






深度神经网络(DNN),尤其是卷积神经网络(CNN),使得由多个处理层组成的运算模型可以学习到数据的多层抽象表示。这些方法极大地提高了视觉物体识别、物体探测、文本识别以及其他诸如药物发现和生物学等领域的最先进的水准。
除此之外,很多关于这些主题的具有实质性内容的文章也相继发表,同时很多高质量的CNN开源软件包也被广泛传播。当然也出现了很多有关CNN的教程和CNN软件使用手册。但是,唯一缺少的可能是一个完整介绍如何实现深度卷积神经网络所需要的所有细节的综合性文章。因此,本文就搜集和整理了DNN实现的所有细节,并对所有细节进行讲解。
(一)介绍
本文将从八个方面来讲述DNN的细节实现。包括(1)数据集扩展;(2)图像的预处理;(3)网络的初始化;(4)训练过程中的一些技巧;(5)激活函数的选择;(6)正则化的多种手段;(7)对图像的深入认识;(8)多种深度网络的整合。
(1)数据集的扩展
由于深度网络在训练时需要大量的数据才能达到令人满意的性能,所以当原始数据较少时,最好是通过一些手段来扩展数据集,而且数据扩展也渐渐成为训练深度网络的必要过程。
数据扩展的方法包括常用的水平翻转、随机剪切和颜色抖动,甚至还可以将上述方法组合起来,比如对图像同时进行旋转和随机缩放。此外,也可以对像素的饱和度和纯度进行0.25-4倍范围内的幂次缩放,或者进行0.7-1.4范围内的乘法缩放,或者加上-1~1之间的数值。同样也可以对色度进行类似的加法处理。
Krizhevsky等人在优化训练Alex网络时提出了Fancy PCA[1]-它通过改变RGB信道的强度来扩展数据集。他们发现Fancy PCA近乎能捕获到自然图像的重要特性,即识别物体时对光照的强度和颜色的变化具有不变性。在分类性能上,这一方案将在ImageNet2012的top-1的错误率降低了超过1%。
(2)预处理
得到大量数据集后,是有必要对其进行预处理的,本部分介绍几种预处理方法。
最简单的就是中心化,然后归一化。还有一种类似的就是对数据集的每一维都进行归一化。当然,这种归一化只在不同特征的尺度不同时才有效,而在图像中,由于像素尺度范围一致,所以这种预处理过程对图像而言就没有必要了。
还有一种预处理方法是PCA白化,首先也是中心化,然后通过计算协方差矩阵来发现数据中的关联结构,接着通过将原始数据映射到特征向量来解耦数据,最后就是白化过程,即对特征向量进行归一化。白化过程的缺陷在于它会引入噪声,因为它使得输入的所有维度尺度相同,但实际上有些维度基本上是噪声。这可以通过引入更强的平滑性先验来缓解。
需要注意的是这些预处理在CNN中并非必要。
(3)网络初始化
在理想情况下,经过数据扩展后,假定网络权重一半是正数一半是负数是合理的,所以将所有的权重初始化为0看起来并没有什么问题。但事实证明这是错误的,因为若网络中的每个神经元的输出都一样,那么利用BP计算的梯度也会都一样,使得所有的参数更新都一样,这样就使得神经元之间不存在非对称性。
因此这种完全的零初始化并不可取。但为了使得初始化权重尽可能小些,你可以将它们随机初始化为近0值,这样就可以打破上述的对称性。这种初始化的思想是,神经元在开始时的状态都是随机和独立的,所以它们可以进行不同的更新,从而组合成以个丰富的网络。比如利用0.001*N(0,1)这样分布或者均匀分布来初始化参数。
上述初始化存在的问题是,随机初始化的神经元的输出分布中存在一个随着输入个数变化而变化的变量。实践证明可以通过缩放权重矢量来归一化每个神经元输出的变量。

其中的randn是高斯分布,n是输入个数,这就保证了网络中的所有神经元在初始阶段都有着差不多相同的输出分布,同时也能提高收敛速度。需要注意的是当神经单元是ReLU时,权重的初始化略有不同[2]:

(4)训练过程的一些技巧
a)滤波器和池化大小。在训练时输入图像的大小倾向于选择2的幂次值,比如32,64,224,384,512等。同时,利用较小的滤波器,较小的步幅和0填充值既可以减少参数个数,也可以提升整个网络的精确度。
b)学习率。一如Ilya Sutskever在一篇博客[3]中所说的,利用小批量尺度来分解梯度,这样当你改变批量大小时,就不必总要改变学习率了。利用验证集是一种高效选择学习率的方法。通常将学习率的初始值设为0.1,若在验证集上性能不再提高,可以将学习率除以2或者5,然后如此循环直到收敛。
