







说明
在本系列的前两篇文章, 正则表达式匹配可以简单快速的“ 和”正则表达式匹配:虚拟机的方法“ ,介绍了基于DFA的正则表达式匹配和基于NFA。 都基于玩具优化教学的基本实现思路。 本文基于。
我花了2006楼的夏天代码搜索 ,它可以让程序员的搜索代码使用规则的来源。 就是,它让grep通过世界公共源代码。我们原计划用PCRE正则表达式的搜索, 直到我们意识到,它使用了回溯算法, 意义容易让搜索指数时间或任意堆栈深度。 因为代码搜索正则表达式在接受任何来自互联网, 使用pcre会让简单的拒绝服务攻击。 作为一种替代PCRE,我写了一个新的,仔细审查了正则表达式解析器 缠 开放源码的grep实现,它使用一个快速的DFA。
在接下来的三年,我实现了一批新的后端 集体替换grep代码和扩大 功能超越什么是POSIX grep的需要。 结果,研究,提供了大部分的界面很 使用C + +接近PCRE的PCRE功能性的,但它保证线性时间 执行和一个固定的堆栈的足迹。 RE2是现在广泛使用在谷歌,在代码搜索 和内部Sawzall中和Bigtable。
截至3月2010,M是一个开源 所有开发项目,在公共场合进行。 这篇文章是一个游览的源代码, 技术在前两篇文章中展示了如何将一个。
步骤1:解析
在早期,正则表达式有一个很简单的语法,模仿在第一篇文章中解释简单的概念:级联, 重复,和交替。 有一些花哨的功能:字符类,+和?运营商, 和位置^和美元 今天,程序员期望。刺耳的钟声和口哨一个现代的正则表达式。工作 解析器是意义上的DIN使 和提炼它回到原来的基本概念。 RE2分析器正则表达式数据结构,定义H正则表达式。 。它是非常接近原始egrep语法,更特殊的少数:
- 字符串表示的
kregexpliteralstring节点,占比串联个人不 记忆kregexpliteral节点。 - 计数重复为代表的
kregexprepeat尽管 节点,表示不能直接实现; 我们会看到他们怎么编出来的。 - 字符类是不是一种简单的列表的范围,或作为一个位图 但平衡二叉树的范围。这种表示是更复杂比简单的列表,但 处理大量的Unicode字符类的关键。
- “字符”字符类中获得一个特殊的节点类型, 一样的“字节”。两者之间的匹配时 UTF-8输入文本的差异,操作方法的默认模式。
- 不区分大小写匹配使用一种特殊的标志和特殊情况下的 ASCII范围而不是二元字符类:
(?我是ABC)变成美国广播公司与不区分大小写 点代替[ ] [ ] [ CC AA,BB ]。基于最初使用后者, 但太密集的记忆,特别是基于树的特征的。
研究的解析器是parse.cc这是手写的。 解析器,既避免了根据特定的解析器生成器 ,因为现代的正则表达式的语法是不足以保证特殊照顾。 分析器不使用递归下降,因为递归深度将 潜在无限的可能 栈溢出,特别是在环境 螺纹。相反,解析器保持一个明确的解析堆栈,作为生成的LR(。
令我惊讶的一件事是真实用户的方式, 写入相同的正则表达式的各种 。例如,它是常见的单字符类使用 代替—【。】而不是\。或交替 而不是字符类—一个| | | D B C而不是[广告]。 解析器需要特殊照顾,以最有效的形式, 【。】仍然是一个单独的字符和文字一个| | | D B C仍然是一个字符类。 应用这些简化分析过程中,而不是在第二遍, 避免不必要的大的中间。
走正则表达式
具有解析正则表达式,现在是时候来处理它。 解析形式是一个标准的树,这表明它与 标准递归处理。不幸的是,我们不能假定,有 足够堆栈来做。一些偏僻的用户可能会给我们 类似正则表达式(((((((((( *)*)*)*)*)*)*)*)*)*)*(更大的),导致堆栈溢出。 代替遍历的规则,必须使用 显式表达。的学步车模板隐藏堆栈管理,使这一限制 很不错。
回顾过去,我认为树的形式和学步车可能是个错误。如果递归是不允许的(如本例), 它可能更好地避免递归表示完全相反, 存储解析规则逆波兰表示法作为汤普森的1968篇文章这示例代码如果RPN形式。 深度用记录的最大堆栈的表达, 遍历将一堆完全的大小和 则表示在一个单一的穿越。
步骤2:简化
下一个加工步骤简化, 它改写成简单的复合算子 使后处理容易。 对代码的问题时,大多数的简化通过进入分析器, 因为简化急切地保持中间存储下来。只有一个任务 今天离开计数重复扩张喜欢X {2,5 }为 序列的基本操作XX(x(x(x)?)?)?。
步骤3:编译
当正则表达式只使用基本的操作 在第一篇文章中所描述的,它可以编译使用技术概述了那里 应该很容易。看到对应。
有一个有趣的研究编译器,我学到 从汤普森的grep。它收集了UTF-8字符类 到自动机读入一个字节的时间。 换句话说,UTF-8解码是建立在自动机。 例如代码点从0000,匹配任何Unicode FFFF(十六进制), 自动机接受任何的:
方法::fullmatch(S,“重”) RE2::partialmatch(S,“^重新$”
- 对正则表达式匹配的子字符串?
