有以下的原因。
- 动机上讲,我觉得TUN/TAP本身并没有承载什么高性能应用;
- 影响上讲,mmap仅仅暴露一块内存,应用开发者要自己操作ring buffer,其API友好型远不如UNIX文件IO接口;
- 效果上讲,TUN/TAP底层并非携带DMA功能的硬件,因此还是免不了skb往ring buffer的内存拷贝。
当初2013年底折腾着将OpenVPN数据通道往内核态移植的时候,做过一版TUN/TAP的mmap,然而当时看来收益不是很明显,就没有持续(搞不好就是那个Lockless在捣蛋,只是当时的精力在OpenVPN本身…),现在看来我是不是要重新审视一下了呢?如上一个小节所述,传输热点已经被Lockless消除了,这下应该可以放手大干了。嗯。
其实实现TUN/TAP的mmap也不难,建议移植Linux 4.14版本的packet mmap实现机制,因为这个版本中实现了比较完善的receive ring buffer(rx_ring)以及transmit ring buffer(tx_ring),而在之前的版本中则只实现rx_ring。实现的细节请参阅:
packet mmap文档:file://$kernelsource/documentation/networking/packet_mmap.txt
在4.14的版本中,transmit路径实现还是有点美中不足,它是通过一个timer触发实际的发送的,这是典型的用时延换吞吐的交易,其实采用某种kernel busy polling更加好一些。
本节不是介绍如何移植packet mmap到TUN/TAP的,而是想说明TUN/TAP支持mmap这件事其实是不难的,时间倒回到2013年底,事情将发生变化。接下来的内容,我实现一个超级简化版的TUN/TAP mmap,并且在超级简单的TUN/TAP demo上可用,该demo就是simpletun:https://github.com/gregnietsky/simpletun
为了实现mmap,首先创建一个数据结构,即ring buffer:
#define RB_ORDER 5
// 由于要填充一些元数据,packet size要超过1500咯
#define PKG_SIZE 1600
#define CAP_SIZE (PAGE_SIZE*(1<<RB_ORDER)/PKG_SIZE)
struct tun_ring_buffer {
unsigned char *buffer;
// head表示当前的write指针,以PKG,即1600为步长索引
int head;
};其中,buffer一共有 2RB_ORDER 2 R B _ O R D E R 个page,即32个page!连续的32个page组成了一个ring buffer,其中每PKG_SIZE为一个block,head字段按照block为单位来索引。每一个block的结构如下:
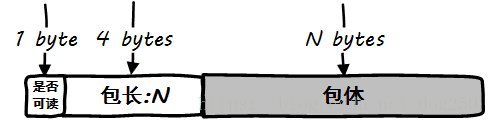
用户态使用的时候,也按照相同的规则解析使用即可。
基本就没有什么多说的了,直接给个patch即OK。内核代码基于:
root@debian:/home/zhaoya/mod# uname -r
4.9.0-3-amd64本patch仅仅实现了rx路径(receive path)的ring buffer mmap,对于tx路径(transmit path)的ring buffer mmap没有做。首先给出内核drivers/net/tun.c的patch
--- net/tun.c 2018-05-22 05:27:32.630541948 -0400
+++ tun.c 2018-05-22 05:23:11.997274134 -0400
@@ -143,6 +143,17 @@
u32 rx_frame_errors;
};
+
+#define RB_ORDER 5
+#define PKG_SIZE 1600
+#define CAP_SIZE (PAGE_SIZE*(1<<RB_ORDER)/PKG_SIZE)
+
+struct tun_ring_buffer {
+ unsigned char *buffer;
+ int head;
