







下面包含阿里、百度、人人的真实面试题以及解答。
阿里:
1、 以O(1)在栈上实现max、push和pop
可以采用两个栈,一个用于记录普通数据,一个用于记录当前数据之前出现的最大值。这样通过两个栈的合作就能知道每时每刻的最大值。
2、 给你很多组ip地址的范围, 每组代表一个城市。 让你计算 输入一个ip地址,它属于哪个城市。
最笨的方法挨个比较;二是通过map来存储,方便寻找;针对ip地址提出一些关键词汇,比如四个字段都是位于哪个范围内的数据,然后先比较这些标志位,然后就减小了比较范围。
3,列举常见的数据结构,应用场景
线性:数组,链表(单向链表,双向链表),栈,队列
树:
二叉搜索树,根节点的左孩子比自己小,右孩子比自己大,中根次序遍历肯定是递增顺序的。
平衡二叉树:每个节点左右孩子的高度差不超过1。
AVL树:自平衡二叉查找树,AVL是三个创始人的姓名拼凑。
http://dongxicheng.org/structure/avl/(即是平衡的,而且还是搜索树,四种插入方式LL RR LR RL,然后通过树的旋转达到新的平衡)
红黑树:一种自平衡二叉搜索树。查找,插入和删除复杂度O(log n),树中的节点都通过颜色表示。根节点和叶子节点和空节点都是黑色。红色节点的左右孩子都是黑色 节点。
B树其实就是二叉搜索树,B-树是多路搜索树,B+是B-的变体。
哈希:
哈希表也可以称之为散列表,给出一个key可以映射到表中一个位置来访问记录。这个映射函数叫做散列函数
图:
邻接矩阵(点到点)一个一位数组用于存储节点信息,一个二维数组用于存储点与点之间的边信息,如果有权重,就是权重值;如果有方向,那么出发点的权重就是线的权重,到达点的权重就是无穷大。
关联矩阵(点和边),对于点多边少的情况,使用关联矩阵非常的不合适。
邻接链表(各种点),为了方便数据访问,用一个一维数组存储节点,该一维数组的每一个item包含两个内容,data用于记录数值,firstedge用于指向它的临界链表的第一个节点。对于后面的链表的每一个节点,第一个存储的是一位数组的下标,第二个节点是指向链表的下一个节点。
4,set怎么保证不重复
首先讲一下map的实现原理,map的效率很快,是用空间换时间,内存消耗比较大。Map其实也是通过数组和链表实现的,给出一个key,通过hash函数可以获取到index以及hashcode,可以把index看做是不同的区域号,然后再通过链表存储对应的值就可以,这样就可以实现map的无限增加。然而可能同一个key,也可能计算出相同的index和hashcode.这就需要解决冲突。而Set其实就是依赖map来实现的,这样就能保证了元素的不重复性质。
5,数据库使用什么数据结构?为什么不用二叉树?
http://media.open.com.cn/media_file/rm/fushi/0709/shujukgljyy/web/lesson/chapter2/j2.htm
看什么类型的数据库,层次性数据库采用的是树;图形数据库采用的是图结构;关系数据库采用的是线性表结构。
关系数据库就是不同的实体数据,然后通过关系描述。如果用二叉树无法表示这种关系。
6,线程和进程概念,区别?通信,互斥,同步?
启动一个应用程序其实就是启动了一个进程,进程有自己的内存空间,而在进程中可能有多线程,多线程共享内存。线程之间交互比较容易。
http://blog.csdn.net/pizi0475/article/details/5364265
7,解释数据库里的事务。
数据库中的事务可以看作是一系列操作序列的集合,把数据库从一种一致性状态变换到另外一种一致性状态,并且保持ACID属性。
以BEGIN TRANSACTION开始,以COMMIT或ROLLBACK结束
8,抽象类和接口的区别?