方法::partialmatch(S,“重”)
- 对正则表达式匹配的子字符串?如果是这样的话,在哪里?
方法::partialmatch(S,”(重新)”,与匹配)
- 对正则表达式匹配的子字符串?如果是这样的话,在哪里?该submatches在哪里?
方法::partialmatch(S,”(R +)(E +)”,和M1,M2)
显然都是下一个特殊的情况。 点从用户的角度来看,是有意义的只提供第四, 但实施的区别是因为它可以实现 更早更有效地比问题。
有regexp匹配整个字符串?
<trans data-src="" re2::fullmatch(s,="" "re")"="">方法::fullmatch(S,“重”) RE2::partialmatch(S,“^重新$”
这是我们考虑的问题第一篇文章 。在那篇文章中我们看到了一个简单的DFA,建在飞,但 超过了所有其他的DFA。研究采用DFA对于这个问题,但该方法更高效的内存和多线程 友好。它采用了两个重要的。
能冲洗的DFA缓存。一个精心选择的正则表达式和输入的文本可能 促使DFA的输入的每一个字节的创建一个新的国家。 上大量投入,这些州堆快。 RE2 DFA对待它的状态作为一个缓存;如果缓存填充,让他们重新开始 。这让DFA运行在一个固定的内存量的过程 尽管在 状态数考虑一个任意的。
在编译程序不存储状态。的DFA在第一篇文章在编译程序追踪 一个国家是否出现在一个特定的列表使用一个简单的 序号字段
的S - > lastlist和listid)。 跟踪可以插入消除常数与 重复做名单的时间。 在多线程程序中,很方便的分享 单一研究对象在多个线程,这就排除了 序列。 但我们肯定插入消除在不断重复 想表的时间。 幸运的是,有一个数据结构的设计完全 这种情况:稀疏集。 RE2执行sparsearray (见模板。使用未初始化的内存的乐趣和利润“思想的概述。)有regexp匹配一个字符串的字符串?
方法::partialmatch(S,“重”)
最后一个问题问 regexp匹配整个字符串;这一要求 是否匹配在字符串中的任何位置。 我们一 能问题到最后的减少
重新进入*。*。但是, 我们最好重写它可以做的*。处理后部分分别。找一个字的第一个字节。DFA或编译程序的形式可以分析 确定是否每一个可能的匹配从相同的第一个字节, 像搜索时
(研究|随机)。在这种情况下,当DFA正在开始一个新的比赛, 可以避免一般DFA寻找 第一字节的使用memchr,这是使用特殊的硬件往往。保释出早期。如果被问到的问题是是否有一部分匹配 (例如,有比赛
AB +进入ccccabbbbddd?) ,DFA可以提前停止, 一旦AB。通过改变回路 到DFA检查一个匹配后的每一个字节,它就可以 有任何比赛停止,即使不是最长的。 记住来电者只关心是否匹配, 不是它是什么,所以没事的DFA不寻找。这听起来像是一个比 用于最后的问题略有不同的DFA,它是。DFA的代码是 写作为一个单一的广义循环,看起来在控制 行为标志,如是否有文字的第一 字节寻找还是尽早停止。 2008当我写的DFA,代码,它的速度太慢, 旗帜在内部检查。相反,该
inlinedsearchloop函数需要三个布尔标志然后 称它为从八个不同的功能 使用的所有组合的专业。 的电话时,必须作出,这是一个八 专门的功能,而不是原来的。 2008,这个技巧,创造了八个不同的副本 的搜索循环,每一个严密的内在 优化其回路的具体情况。 我最新版本的g++拒绝最近注意到,inlinedsearchloop因为它是这样 大功能,所以不再有八个程序中的不同 副本。它可能重新 八份的inlinedsearchloop一个模板的功能,但它似乎没有问题了: 我试和专业代码没有任何。有regexp匹配一个字符串的字符串?如果是这样的话,在哪里?