c)预训练模型的微调。现今,很多最好性能的模型都是由一些著名的研究团队提出来的,比如caffe model zoo 和vgg group。由于这些预训练模型都有着很好的泛化能力,所以可以直接将这些模型运用到自己的数据集上。想要进一步提高这些模型在自己的数据集上的性能,最简单的方法就是在自己的数据集上对这些模型进行微调。一如下表所示,最需要关注的两个参数就是新数据集的大小以及它和原始数据集之间的相似度。不同情形下可利用不同的微调方法。比如,比较简单的情形就是你的数据集和预训练模型的数据集十分相似,若你拥有的数据集很小,你只需利用预训练模型的顶层特征就能训练出一个线性分类器,若你拥有的数据集很大时,最好利用较小的学习率对预训练模型的几个较高层都进行微调。要是你的数据集较大而且和原始数据集之间存在很大的差别,那么需要利用较小的学习率来微调更多的层。要是你的数据集不仅和原始数据集差别大,而且很小,此时训练就变得很困难。因为数据少,最好是只训练一个线性分类器,又因为数据集差别大,利用最顶层的特征来训练这个分类器又不合适,因为最顶层的特征包含了很多关于原始数据集特性的特征。更合适的方法是在网络的某个更靠前些的层的特征上训练SVM分类器。

(5)激活函数的选择
DL网络中一个重要的环节就是激活函数的选取,正是它使得网络具有了非线性。本部分将介绍几个常用的激活函数并给出一些选择建议。
a) sigmoid:它的数据表达式是
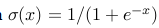
1)sigmoid容易饱和,导致梯度消失。
当神经元的激活值为0或者1时,处于这一区域的梯度为0,而在BP算法中,这种局部梯度会使得梯度消失,从而导致该神经元无信号经过。此外,在初始化sigmoid神经元的权重时,也需要注意防止饱和,若初始化权重很大,很多的神经元会很快就达到饱和,从而导致这些神经元不能再学习。
2)sigmoid的输出并不是中心化的。这会影响梯度下降的波动状态,因为若进入一个神经元的输入总是正数,那么关于该神经元的权重梯度计算时要么都是正的或者都是负的,这会导致利用梯度更新权值时发生所不想要的之字形波动。不过若将一批数据的梯度加起来再进行权值更新时,权值就能取到正负值,某种程度上缓解了这一问题。
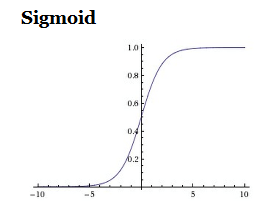
b)tanh(x):tanh函数的输出范围是(-1,1)。和sigmoid函数类似,它也存在饱和问题,但和sigmoid不同的是它的输出是中心化的。所以实际中更倾向使用tanh函数。
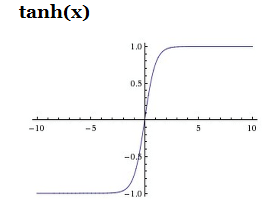
c)ReLU:改进的线性神经单元在过去几年深受欢迎,它的激活函数是f(x)=max(0,x),即阈值设为0,如下图所示:
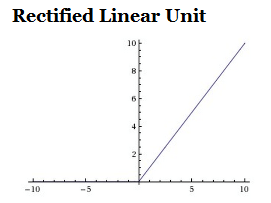
ReLU有如下优缺点:
1.不同于sigmoid和tanh函数操作的复杂性,ReLU只需要对激活值矩阵设置0阈值即可,同时ReLU还不存在饱和问题;
2.ReLU极大地提高了随机梯度的收敛速度;
3.其缺陷是比较脆弱且在训练过程中容易发生神经元的死亡的现象。比如,当一个较大的梯度经过ReLU时会使得相应的权值更新幅度很大,导致神经元在其他任何数据点上不再被激活。这样就导致流经此神经元的梯度随后总是为0,即此单元在训练过程中不再起作用。
d)Leaky ReLU:它是试图解决ReLU单元死亡问题的一种方法。
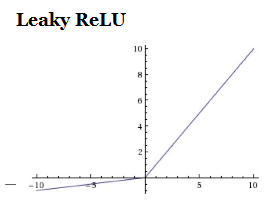
此时x<0时函数值不再为0,而是取一个很小的负值,即当x<0时f(x)=ax,当x>0时f(x)=x,a是一个很小的常数。一些研究在此激活函数上取得了很大的成功,但每次试验结果很难保持一致。
e)PReLU/RReLU:它和Leaky ReLU的区别在于常数a不再是确定的,而是学习到的。而RReLU中的a是从一个给定范围内随机抽取得到的,在测试阶段才固定下来。
