







提示:皆为初印象,可能我理解的都有错,主要目的是记录我学习大数据的一个心路旅程,不小心看到此文的同仁,请指教!看见有人说,跟别人学的效果,不如自己学的效果,自己学的效果不如教别人学的效果。那我来试试,跟别人学后自己学,学完后再教别人学。后面学习,我会来持续修改错误!
一,大数据、云计算初印象
为什么大数据总是跟云计算扯上关系,到底大数据是什么,云计算又是什么?看了《大数据时代》、《大数据》、《数据之巅》、《驾驭大数据》等几本概论书籍,才对大数据有了一点印象。随着互联网的发展,互联网上的数据爆炸式增长。总结起来有以下几个特点:
数据量很大,达到一定的量级。其实这个量级到底多大也没有一个固定的说法的。
数据增长速度很快。
数据多样化,比如文字、图片、视频等各种类型。
因为这几个原因,很多大点的公司就会产生大量的离线数据。而这些大量的离线数据中可以挖掘出很多有价值的信息,比如比较出名的沃尔玛啤酒鱼尿布的案例。要处理这大量的离线数据,就需要有好的处理器、大的存储器等资源支撑。受限于摩尔定律,一台服务器的能力是有限制的。而谷歌服务器呢,每秒需要处理大量的请求,为了降低负载,就必须要有并行的服务器去分摊处理这些请求。等等。总之就是要有很多的数据要同时去处理,一台服务器满足不了。行,那就找多台服务器一起去处理。这就出现了分布式与并行计算的问题。而云计算正是基于这种分布式与并行计算,把大量廉价的服务器等资源整合在一起,来并行处理大数据量的计算需求。把这些资源放到网上按需购买使用,改变了我们传统的互联网资源的交付与使用模式。
二,mapreduce初印象
而如何去管理这些廉价的计算机和分散在各个计算机上的数据计算呢?而hadoop就是做这个的。hadoop是一种分布式计算框架,里面包含分布式文件系统hdfs,并行计算模型mapreduce,以及资源调度管理器yarn。我的理解就是hdfs是由多个数据节点与数据调度节点组成,数据的保存与读取是靠数据调度节点去管理,而每个数据节点用于实际的存储。基于这种多节点的文件系统则为分布式的文件系统。而hdfs则专门为mapreduce设计。mapreduce是一种编程模型,主要包含map和reduce部分。整体的流程如下:
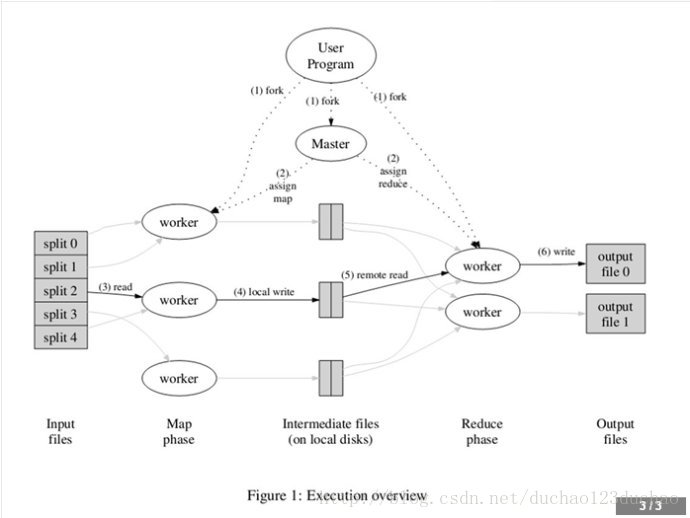
- 把大量的数据存储到hdfs分布式文件系统。
- 实现了map与reduce操作的用户程序读取hdfs的文件block。
- mapreduce把用户程序读取的文件进行split分片。
- mapreduce通过fork命令把用户程序拷贝到hadoop集群中别的节点。有一个节点的用户进程称为master,其余称为worker,master是负责调度,为空闲worker分配作业(Map作业或者Reduce作业)。
- master节点的tasktracker使用心跳机制主动向Jobtracker询问是否有作业,jobtracker从作业队列为master节点分配map作业,然后master把map作业分配给空闲的map worker。
- map worker读取分片,并抽取出至少一个key-value,然后调用map函数并把key-value传给map函数处理。map函数处理value后会产生众多的key-value中间键值对,并缓存在环形内存缓冲区。如果缓冲区内容达到阀值。这个map worker的tasktracker会分配一个线程去把缓冲区数据读取到节点的本地磁盘的R个分区中。并且在复制到R个分区前,这个线程会先对数据进行排序,然后根据哪些key会被哪个reduce任务处理而存进相对应的分区中。并且这些key的位置信息和分区信息会被map worker的tasktracker通过master传递给jobtracker。这样的交互知道所有的worker节点的map任务完成。
- 于此同时,reduce节点的一个线程定期询问jobtracker以便获得map输出的位置。直到它获得所有输出位置信息,每个reduce便开始从上个map作业过程的每个特定输出分区中复制数据。map数据输出少的,reduce直接把map输出数据,也即特定分区的数据直接保存在reduce节点的内存中。如果map数据输出多,reduce会把数据保存在本地磁盘。直至复制完毕。
- reduce从map worker复制完数据,便开始进行合并操作,合并的结果是每个key会对应一个迭代器,也是key-value形式。每个key,会去调用一次reduce函数进行处理。每个reduce会对应一个reduce输出文件,保存在hdfs。
- map,reduce作业都完成后,mapreduce便返回,把执行权交给用户程序。
参考资料:














 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