方法::partialmatch(S,”(重新)”,与匹配)
来电者变得更加苛刻。 现在想知道比赛是不 关心submatch边界。 我们可能回落直接NFA仿真 ,但它显着的速度相比 惩罚的。相反,如果再努力一点,我们可以 挤压这信息的DFA。
找到确切的终点。一个DFA标准介绍对待每一个国家 代表NFA状态无序的集合。 而如果我们把DFA状态为一个偏序集的NFA状态, 我们可以追踪的可能性将优先于他人, 使DFA可以找出确切的地方。
在POSIX的规则,规定相应的比赛开始 在输入前优先于国家相应的 到以后的开始。 例如,而DFA状态占五,NFA
{ 12345 }它可能代表{ } { } 4 3比赛因 一:1或4是 优先从国家比赛2,3,或5。照顾“的一部分,左边的“左”长。” 实施“长”的要求,每一次 比赛发现在一个特定的国家,DFA记录它,并继续 只执行这些国家相等或更高的优先权。 一旦DFA跑出来状态,最后记录的比赛结束 的左边的位置是。在Perl风格的规则,“左”的语义 处理相同,但是Perl不需要时间最长的 最左边的比赛。相反,国家名单是完全有序:没有两个 态有相同的优先级。在一个交替
一个| B美国探索A有比 美国高等priortiy探索B一。××就像是一个循环的交替, 之间保持决定另找X和 匹配表达式的其余部分。 每个交互提出了更高的优先级,寻找Xpictorally,两者。分裂节点在第一篇文章: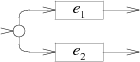
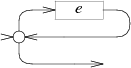
分裂的优先路径离开前。 非贪婪的重复是一个贪婪的重复与 优先。
找到一个Perl比赛结束,每次找到一个匹配的 在一个特定的国家,DFA记录它,而是继续执行 只有那些状态的高优先级。一旦失控的状态,它的立场, 最后记录的是结束的 最高优先级一定。
这是伟大的:现在我们知道这场比赛结束的地方。 但对方想知道比赛开始。 我们该怎么做
运行DFA向后查找的开始。当学习正则表达式在计算 阶级理论,是一个标准的运动来证明,如果你 正则表达式和反向所有串连 (,
【GG ] OO +单成为埃尔格+ O [克]) 你最终有一个正则表达式匹配任何字符串,逆转原 匹配。 这样的类,而不是演习 正则表达式和自动机的许多有实用价值, 但! DFA的报告只在比赛结束,但是如果我们运行的DFA 落后的文字,你看到 DFA的为比赛结束会开始。 因为我们扭转的输入,我们必须扭转 正则表达式,通过反转所有串连 。编译后倒的正则表达式, 我们运行后发现了 从终点DFA扫描,处理所有国家同等优先 和寻找可能的最长时间的终点。 是最左边的点的字符串匹配 能开始,因为我们是认真的上一步 最后一个选择左匹配,它的。
这个正则表达式匹配该字符串?如果是这样的话,在哪里?该submatches在哪里?
