







今天刚开始调JSP网站还好好的,后来中间注销了电脑一次,
再打开调试它,就遇到了这个
无法启动服务器的问题:
Destroying ProtocolHandler ["ajp-apr-8009"]
上网百度了下,说是端口号被占用了。
解决办法:
1、查看端口号被占用情况:
步骤:调出命令窗:开始->运行->cmd,然后输入命令:netstat -ano | findstr "8009"
如图(记下来占用该端口号的进程号:5436):
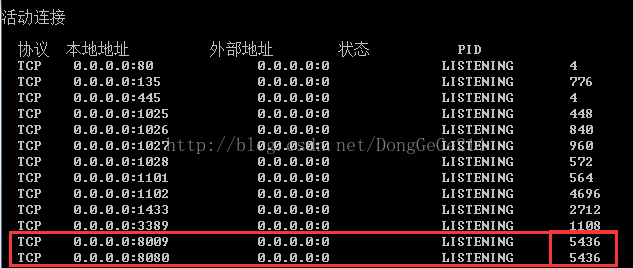
再输入命令 tasklist | findstr "5436" 就可以看到该PID的应用名称
2、解除占用该端口号的进程
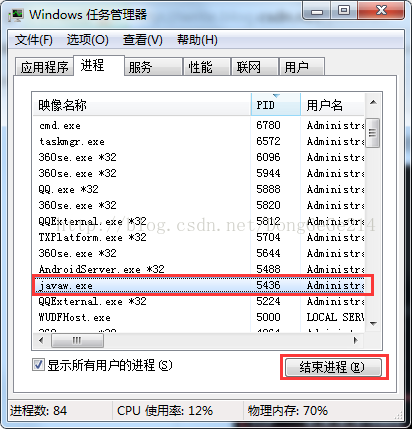
步骤:调出任务管理器(快捷键:Ctrl + Shift + Esc),菜单栏中点->查看->选择列->勾选上PID,然后点任务管理器的“进程”选项卡,找到PID为5436的进程,如图:
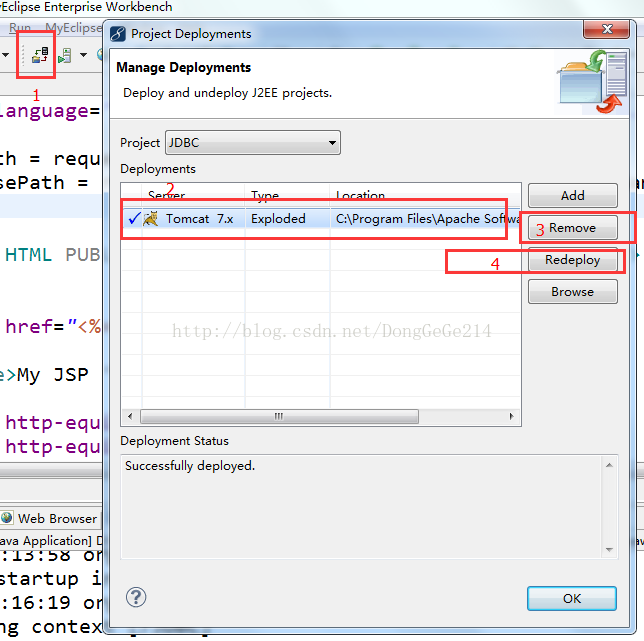
3、在myeclipse中按步骤重新配置一下服务器,如图:
4、启动服务器,现在就可以在浏览器中重新打开该网页了














 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









