







学习概述:
hadoop的hdfs<-
hadoop的mr(YARN)
hbase命令行
hbase开发
自定义MR过程
hbase参与MR
zookeeper安装和使用
flume使用
redis以及lucene
nutch
lvs,keepalived等以及hadoop的运维
openstack( Cloudera)
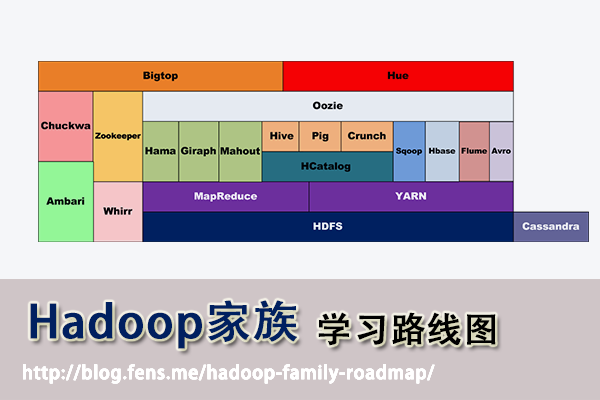
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
前言
使用Hadoop已经有一段时间了,从开始的迷茫,到各种的尝试,到现在组合应用….慢慢地涉及到数据处理的事情,已经离不开hadoop了。Hadoop在大数据领域的成功,更引发了它本身的加速发展。现在Hadoop家族产品,已经达到20个了之多。
有必要对自己的知识做一个整理了,把产品和技术都串起来。不仅能加深印象,更可以对以后的技术方向,技术选型做好基础准备。
本文为“Hadoop家族”开篇,Hadoop家族学习路线图
目录
- Hadoop家族产品
- Hadoop家族学习路线图
1. Hadoop家族产品
截止到2013年,根据cloudera的统计,Hadoop家族产品已经达到20个!
http://blog.cloudera.com/blog/2013/01/apache-hadoop-in-2013-the-state-of-the-platform/
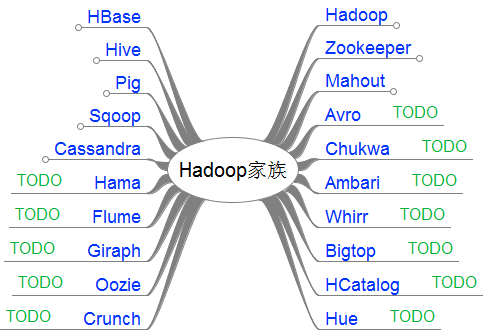
接下来,我把这20个产品,分成了2类。
- 第一类,是我已经掌握的
- 第二类,是TODO准备继续学习的
一句话产品介绍:
- Apache Hadoop: 是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。
- Apache Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- Apache Pig: 是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
- Apache HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
- Apache Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- Apache Zookeeper: 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务
- Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
- Apache Cassandra:是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身
- Apache Avro: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制
- Apache Ambari: 是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
- Apache Chukwa: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。
- Apache Hama: 是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
- Apache Flume: 是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输。
- Apache Giraph: 是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
- Apache Oozie: 是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。
- Apache Crunch: 是基于Google的FlumeJava库编写的Java库,用于创建MapReduce程序。与Hive,Pig类似,Crunch提供了用于实现如连接数据、执行聚合和排序记录等常见任务的模式库
- Apache Whirr: 是一套运行于云服务的类库(包括Hadoop),可提供高度的互补性。Whirr学支持Amazon EC2和Rackspace的服务。
- Apache Bigtop: 是一个对Hadoop及其周边生态进行打包,分发和测试的工具。
- Apache HCatalog: 是基于Hadoop的数据表和存储管理,实现中央的元数据和模式管理,跨越Hadoop和RDBMS,利用Pig和Hive提供关系视图。
- Cloudera Hue: 是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。
2. Hadoop家族学习路线图
下面我将分别介绍各个产品的安装和使用,以我经验总结我的学习路线。
Hadoop
- Yarn学习路线图
Hive
Pig
Zookeeper
HBase
Mahout
Sqoop
Cassandra
软件
CentOS-5.8-i386 Hadoop2.2.0 VMWare 8 Eclipse JUNO JDK 7u45 FileZilla Putty
规划
两台虚拟机组成的集群(下篇介绍集群,机器差带不起来更多了):
192.168.1.103 master
192.168.1.133 node1
安装基础环境:
安装操作系统并使用桥连方式
设置主机名为Master
同步时间
使用setup 命令配置系统环境
ifconfig #检查网络ip 配置
编辑host文件
vi/etc/hosts安装JDK和hadoop-2.2.0
建立Hadoop用户并赋权
无秘钥ssh
su hadoop
cd /home/hadoop/
ssh-keygen-q -t rsa -N "" -f /home/hadoop/.ssh/id_rsa设置hadoop-env.sh和yarn-env.sh的JDK_HOME
修改core-site.xml
<configuration><property>
<name>hadoop.tmp.dir</name>
<value>file:/home/software/temp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration><property>
<name>dfs.name.dir</name>
<value>file:/home/software/name</value>
<description> </description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:/home/software/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:9002</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>1073741824</value>
</property>
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改mapred-site.xml
<configuration><property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
编辑yarn-site.xml
<configuration><property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8990</value>
<description>host is the hostname of the resource manager and
port is the port on which the NodeManagers contact the Resource Manager.
</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8991</value>
<description>host is the hostname of the resourcemanager and port is the port
on which the Applications in the cluster talk to the Resource Manager.
</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
<description>In case you do not want to use the default scheduler</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8993</value>
<description>the host is the hostname of the ResourceManager and the port is the port on
which the clients can talk to the Resource Manager. </description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/software/tmp/node</value>
<description>the local directories used by the nodemanager</description>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>master:8994</value>
<description>the nodemanagers bind to this port</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>5120</value>
<description>the amount of memory on the NodeManager in GB</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/home/software/tmp/app-logs</value>
<description>directory on hdfs where the application logs are moved to </description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/software/tmp/node</value>
<description>the directories used by Nodemanagers as log directories</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run </description>
</property>
</configuration>
修改capacity-scheduler.xml
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
Maximum number of applications that can be pending and running.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>unfunded,default</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.unfunded.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>50</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>-1</value>
<description>
Number of missed scheduling opportunities after which theCapacityScheduler
attempts to schedule rack-local containers.
Typically this should be set to number of racks in the cluster, this
feature is disabled by default, set to -1.
</description>
</property>
</configuration>
修改slaves
cd /home/software/hadoop-2.2.0/sbin
./start-dfs.sh测试Hadoop
创建hdfs目录hdfs dfs -mkdir /tmp
hdfs dfs -copyFromLocal /home/software/test.txt /tmp/
hdfs dfs -ls /tmp
hadoop jar /home/software/hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 10 100
停止Hadoop
若停止hadoop,依次运行如下命令:$./stop-yarn.sh
$./stop-dfs.sh














 2663
2663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