方法::partialmatch(S,”(R +)(E +)”,和M1,M2)
这是最难的问题对方可以问。
运行DFA回答前两个部分。该方法快速,但它只能回答前两部分。 直接NFA需回答第三模拟部分。 仍然,DFA是足够快,它就调用它 为前两个。 使用DFA找到整体的数量 文本匹配减少的过程 NFA必须大文本有助于在搜索时,小目标, 也完全避免了当答案 NFA的第一个问题是“不,”。
一旦DFA找到匹配的位置,它是 时间调用NFA到submatch边界。 NFA是渐近有效的线性尺寸的输入的线性尺寸的 正则表达式在(文本), 但因为它必须复制在submatch边界集,可以慢 它在一般情况下比BackTracker像PCRE。 兑换保证的最坏情况下的性能, 平均情况下遭受一点。 正则表达式匹配:虚拟机的方法“)。
一些重要的一般情况下不需要 全NFA机械保证有效地执行。 他们可以处理自定义代码前下降 回。
如果可能的话,使用一一通NFA。NFA花费时间跟踪多个 submatch边界集(特别是,复制他们),但它是可以识别的一大类, NFA 从不需要保持一个以上的组的边界位置的正则表达式, 无论什么。
让我们定义一个“一通正则表达式” 得以与锚定的比赛中的每个字节的输入 物业的正则表达式,只有 一个替代方案,使得一个给定的输入字节 为感,
××YX *是:你读过X“直到Y然后,你看Y,然后你继续阅读X“美国 没有一点你要想做什么或备份 和尝试不同的猜测。 另,×××不是一次:当你 看着输入X,目前还不清楚是否应该 用它来延伸××或是最终的X更多:([ ^×]×)×(*。)进行一次;(。*)x(*。)是不是。(\ D +)-(\ D +)进行一次;(\ D +)(\ D +)。是不是。用于识别一个通过正则表达式 简单的直觉是它总是很明显当重复结束。 还必须立即明显的分支
|采取:x(y | Z)是一通,但(XY | XZ)是不是。因为只有一个可能的下一个选择, 一通NFA实现不需要作出的一份 submatch边界集。 一引擎执行通过两部分。 在编译期间,本分析了 汇编形式该程序以确定是否 是一通。 如果这样计算,发动机的数据结构的记录什么 在每个可能的状态和输入做字节。 然后在执行一次引擎可以通过悬挂的字符串, 找到匹配(或不),以及。
如果可能的话,用一点状态BackTracker。backtrackers像PCRE避免的submatch设置复制: 它们有一个单一的集和覆盖并恢复它在 。的正确性,这种方法必须愿意 重温一个字符串多次相同的部分,每NFA状态至少一次 。 仍然只是一个线性扫描时间,虽然部分:指数时间 PCRE是一系列 每NFA多次访问相同的状态,因为该算法不记得 了特定的路径。
位状态,以标准 BackTracker回溯算法,与手动栈来实现的, 添加位图跟踪(状态,字符串的位置)对 已经。对于小的正则表达式匹配 对小的字符串,分配和清除位图是显着 的NFA状态复制 便宜。采用位状态BackTracker当位图最多32字节。
如果一切都失败了,使用标准的NFA。
分析
研究不允许PCRE功能,不能实现 有效利用自动机。(最显著的特征是反向引用。) 作为放弃这些难以实现(常常错误地使用) 特点,研究可证明分析正则表达式或 自动机。 我们分析的例子使用已经就问题本身, 在
memchr在分析 是否正则表达式是一个通行证。 RE2还可以提供分析,让更高级别的应用 速度。匹配范围。Bigtable存储记录 为排名保存,它有效地扫描所有行的名字 在给定的范围内。Bigtable也允许客户指定的正则表达式过滤器: 扫描跳过行名称匹配的规则不是一个确切的表达是方便一些客户只使用正则表达式过滤 不担心设置 它。这些客户可以改善这种扫描通过问问题来计算字符串可能匹配的正则表达式 然后限制扫描只是范围 范围 为例, 效率。
(你好|世界)+,方法::possiblematchrange可以确定所有可能的匹配范围在[您好,worldworle]。 效果图从开始探索的DFA状态, 寻找路径具有最小可能的字节值 路径和最大可能和字节值E在结束worldworle是不是写错:worldworldworld<worldworle但不世界:possiblematchrange必须经常截断字符串 指定范围内,当它,它必须绕绑上。所需的子字符串 。假设你的方式来检查它的字符串列表 出现的子字符串的一大,有一个有效的文本(例如,也许你实现 Aho-Corasick算法 ),但现在你的用户希望能够做有效的正则表达式搜索过。 字符串的正则表达式经常有大量的在他们;如果这些可以 确定,他们可以输入字符串搜索,结果 然后字符串搜索,可以使用正则表达式搜索设置 ,过滤是必要的