+};
+
+
/* A tun_file connects an open character device to a tuntap netdevice. It
* also contains all socket related structures (except sock_fprog and tap_filter)
* to serve as one transmit queue for tuntap device. The sock_fprog and
@@ -169,6 +180,7 @@
struct list_head next;
struct tun_struct *detached;
struct skb_array tx_array;
+ struct tun_ring_buffer *ring_buffer;
};
struct tun_flow_entry {
@@ -848,11 +860,17 @@
int txq = skb->queue_mapping;
struct tun_file *tfile;
u32 numqueues = 0;
+ struct tun_ring_buffer *rb;
+ unsigned char *mmap_addr;
+ char *readable;
+ int *pkglen;
rcu_read_lock();
tfile = rcu_dereference(tun->tfiles[txq]);
numqueues = ACCESS_ONCE(tun->numqueues);
+ rb = tfile->ring_buffer;
+
/* Drop packet if interface is not attached */
if (txq >= numqueues)
goto drop;
@@ -911,6 +929,20 @@
if (skb_array_produce(&tfile->tx_array, skb))
goto drop;
+
+ mmap_addr = &rb->buffer[PKG_SIZE*rb->head];
+
+ skb_copy_bits(skb, 0, (char *)mmap_addr + sizeof(char) + sizeof(int), skb->len);
+ readable = (char *)mmap_addr;
+ *readable = 1;
+ mmap_addr += sizeof(char);
+ pkglen = (int *)mmap_addr;
+ *pkglen = skb->len;
+
+ rb->head++; // 值得注意,这里实现的是,对write而言,要先write操作再原子increase index!更好的实现如tpacket_rcv中所述,获取free slot后直接原子递增index
+ if (rb->head > CAP_SIZE)
+ rb->head = 0;
+
/* Notify and wake up reader process */
if (tfile->flags & TUN_FASYNC)
kill_fasync(&tfile->fasync, SIGIO, POLL_IN);
@@ -2327,6 +2359,7 @@
{
struct net *net = current->nsproxy->net_ns;
struct tun_file *tfile;
+ struct tun_ring_buffer *rb;
DBG1(KERN_INFO, "tunX: tun_chr_open\n");
@@ -2349,19 +2382,61 @@
tfile->sk.sk_write_space = tun_sock_write_space;
tfile->sk.sk_sndbuf = INT_MAX;
+ sock_set_flag(&tfile->sk, SOCK_ZEROCOPY);
+
+ rb = kmalloc(sizeof(struct tun_ring_buffer), GFP_KERNEL);
+ if (rb == NULL) {
+ printk("Alloc rb failed\n");
