







本文有以下几个亮点:一是利用DNN直接学习到从原始图片到欧氏距离空间的映射,从而使得在欧式空间里的距离的度量直接关联着人脸相似度;二是引入triplet损失函数,使得模型的学习能力更高效。
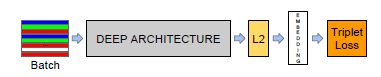
本文的模型示意图如上,输入层后紧接着DNN,然后再运用L2正则化避免模型的过拟合,最后接上triplet损失函数层,以反映在人脸验证、识别和聚类中所想要的结果。这里的关键就是triplet损失函数的确定,我们想要的结果就是,找到嵌入函数f(x),使得所有人脸之间的距离较小,但不同配对人脸间的距离较大。
首先我们来看看本文中用到的网络模型:ZF-Net和GoogleNet。
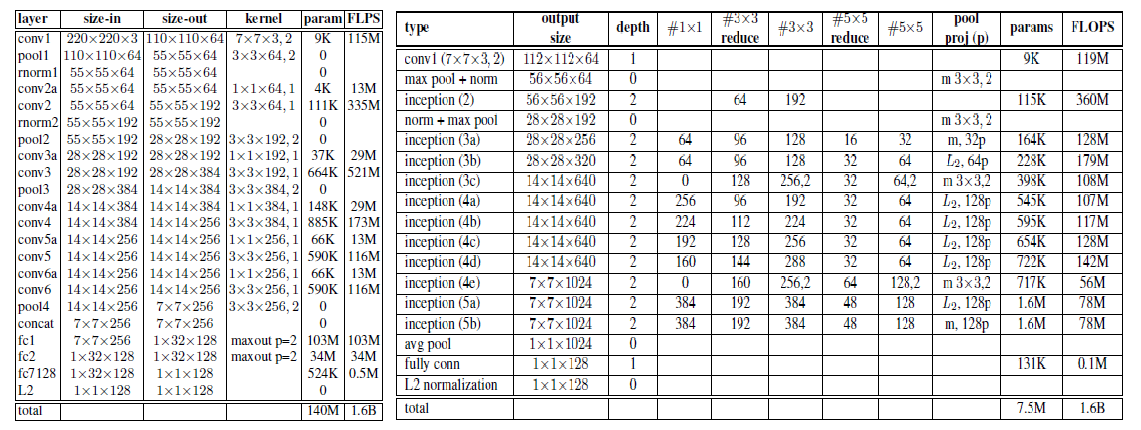
在ZF-Net可以看到,在前几个卷积层中加入了1*1*d的卷积层, 有效的减小了参数的个数。但和GoogleNet相比,参数量还是很大。为了使得模型可以嵌入到移动设备中,本文中也对模型进行了裁剪,NNS1即只需要26M的参数和220M的浮点运算开销,NNS2则只有4.3M的参数和20M的浮点运算量,NN3和NN2的模型一样,但输入图片大小只有160*160,而NN4则是96*96,这样极大幅度的降低了对CPU的需求。
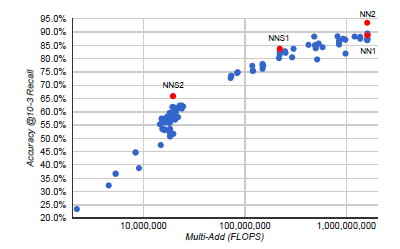
上图给出了在精确率和运算量上这四个模型之间的比较。可以看到,模型越复杂精确率越高,其所需的运算开销也会随之增大。
同时需要注意的是,NN2和NN1达到的精确率相当,但NN2所用的参数却大大减少,不过运算量却又没降下来。这是一个值得思考的地方。
接下来看看triplet损失函数的确定。嵌入函数f(x)将输入图片x嵌入到一个d维的欧式空间,同时对嵌入引入限制,即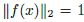
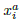
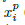
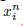
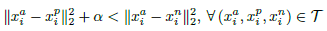
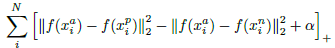
需要注意的是,若生成所有可能的triplet,会导致很多的triplet满足条件,而这些triplet对训练没有任何益处且会导致收敛变慢,所以选择合适的triplet很关键。
为了加速收敛过程,选择那些不满足条件的triplet至为关键,即给定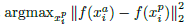
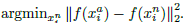
1)在数据子集上利用网络最近的检测点计算argmin和argmax,并且每n步线下生成triplets。
2)通过从小批量样本中选择hard positive/negtive样例来生成triplets。
同时本文也对该网络对图片质量、嵌入维度的大小以及训练集大小的敏感性做了分析。
实践发现该模型对图片质量的高低有着较好的鲁棒性,即使JPEG的质量降低20倍,性能仍然能保持。如下图所示:
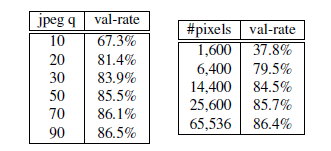
对于嵌入维度而言,维度越大性能应该越好,但其需要的数据集也会变大,所以此处的衡量不能一概而论。
而增大训练集却是可以提高模型的性能,但因为网络的学习能力有限,一旦数据集达到某一极限时性能也开始达到瓶颈。
本文的triplets实现是个值得深入思考的地方。














 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