filteredre2类实现了这一分析。给定一个正则表达式的列表,它走正规 表达式的计算一个字符串 布尔表达式并返回字符串的列表。 为,filteredre2转换(你好| HI)世界[A-Z] + Foo在布尔表达式 ”(HelloWorld或正望)和Foo“ 并返回这三个字符串。 给多个规则,filteredre2将 各成一个布尔表达式并返回包含所有的字符串。 之后,这样的字符串,filteredre2可以对每个表达式 识别正则表达式可能存在的集合。 这种过滤可以一些实际的正则表达减少搜索。这些分析的可行性在很大程度上取决于它们的输入简单 。第一个使用DFA的形式,而第二采用解析 正则表达式(
regexp *)。这种分析是比较复杂的 (甚至不可能) 如果允许非常规特征研究。国际化
基于对正则表达式描述的Unicode序列 可以搜索在UTF-8或Latin-1编码的文本。 像PCRE和其他正则表达式的实现, 命名
[ [ ] ]:数字:和\ D只包含ASCII,但Unicode的购房群体像磷{和}包含完整的Unicode。挑战 RE2是实施大 Unicode字符集高效、紧凑。 我们看到那上面的字符类为代表 为平衡二叉树,但同样重要的是 保持图书馆面积小,这意味着编码的必要 。国际化的字符类,研究实现了 Unicode 5.2类物业 (,
\ PN或磷{路}) 以及Unicode脚本属性 ,磷{希腊})。 这些应使用时的比赛并不是 限于ASCII字符 ,\ PN或磷{和}而不是[ [ ] ]:数字:或\ D)。 RE2不执行其他Unicode特性 Unicode标准# 18:Unicode正则表达式)。 Unicode组表映射一组名称数组 到代码范围定义的组。 Unicode 5.2表需要4258码的范围。 Unicode代码点以来,已超过65536,每个范围 通常需要两个32位的数字(开始和结束), 或34字节的总数。 然而,因为绝大多数的范围只涉及 代码点小于65536每个 组分为一组16位的范围和一组32位的范围, 切割表足迹18。研究了不区分大小写匹配(启用
(?我))根据 Unicode 5.2规范: 它A与A,Á与á,和K与K(开尔文)和S与ſ(很长的)。 有2061个案例的具体特征。 RE2的表映射的每个Unicode代码点到下一个 最大点,应被视为同一 。例如,B对B和B对B。大多数这些循环仅包含两个字符,但 有更长的:例如, 的K对K,K对K(开尔文符号),K回到K这表是非常 :A图A,B图B,等等。 而列出的每一个人物,我们可以列出的范围和:A通过Z地图的价值加上32,A通过J地图的价值减去32,K图K(开尔文符号又),等等。 有案件范围运行的上/下对 上/下的是一种特殊的对。 本表从2061项,以16字节编码 279项,以削减。研究没有实现在Python命名为特征
你“\n {拉丁字母X }”别名“X”。 甚至忽略了明显的用户界面问题,所需要的表格将在150。测试
我们怎么知道RE2代码是正确的? 测试正则表达式的实现是一个复杂的任务,特别是当 实施有许多不同的代码路径的问题。 其他提高,PCRE,和Perl ,建有大型测试套件,可以手工维护,随着时间的推移。 RE2具有小数量的手写检查基本 功能,但它很快变得清晰,手写 单独的测试将需要太多的努力创造和保持 如果他们盖好,大部分问题。 相反测试是通过产生 检查。
给定一组小的正则表达式和运算符,
regexpgenerator类生成所有可能的表达式中使用的那些 算子在一个给定的尺寸。然后stringgenerator生成所有可能的 字符串给定字母表到一个给定的大小。 然后,为每一个正则表达式和字符串测试检查每一个输入输出的四个不同的正则表达式引擎 的 同意每2,其他,和只写了实施一个平凡回溯 测试, 和(通常是)和PCRE本身。 RE2不匹配PCRE对所有的情况,所以分析检查,RE2和PCRE不同意情况下 ,列在注意事项下面一节。 除了当正则表达式涉及这些边界情况的测试要求, 2和PCRE同意的结果 上。详尽的测试,必须限制自己小的正则表达式 和小的输入字符串,但大多数错误可以通过小的测试案例暴露。 枚举所有小测试用例捕获几乎所有的错误,让过去的 几方面的笔试。 即便如此,研究还包括一个随机试验,变异