+ return -ENOMEM;
+ }
+ rb->head = 0;
+ rb->buffer = (unsigned char *)__get_free_pages(GFP_KERNEL, RB_ORDER);
+
+ if (rb->buffer == NULL) {
+ printk("Alloc rb failed\n");
+ return -ENOMEM;
+ }
+ memset(rb->buffer, 0, PAGE_SIZE*(1<<RB_ORDER));
+ tfile->ring_buffer = rb;
+
file->private_data = tfile;
INIT_LIST_HEAD(&tfile->next);
- sock_set_flag(&tfile->sk, SOCK_ZEROCOPY);// 手误,这行并不该去掉!
-
return 0;
}
static int tun_chr_close(struct inode *inode, struct file *file)
{
struct tun_file *tfile = file->private_data;
+ struct tun_ring_buffer *rb = tfile->ring_buffer;
tun_detach(tfile, true);
+ free_pages((unsigned long)rb->buffer, RB_ORDER);
+ kfree(rb);
+
+ return 0;
+}
+
+int tun_chr_mmap(struct file *file, struct vm_area_struct *vma)
+{
+ struct tun_ring_buffer *rb;
+ struct tun_file *tfile = file->private_data;
+ int i;
+ void *addr;
+ unsigned long start, end;
+
+ rb = (struct tun_ring_buffer *)tfile->ring_buffer;
+ addr = rb->buffer;
+ start = vma->vm_start;
+ end = vma->vm_end;
+
+ for (i = 0; i < 1<<RB_ORDER && start + PAGE_SIZE <= end; i++) {
+ if(remap_pfn_range(vma, start, virt_to_phys(addr)>>PAGE_SHIFT, PAGE_SIZE, vma->vm_page_prot)) {
+ return -EAGAIN;
+ }
+ addr += PAGE_SIZE;
+ start += PAGE_SIZE;
+ }
return 0;
}
@@ -2403,6 +2478,7 @@
#ifdef CONFIG_PROC_FS
.show_fdinfo = tun_chr_show_fdinfo,
#endif
+ .mmap = tun_chr_mmap,
};
static struct miscdevice tun_miscdev = {然后再看下simpletun的patch:
--- simpletun-master/simpletun.c 2012-12-11 06:20:59.000000000 -0500
+++ simpletun.c.new 2018-05-22 05:13:31.829988897 -0400
@@ -36,6 +36,7 @@
#include <sys/time.h>
#include <errno.h>
#include <stdarg.h>
+#include <sys/mman.h>
/* buffer for reading from tun/tap interface, must be >= 1500 */
#define BUFSIZE 2000
@@ -43,6 +44,9 @@
#define SERVER 1
#define PORT 55555
+#define RB_ORDER 5
+#define PKG_SIZE 1600
