







Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
scrapy startproject project
该命令将会创建包含下列内容的project 目录:
project/
scrapy.cfg
project/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件分别是:
scrapy.cfg: 项目的配置文件project/: 该项目的python模块。之后您将在此加入代码。project/items.py: 项目中的item文件.project/pipelines.py: 项目中的pipelines文件.project/settings.py: 项目的设置文件.project/spiders/: 放置spider代码的目录.
最近对Scrapy进行了完整的学习。下图是整个程序的结构图,主要分为三大块:下载模块、解析模块、处理模块。
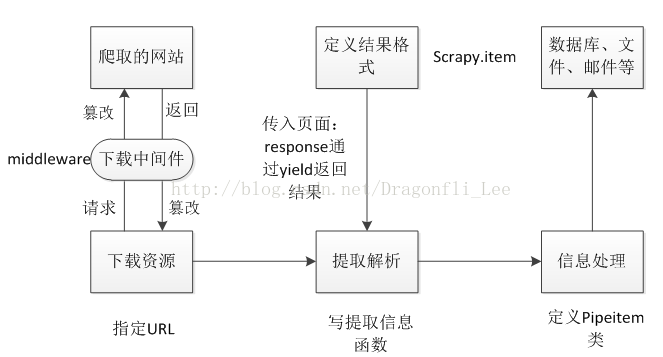
在下载模块中指定爬虫的初始爬取网页URL,如果需要登陆还需要模拟用户提交cookie信息。在下载模块与爬取网站之间加入了中间件,用来处理请求或者相应,例如将请求信息伪装成特定类型浏览器用于躲避网站防爬虫机制。
下面是中间件模板,process_request是对请求进行篡改,我在这里加入浏览器伪装中间件。
Class 下载中间件的名字(object):
def process_request(self, response, spider):
#篡改请求
def process_response(self, request, response, spider):
#篡改响应
def process_excepition(self, request, exception, spider):
#处理异常编写完中间件还不能起作用,还需要在主目录的settings文件中加入配置,配置项为DOWNLOADER_MIDDLEWARES,配置下载中间件,后面的数字从下到大依次调用,如果None则不调用。
DOWNLOADER_MIDDLEWARES = {
‘scrapy.contrib......UserAgentMiddleware’:None,
‘XX.middlewares.RandomUAMiddlesware’:4000,
‘XX.middlewares.PrintUAMiddleware’:4005
}在解析模块中,Scrapy将爬取的页面进行解析,通过xpath等工具提取特定的内容,并通过生成器yield返回。这里说明一下Python生成器,它是一个特殊的函数,每次返回结果阻塞在yield语句前,给一个.next()返回一个结果,是一个挤牙膏式的函数,用于防止一次性输出太多。
一个正常的函数:---> 返回值
def function(n):
for num in range(n):
print n**2|
|在执行过程中,把想要的数据yield出来
|类似生成器中的return
|
生成器函数:---> 返回生成器
def function(n):
for num in range(n):
yield n**2 #通过.next()获取下一个值
print n**2信息处理模块是对解析好的数据进行处理,如存入数据库、终端打印、数值分析等等,此项功能通过编写pipeline实现,每一个函数都是一个处理方法,按顺序处理数据达到指定要求。下面是Pipeline模板:
class XXXXPipeline(object):
def __init__(self):
# 初始化方法
def open_spider(self, spider):
# 打开爬虫的操作,如打开数据库
def process_item(self,item, spider):···
# 处理抓取出来的结构化数据,如写入数据库
def close_spider(self,spider):
# 关闭爬虫的操作,如关闭数据库
@classmethord
def from_crawler(cls,crawler):
# 生成Pipeline的实例下面以存入数据库功能为例:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DATABASE')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
collection_name = item.__class__.__name__
self.db[collection_name].insert(dict(item))
return item同理在主目录settings文件中需要加入pipeline配置,配置项是ITEM_PIPELINES。














 1916
1916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









