







一、schema.xml
schema.xml 文件包含了域的信息以及这些域在搜索期间是怎样分词和过滤的。不同的域类型包含了不同数据类型。Solr 使用 schema.xml 文件决定了如何创建索引和如何执行实时索引和查询。
二、schema.xml 的文档结构(也是 schema 的组成)
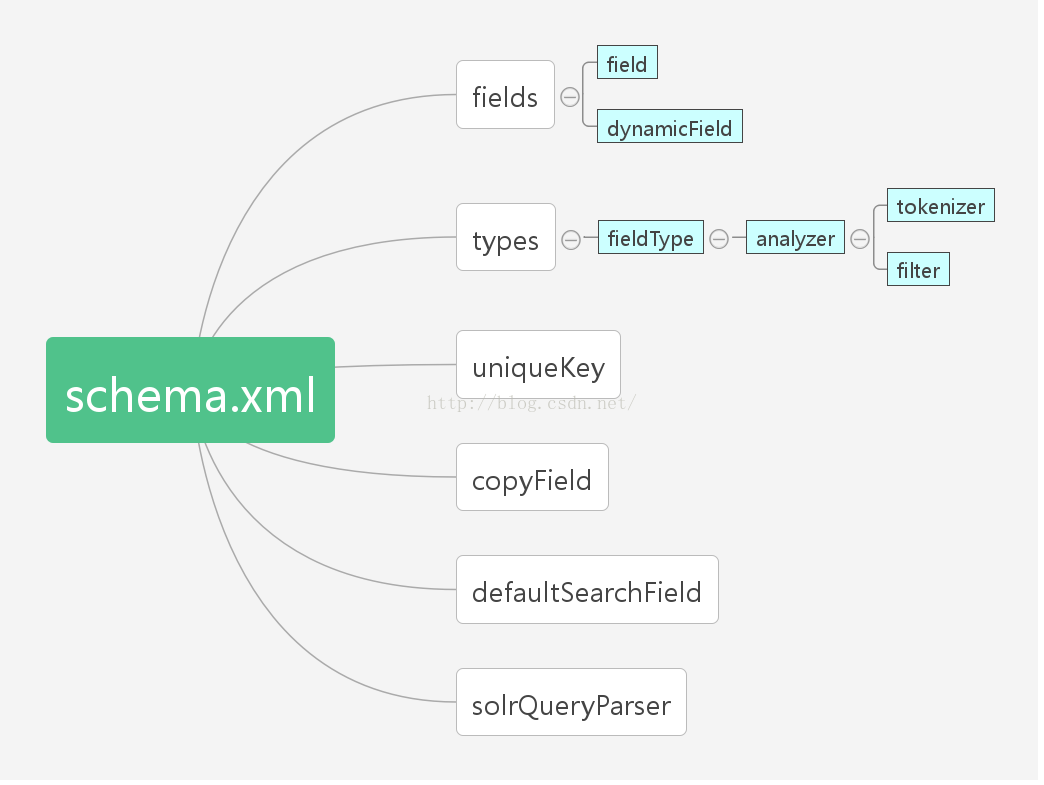
三、<types> 介绍:
<types> 部分允许我们定义一个 <fieldType> 列表,这些 <fieldType> 标签包含着作用于该类型的底层 Solr 类和其他的默认的选项。FieldType 的子类可以作为一个域类型的作用类,可以使用包全名和 Solr 别名(如果在默认的 Solr 包中)来进行引用。对于常见的数值类型(Integer,float等等),这里有多种实现方式,具体操作可以查看 SolrPlugins
1、<fieldType> 内部属性:
1)name:标识
2)class:和其他属性决定了这个 FieldType 的实际行为(都在 org.apache.solr.analysis 包下)
3)sortMissingLast=true|false:没有该指定字段的数据的 Document 排在有该指定字段数据的 Document 的后面
4)sortMissingFirst=true|false:没有该指定字段的数据的 Document 排在有该指定字段数据的 Document 的前面
5)indexed=true|false:该类型的域被索引
6)stored=true|false:该类型的域被存储
7)multiValued=true|false:该类型的字段是多个值的。

8)omitNorms=true|false:字段的长度不影响得分和在索引时不做 boost 处理时,设置它为 true。一般文本域不设置为 true。(当用 solr 或 Lucene 搜索时,如果想对不同类型的文档,或者对不同的域设置不同的权重,又或者对不同的搜索词语设置不同的权重时,就需要 boost 功能)
9)positionIncrementGap=true|false:定义在同一个文档中此类型数据的空白间隔,以避免短语匹配错误
10)autoGeneratePhraseQueries=true|false:true为精确查找,即 AND 关系;false为SHOULD关系,即为 OR 关系。
11)termVectors=true|false:如果字段被用来做近似搜索和高亮显示时,应设置为 true
12)compressed:字段是压缩的。这可能导致索引和搜索变慢,单减少了存储空间,只有 StrField 和 TextField 是可以压缩的,通常适合字段的长度超过 200 个字符。
13)precisionStep:用来数字类型域的范围查找。代表字段值分段保存的时候,截断精度的大小,其值越小,索引越大,查询速度越快。(Trie 树)
2、<analyzer>(分析器) 子标签:
一个分析器可以检查域的文本信息,并产生一个 token 流。通常使用中,只有 solr.TextField 类型的字段会专门制定一个分析器。最简单配置一个分析器的方式是使用<analyzer>元素,定制这个元素的 class 属性为一个完整的 Java 类名。这些类必须源自 org.apache.lucene.anlysis.Analyzer。
1)class:规定分析器类实际行为的类
2)type:分析器使用的阶段。type=index 代表建索引阶段;type=query 代表查询阶段,没有指定则都适用
3、<tokenizer>(分词器)子子标签:
将句子拆分成一个个词或词组。
1)class:分词器工厂类(注意这里是 Factory 而不是真正的分词器,它是通过工厂类来创建分词器实例的。所有工厂必须实现 org.apache.solr.analysis.TokenizerFactory,工厂产物也必须派生之 org.apache.lucene.analysis.TokenStream
4、<filter>(过滤器)子子标签:
在分词之后,接受 Token Stream 进一步处理,例如:全部转换为小写、事态处理,去掉语气词等等,最后输出 token Stream。
5、分析器、分词器和过滤器的使用规则:
1)分析器单独使用
<fieldType name="text_greek" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.el.GreekAnalyzer"/>
</fieldType> <fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType> <fieldType name="text_en_splitting_tight" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- this filter can remove any duplicate tokens that appear at the same position - sometimes
possible with WordDelimiterFilter in conjuncton with stemming.
这个过滤能够去除在相同位置的任何重复的分词。
-->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType> <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
在这个例子中,我们仅仅在查询时用来同义词查询
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>














 1647
1647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