+
int debug;
char *progname;
@@ -187,6 +191,8 @@
socklen_t remotelen;
int cliserv = -1; /* must be specified on cmd line */
unsigned long int tap2net = 0, net2tap = 0;
+ long page_size = sysconf(_SC_PAGE_SIZE);
+ char *mmap_addr;
progname = argv[0];
@@ -256,6 +262,12 @@
exit(1);
}
+ mmap_addr = mmap(NULL, page_size*(1<<RB_ORDER), PROT_READ|PROT_WRITE, MAP_SHARED, tap_fd, 0);
+ if (mmap_addr == NULL) {
+ perror("mmap()");
+ exit (1);
+ }
+
if(cliserv == CLIENT) {
/* Client, try to connect to server */
@@ -331,8 +343,23 @@
if(FD_ISSET(tap_fd, &rd_set)) {
/* data from tun/tap: just read it and write it to the network */
+ static int head = -1;
+ unsigned char *addr;
+ char *readable;
- nread = cread(tap_fd, buffer, BUFSIZE);
+ head ++; // 值得注意,对于read,要先原子increase index再实际read操作
+ if (head > page_size*(1<<RB_ORDER)/PKG_SIZE)
+ head = 0;
+ do { /* 这里采用了busy poll+seqlock(顺序锁)的原理 */
+ addr = &mmap_addr[PKG_SIZE*head];
+ readable = (char*)addr;
+ asm ("rep; nop");
+ } while (*readable == 0);
+
+ *readable = 0;
+ addr += sizeof(char);
+ nread = *(int *)addr;
+ addr += sizeof(int);
tap2net++;
do_debug("TAP2NET %lu: Read %d bytes from the tap interface\n", tap2net, nread);
@@ -340,7 +367,7 @@
/* write length + packet */
plength = htons(nread);
nwrite = cwrite(net_fd, (char *)&plength, sizeof(plength));
- nwrite = cwrite(net_fd, buffer, nread);
+ nwrite = cwrite(net_fd, addr, nread);
do_debug("TAP2NET %lu: Written %d bytes to the network\n", tap2net, nwrite);
}非常简单的一个patch,即可让TUN/TAP实现mmap。写的不好,凑合着能用。这里介绍一个通用的内核ring buffer框架:
https://www.mail-archive.com/linux-scsi@vger.kernel.org/msg05401.html
基于这个实现mmap会更帅吧。
但这不是我想表达的,我想表达的是另外一层意思。
注意patch中的skb_copy_bits这个调用,这个调用事实上是把本应该由skb往用户态read调用缓冲区的拷贝提前到hard-xmit回调中往ring buffer拷贝,仅仅可能节省了一次切换开销(如果用户态正在busy polling的话,则无需唤醒/切换,如果用户态没有在busy polling,那么唤醒/切换还是必须的!),内存拷贝的开销并没有省却。