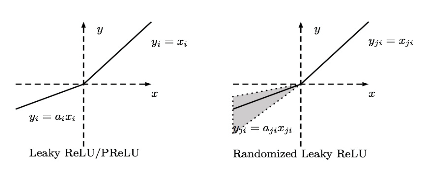
He等人宣称PReLU是DL在Imagenet的分类任务上超越人类水平的关键所在。而在kaggle的一个比赛中,提出RReLU因为其随机性而可以缓解过拟合问题。
在[]中作者对这几种激活函数在不同数据集上的性能进行了比较,结果如下:

需要注意的是表中a的实际取值是1/a。同时我们也可以看到,ReLU在这三个数据集上并不总是最好的,而当Leaky ReLU的a取值较大时能达到更高的精确率。PReLU在小数据集上容易发生过拟合,但性能仍然比ReLU要好。RReLU[4]在NDSB数据集上是性能最好的,这也说明了RReLU确实能够缓解过拟合,因为NDSB数据集比其他两个数据集都小。
总之,ReLU的三种变形都比其本身性能要好。
(6)正则化
可以通过以下几种方法来控制神经网络的容量,从而避免过拟合:
1)L2范式:通过直接在目标函数中加上所有参数值的平方来补偿过拟合,即对每个参数w,都在目标函数中加上对应项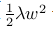
2)L1范式:对于每个权重w,在目标函数中增加对应项λ|w|。也可以将L1和L2范式整合起来使用,即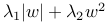
3)最大约束范式:它是对每个神经元的权重矢量最大值的绝对值给予限制并且利用设计好的梯度下降来加强这一限制。实际操作中先是对参数进行正常的更新,然后再通过钳制每个神经元的权重矢量使它满足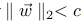
4)dropout[5]:它是一个十分高效、简单的正则化方法。在训练过程中,dropout可看做是在整个网络中抽取一个子网络,并基于输入数据训练这个子网络,但是这些子网络并不是独立的,因为他们的参数共享。
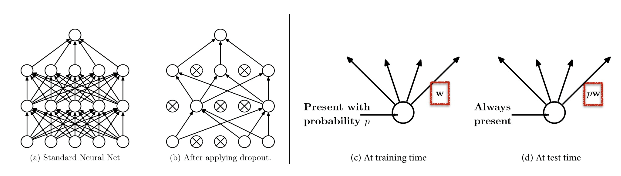
在测试阶段不再运用dropout,而是基于对所有指数级数目的子网络的预测求平均来进行评估。实际操作中dropout比率经常取为p=0.5,不过在验证集上这一数值是可以调整的。
(7)对图像的深入认识
利用上述方法基本可以得到令人满意的网络设置,而且在训练阶段,你也可以抽取一些图像处理结果来实时观察网络训练的效果。
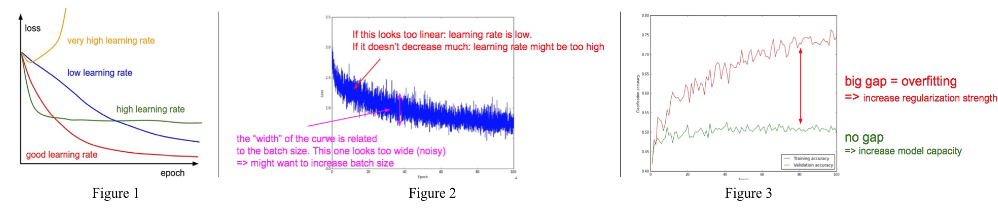
1)我们知道,学习率的调整是十分敏感的,从下图可以看到,学习率很高时会产生一个十分奇怪的损失曲线。一个很低的学习率即使经过多轮训练你的训练误差依然降低得十分缓慢,而很高的学习率在开始训练时误差会降低得很快,但却会停留在局部最小点,这样就会导致你的结果无法令人满意。一个好的学习率,其对应的误差曲线应用具有很好的平滑性并最终使得网络达到最优性能。
2)我们放大误差曲线看看会发现什么。轮即是在训练数据上完成一次训练,所以在每轮中有很多小批次数据,画出每个小批次数据的分类误差,如图二。和图一类似,若误差曲线很接近线性,这意味着学习率很低,若其降低幅度很小,意味着学习率可能太大了。曲线的宽度和批次大小有关,若宽度很宽,意味着批次大小相差很大,这时应该尽量减少批次间的差别。
3)另外我们还可以观察精确率曲线,如图三。红线是训练精确率,绿线是验证集精确率。当验证集的精确率开始收敛时,红绿曲线之间的差别可以表现网络训练是否高效。若差别较大,即在训练集上的精确率很高而在验证集上的精确率很低,这意味着你的模型在训练集上出现了过拟合,这时就应该增强对网络的正则化。然而,若两者间差别很小但精确率很低,这意味着你的模型的学习能力很弱,这时就需要增大网络的容量来提高其学习能力。
(8)网络整合[6]
ML中,训练多个学习器再将他们组合起来是达到最好性能的一种方法。本部分介绍几种整合方法:
1)相同模型,不同初始化方法。利用交叉验证来确定最优超参,然后利用这些超参来训练初始化不同的多个模型。这种方法的缺陷在于只有初始化这一个变化。