接口要被实现,抽象类是被继承。抽象类中还能拥有方法的实现,而接口中只能有方法的声明。接口中的方法必须被实现,抽象类其实就可以看作是一个父类,可以有实现方法,对于抽象方法,子类必须实现这些方法。接口中可以有变量但都是static final的。可以实现多个接口,但是只能是单继承。
9,列举常见排序算法。
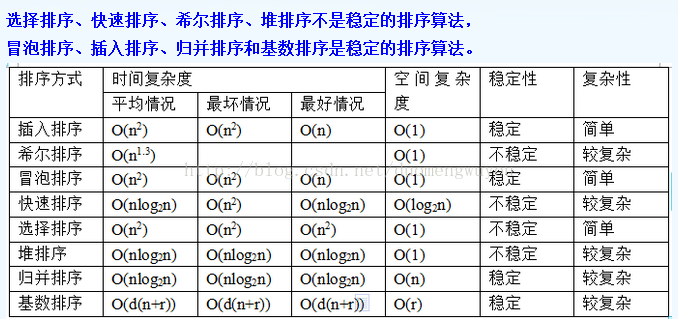
10,最擅长的技术。
11,最近课余时间学了哪些新知识?一般都在哪里获取?
12,是否排斥用JAVA?
不排斥,java是跨平台的,随着硬件的发展,也是以后的趋势。而且java是面向对象的语言,编写方面比较简单一些。对于c++中常见的垃圾回收,在java中也可以依托虚拟机实现,省去了程序员的很多工作。
效率低的原因是java先编译成字节码.class文件,然后.class文件通过jvm解释执行在机器上。而c++等都是直接编译后执行在机器上面。Java非诚的复杂,开发周期也长。
13、内存受限制的机器上如何对如下格式的文件数据排序,文件特别大
姓名 学科成绩
张三 90
李四 95
...
成绩作为键值对其进行排序
这个题不知道怎么回答,我说用,计数排序.
【http://blog.csdn.net/tanyujing/article/details/8534843计数排序就是能够知道每一个数字出现了多少次。知道所有数字的最小值和最大值。】
最后她说一个方案,分数只有0-100, 就把数据保存为101个文件
首先读入数据,根据分数写到对应的文件
估计她的大概思想是桶排序。
15、对hadoop的理解?了解mapreduce吗?讲一下mapredecue的思想?
Hadoop是apache2005年引入lucene的子项目nutch的一部分引入的。Lucene项目是一个开源代码的全文搜索引擎工具包,nutch是一个开源的搜索引擎。
Hadoop的灵感来源于google的gfs。
Hadoop的主要是HDFS和MapReduce。HDFS是GFS的开源实现,主要是提供分布式的文件存储。MapReduce是一种分布式的计算框架。
Hbase:分布式数据库
Hive:数据仓库
Pig:高级的数据流语言
Zookeeper:解决分布式系统上的一致性问题
HDFS分为NameNode和DataNode。文件目录都存放在NameNode上面,当然了NameNode也有备份节点。然后就是DataNode,默认每一块数据的大小是64M,然后数据冗余的放在多个DataNode上面。
几个优势:
不论读写,都与主控服务器相关,主控服务器挑选数据服务器与客户端交互,然后进行数据的读写。如果有了改变也是数据节点主动访问NameNode来获取改变信息,而不是主节点主动告诉数据节点。
读取从一个节点获取;写入则是一对多的写入。是节点传递节点的实现数据的复制传递,这样也能实现了一对多的数据存入。
Map函数和Reduce函数,将输入的key,value通过指定的方法,进行map和reduce.Master进行分配,有mapservers和reduceservers。Map就是将指定的key,value处理为中间结果,然后reduce再将中间结果生成设定的结果。
在Hadoop中,任务都是通过job的形式提交。提交的job中包括数据和程序。然后在map完成之后系统会进行连接和划分。连接就是自动将相同key的合并一下,划分就是将结果按key分区。
16、常看那些技术网站博客等
17、自己觉得最大的优点
18、参与项目时遇到的困难
19、想在哪里工作,为什么?














 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