这一点和物理网卡不一致。物理网卡可以通过DMA机制可以直接将收到的数据包从网卡mem无CPU开销地直接传输到系统mem,而该系统mem是mmap到用户态的,用户态便可以直接操作该mem,从网卡收到数据包到用户进程操作该数据包,全程无需任何数据拷贝。虚拟网卡则无法做到这一点,因为虚拟网卡没有硬件辅助来完成类似DMA的功能。
因此,为类似TUN/TAP这类虚拟网卡实现mmap的收益将会大打折扣,好处显然是存在的,但是收益值不值得去付出,就要看意愿了。
TUN/TAP是实现用户态协议栈的一种经由方式,比如uIP,lwIP这种就是用TUN/TAP实现的,但是在性能上,和物理网卡直接使用ring buffer mmap的netmap,DPDK还是有本质区别的。站在某种实现者的角度,其实TUN/TAP本身和netmap/DPDK的mmap才应该是并列的存在,它们都是把裸数据包从内核态交给用户态的一种路由方式,仅此而已。
物理网卡的ring buffer操作与虚拟网卡的异同
我们来看一下一般的物理网卡是如何利用DMA来实现高效数据包传输的。
首先看一个图,下图展示了数据包到达物理网卡后通过DMA传输到系统内存的逻辑:
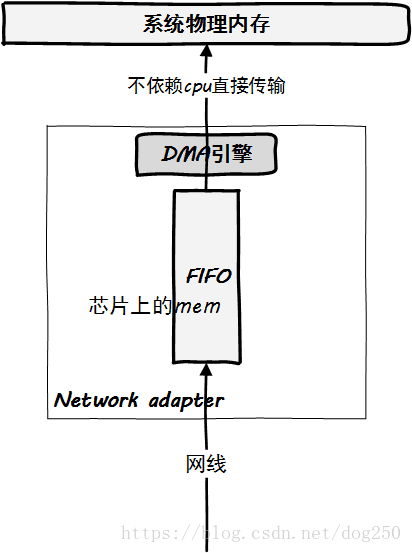
DMA是一个硬件逻辑,数据传输到系统物理内存的过程中,全程不需要CPU的干预,除了占用总线之外(期间CPU不能使用总线),没有任何额外开销。
接下来我们看下当数据包已经通过DMA到达物理内存后,操作系统能做什么。
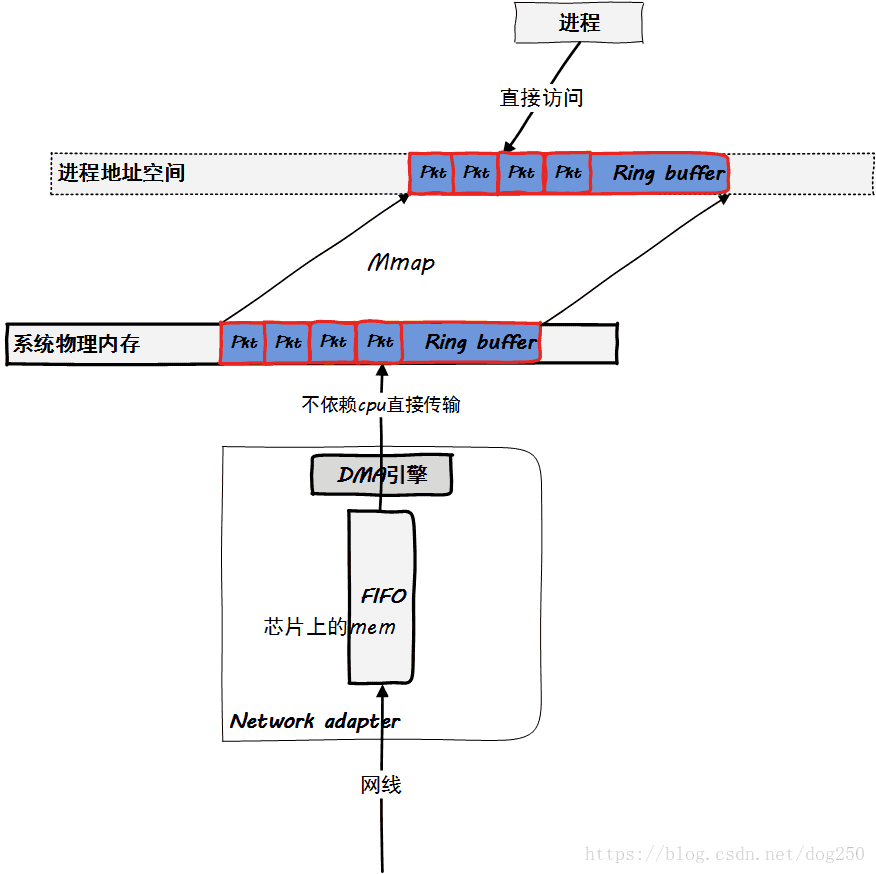
直接将数据包所在的ring buffer mmap到用户态
如下图所示的逻辑:
用户态进程可以直接touch被mmap到进程地址空间的ring buffer,取出并处理数据包,全程没有任何内存拷贝。这便是netmap/DPDK的方式,这也是用户态协议栈实现的通用方式。值得注意的是,用户态访问的是裸数据包,这也就意味着它没有经过协议栈的加工处理,所有这一切都要用户态进程自己完成。依次通过内核协议栈处理ring buffer中的每一个数据包
如下图所示的逻辑:
这也是标准的内核协议栈的处理方式。对于很多人而言,已经熟悉得不能再熟悉了,这里就不再赘述了。
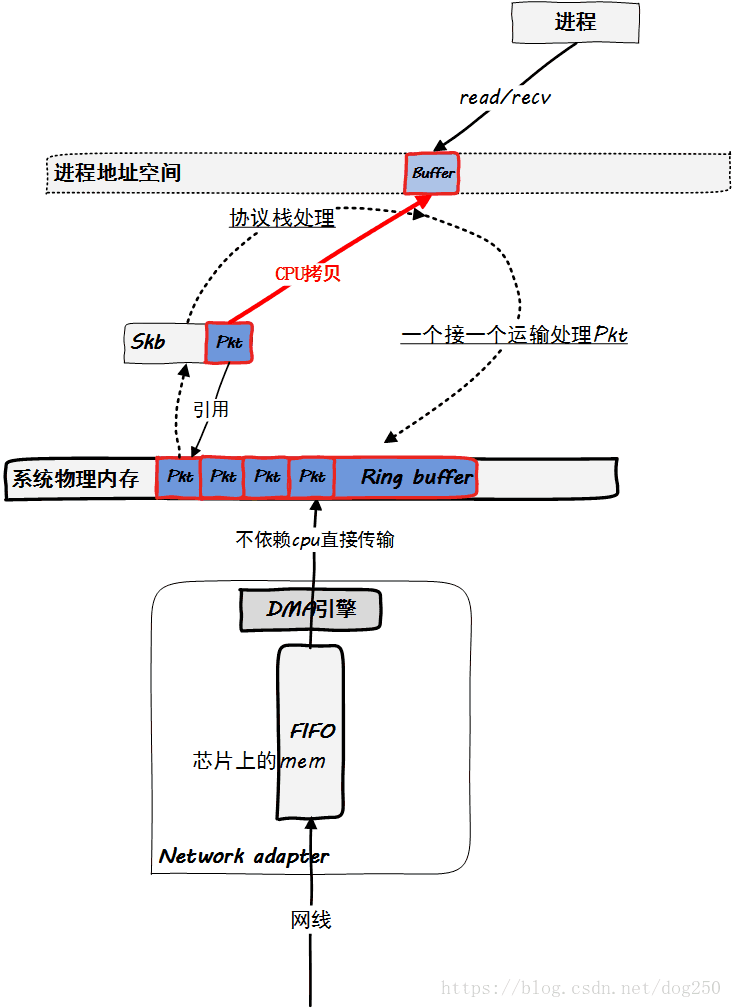
在上述内核协议栈处理过程中,请注意skb的角色。它只是一个数据包载体,即运载数据包从ring buffer到用户态进程buffer的一个容器,期间协议栈将直接处理这个容器实现协议的逻辑。skb类似一辆从码头运货到收货地的卡车或者一个邮差。
现在的问题是,每当需要运输一个packet到上层时,这个skb载体从哪里来。我们看看下面的两种方式:
- 每当需要skb运输packet的时候,从slab/slub系统分配
可以参见Linux的Intel e1000驱动,即这种方式。 - ring buffer中的每一个Pkt slot均内置一个预先分配好的skb
很遗憾,虽然我期望是这种方式,但是即便是e1000e,igb均不是这种实现。
很显然,上述第二个实现方式是最有效率的,因为无需付出从slab/slub分配skb的开销,但是显然这也是空间还来的时间,假设一个ring buffer有1024个slot,即可以容纳1024个数据包,那么就意味着需要提前预分配1024个skb,分别指定给这1024个slot,想象中的结构体以及初始化逻辑如下:
struct ring_buffer {
struct buffer_slot slot[1024];
int next_read;
int next_free;
};
struct buffer_slot {
void *dma_address; // 容纳数据包
struct sk_buff *skb; // 指示运输该数据包的容器
};
...
void init()
{
int i;
for (i = 0; i < 1024; i++) {
struct sk_buff *skb = alloc_skb_from_slab();
skb_get(skb);
rb.slot[i].skb = skb;
...