2)在交叉验证接过程中选取几个性能排在最前边的模型进行组合。先利用交叉验证确定最优超参,然后选取几个性能较好的模型进行整合。这种方法提高了多样性,但可能会将次优模型也包含在内了。实际应用中,这种方法很容易实现,因为它不需要在交叉验证后对模型进行额外的再训练。你也可以在caffe model zoo里选取几个模型进行组合训练。
3)在单个模型里设置不同的检测点。若训练成本太高,在资源受限的情况下,不得不在单个模型训练过程中选取检测点,并且利用这些结果进行组合。很显然,这种方法也缺乏多样性,但在实际应用中也能取得一定的成功。但它的成本很低。
4)一些现实例子。若你的视觉处理任务和图像的高层语义相关,比如利用静态图像来进行事件识别,更好的一种途径是在不同的数据源上训练多个模型来提取不同且互补的深度特征。比如在ICCV2015的文化活动识别挑战中,我们利用五种不同的深度网络在Imagenet,pace database和竞赛组织者提供的数据集上进行训练,这样就获取了五种互补的深层特征并将它们看作是多视角数据。将前期的融合和后期的融合结合起来[],我们取得了该比赛的第二名。在[7]提出了堆积NN组合成更深网络的思路。
在现实应用中,数据集经常会出现各类别间不均衡的现象,即一些类别有很多训练样例,而另一些类别的样例很少,一如[]中所谈及的,在这种不均衡数据集上训练深层网络会使得网络性能很差。处理这一问题的最简单的方法就是对数据集进行上采样和下采样[8]。另外一种方法是[7]中提出的特殊剪切处理,因为原始的有关文化活动的图像及不均衡,我们就只对那些含有较少样例的类别图像进行剪切,这样既可以为数据提供多样性,也能缓解数据不均衡问题。除此之外,也可以通过调整微调策略来克服数据源的不均衡,比如,可以将数据源分成两份,一份是那些含有很多样例的类别,另一份是那些只有少量样例的类别。在这两份数据集里,不均衡问题也得到了缓解。在自己的数据集上微调网络时,先在第一份数据集上微调,然后再在第二份数据集上微调。
参考文献:
[1]A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. In NIPS, 2012
[2] K. He, X. Zhang, S. Ren, and J. Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In ICCV, 2015
[3] A Brief Overview of Deep Learning, which is a guest post by Ilya Sutskever.
[4] B. Xu, N. Wang, T. Chen, and M. Li. Empirical Evaluation of Rectified Activations in Convolution Network. In ICML Deep Learning Workshop, 2015.
[5] N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. JMLR, 15(Jun):1929−1958, 2014.
[6] Z.-H. Zhou. Ensemble Methods: Foundations and Algorithms. Boca Raton, FL: Chapman & HallCRC/, 2012. (ISBN 978-1-439-830031)
[7] M. Mohammadi, and S. Das. S-NN: Stacked Neural Networks. Project in Stanford CS231n Winter Quarter, 2015.
[8] P. Hensman, and D. Masko. The Impact of Imbalanced Training Data for Convolutional Neural Networks. Degree Project in Computer Science, DD143X, 2015.














 1437
1437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