}
}显然这种方式在执行效率上是最好的,即便是skb已经将数据包运输到了用户态的buffer,释放skb时,也只是递减了引用计数而已,数据包不会回到slab/slub。然而这种方式会浪费skb,由于单核心的协议栈每次只能处理一个skb,就意味着同一时刻1023个skb处理闲置状态又不能被slab/slub重复利用。
Linux作为一个通用操作系统,在追求时间上高效率的同时也无法容忍空间的浪费,注意,Linux原生并不是在任何细节上被深度优化的系统,所有这些必须由你自己来做,获取收益的同时,你要明白自己所付出的代价并权衡这个代价。
果不其然,e1000e,igb就没有用这种方式,而是采用了一种批量消费,批量补充的方式,这无疑是我上述两种方案的综合体。e1000e和igb的驱动在结构体上和我上面列示的代码类似,只是在init例程中并没有额外的skb_get操作,这意味着当一个skb完成使命的时候,就会再次进入slab/slub系统。在一轮遍历轮询ring buffer的过程中,大致的逻辑如下:
void handle_rx()
{
int tot = 0;
int base = rb.next_read;
// 一次轮询批量消费多个skb运输所有的数据包。
while (rb.next != rb.next_free) {
struct sk_buff *skb = rb.slot[rb.next_read].skb;
rb.slot[rb.next_read].skb = NULL;
skb->data = rb.slot[rb.next_read].dma_address;
process(skb);
rb.next_read ++;
tot ++;
}
// 为多个已经消费掉skb的slot批量补充skb。
while (tot--) {
struct sk_buff *skb = alloc_skb_from_slab();
rb.slot[base].skb = skb;
base++;
}
}若希望深度优化,请采用附着skb的方式,这个方案我在2015年的时候已经代码实现了,详情参见:
Linux转发性能评估与优化(转发瓶颈分析与解决方案):https://blog.csdn.net/dog250/article/details/46666029
修改起来非常简单,增加skb引用计数,总共不超过100行代码,大部分是处理copybreak这种小包细节的,何足道。在此,必须感谢华为的一个哥们儿告诉我从slab/slub里拿一个skb要4us这么具体的时间,我也就能说,这个优化节省了4us的时间,代价就是浪费了可用skb的数量,然而何足道?
说了这么多的物理网卡,最后我们看一下TUN/TAP虚拟网卡在实现mmap后的观感:
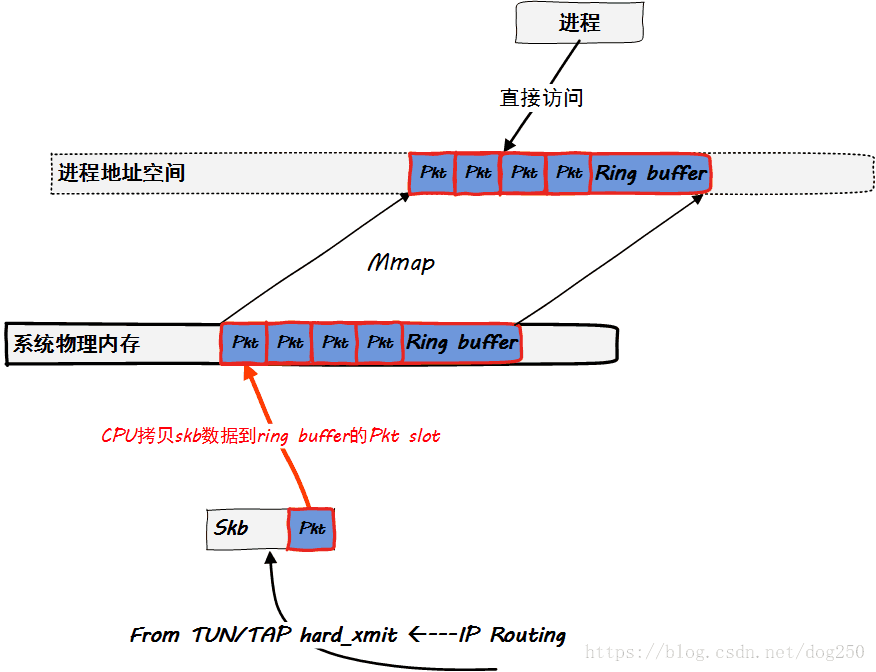
看到了吗?下面DMA那一坨没有了,换成了“CPU拷贝”,如果不使用mmap,那么这个拷贝将会在socket层面进行。值得注意的是,虽然TUN/TAP没有什么DMA功能,但它在网卡层面本来就不需要数据包的拷贝,而物理网卡如果不启用DMA,网卡层面即会有一次从芯片mem到系统内存的拷贝操作,这是完全不同的。
所以说,TUN/TAP的mmap带来的收益并不是避免了拷贝,而是在顺序处理数据包的操作之外添加了一种批量处理数据包的功能。
PACKET套接字的mmap
写到这里,有人可能会问,packet套接字在tpacket_rcv中不也是调用了skb_copy_bits拷贝数据了吗?这样做是不是跟TUN/TAP一样收效甚微呢?并不完全是!
在以往,人们曾经发现了不使用mmap机制的libpcap是多么的效率低下,每抓取一个数据包都要一次系统调用,正如其文档packet_mmap.txt中背景介绍中所述那般:
In Linux 2.4/2.6/3.x if PACKET_MMAP is not enabled, the capture process is very inefficient. It uses very limited buffers and requires one system call to capture each packet, it requires two if you want to get packet’s timestamp (like libpcap always does).
In the other hand PACKET_MMAP is very efficient. PACKET_MMAP provides a size configurable circular buffer mapped in user space that can be used to either send or receive packets. This way reading packets just needs to wait for them, most of the time there is no need to issue a single system call. Concerning transmission, multiple packets can be sent through one system call to get the highest bandwidth. By using a shared buffer between the kernel and the user also has the benefit of minimizing packet copies.
libpcap于是和packet套接字一起,支持了mmap。但是到了PF_RING,netmap之类的真正猛家伙出来之后,事情就起了变化。现如今,内核packet套接字的mmap更多的意义表现在兼容而不是优化。
packet套接字的软件实现中实现mmap更多的是为了支持tcpdump这类抓包程序所依赖的libpcap的mmap调用而不是性能优化!因为libpcap的底层并非只能是packet套接字,在高性能需求的环境,更可能是PF_RING,netmap之类的机制,所以packet套接字必须兼容mmap。不过确实,即便是skb_copy_bits的mmap,也对包处理吞吐带来了极大的性能提升。一次可以批量处理多个数据包总比一个一个数据包处理来得高效,批量处理还有一个好处,即最大限度保持了内存局部性优势,完美利用CPU cache!
TUN/TAP拷贝次数优化
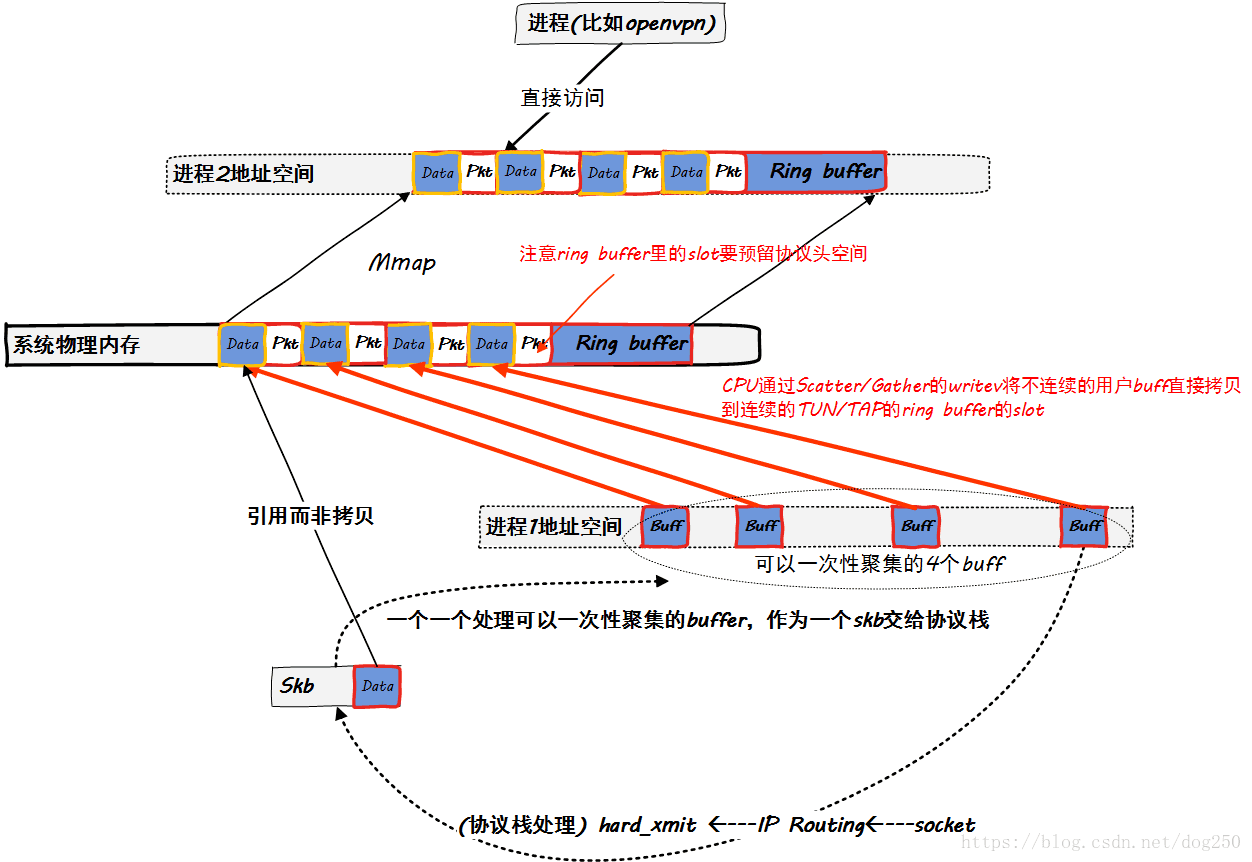
利用分散/聚集(Scatter/Gather)机制,将最终去往TUN/TAP网卡的数据预留协议头后直接拷贝到它的ring buffer,而不是先拷贝到一个skb缓冲区,IP路由后再拷贝到TUN/TAP的ring buffer。
有点理想了,如果没有经过IP路由,如何知道skb最终的目标网卡是TUN/TAP,而在数据包进入IP路有前,就必须要有一个skb运载它,这时它就已经存在了!因此这件事也只有应用层来做了,而这是可行的。
曾经我们想搞一个沙盒,把需要经由OpenVPN的应用全部放在这个沙盒里,那么应用程序自己在路由之前就知道自己最终将经由TUN/TAP送往OpenVPN加密,这就意味着前面说的优化方案是可行的。最终,我们得到一幅还算好看的图景:
后记
周末有出行计划,只能把事情提前到深更半夜,顺便也是为了摆脱飞机,蚊子这些能发出声音且会飞的东西。
昨晚下班后走在路上,梳理了自己这三年的枝枝蔓蔓,不由性起就想写点什么,无奈街边买不到真露,索性点燃一支烟将就,问内心,感觉不那么苍凉,于是就在手机上打字了:
孤眺远帆独启航,星火黯淡夜未央;
借问迁客欲何往,踏破狂浪虐四方。
回想三年前现在这个季节的状态,我也不知道了发生了什么改变:
孤睹天际寒月光,垂颜依稀满地霜;
回望来路无人醒,独践归途人彷徨。
总之,事情总是一直在悄悄地起变化














 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