regexpgenerator和stringgenerator产生较大的随机实例。罕见的随机测试抓住点什么 ,较小的穷举测试 它错过了 ,但它仍然是一个很好的保证,大的表达式和文本 继续。性能
问题是在小型的搜索和大的快PCRE竞争。表现为小的 检索报告在微秒, 由于搜索的时间是独立于实际的文本在10字节大小的 (在这些例子。 )大搜索性能报道中Mb / s, 搜索时间通常是线性自。
报道的基准是由
研究/试验/ regexp_benchmark.cc。目录研究/来源/浏览/ benchlog有积累的结果。 (所有测试运行PCRE 8.01版在写作的时候,最新的。汇编基于对3-4x编译速度比PCRE regexp:
系统 PCRE 研究 AMD Opteron 8214的他,2.2 GHz的 5.8µ的 14.1µ的 英特尔酷睿2双核e7200,2.53 GHz的 3.8µ的 10.4µ的 英特尔至强5150,2.66 GHz(MAC PRO) 5.9µ的 21.7µ的 英特尔酷睿2 5600,1.83 GHz(MAC MINI) 6.4µ的 24.1µ的 时间编写了一个简单的正则表达式。 所不同的是约5-10毫秒每regexp。 这些时间安排包括花费的时间将正则表达式解析后 和。我们预计,常见的情况是,在比赛中 缓存时,速度是关键, 使编译时不太。
编译后的形式的一个问题是大于一个文件对象, 几千字节与几百个字节为一个典型的小的正则表达式。 RE2做更多的分析表达式在编译 和更丰富的形式存储到文件。 RE2保存状态(部分建在DFA)电话: 运行后的几场比赛,一个简单的方法可能是使用 10KB,但更多的比赛不典型的足迹。增加 RE2限制总空间的使用对用户。
全场比赛,没有submatch信息 。我们看到那上面的一些搜索比别人努力 ,RE2实现不同用途不同的搜索 基准。
*美元。在一个随机生成的输入文本的大小。 它有平面搜索。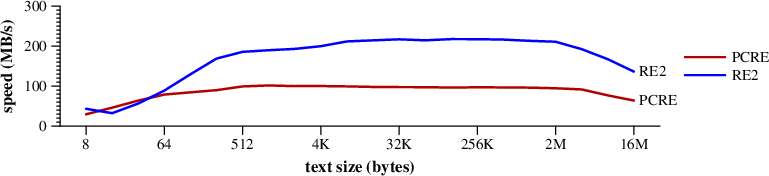
搜索速度 *美元。在随机的文本。(MAC PRO)研究采用DFA运行搜索。
全场比赛,通过一个正则表达式,submatch信息,微小的弦 基准搜索。
([0-9] +)-([0-9] +)-([0-9] +)在字符串650-253-0001,要求对三submatches位置:系统 PCRE 研究 AMD Opteron 8214的他,2.2 GHz的 0.8µ的 0.5µ的 英特尔酷睿2双核e7200,2.53 GHz的 0.4µ的 0.3µ的 英特尔至强5150,2.66 GHz(MAC PRO) 0.6µ的 0.3µ的 英特尔酷睿2 5600,1.83 GHz(MAC MINI) 0.7µ的 0.4µ的 比赛 ([0-9] +)-([0-9] +)-([0-9] +)进入650-253-0001。研究采用OnePass匹配引擎运行搜索,避免 全NFA的开销。
全场比赛,暧昧的正则表达式,submatch信息,微小的弦 。如果regexp是模糊的,可能无法使用 OnePass引擎,但如果正则表达式和字符串都是小问题,可以利用这 bitstate引擎。
[0-9] +。(*。)进入650-253-0001:系统 PCRE 研究 AMD Opteron 8214的他,2.2 GHz的 0.6µ的 2.9µ的 英特尔酷睿2双核e7200,2.53 GHz的 0.3µ的 2.1µ的 英特尔至强5150,2.66 GHz(MAC PRO) 0.4µ的 2.3µ的 英特尔酷睿2 5600,1.83 GHz(MAC MINI) 0.5µ的 2.5µ的 比赛 [0-9] +。(*。)进入650-253-0001。在这里,RE2比PCRE明显慢,因为正则表达式不是 明确:它是不清楚是否附加数字 应该被添加到
[0-9] +或用来匹配”。'。 PCRE是优化匹配;当与字符串 不匹配,它的运行时间指数在 最长可以的情况下,和速度明显变慢甚至在常见的情况。 相反,RE2 plods线性速度无论 文本是否匹配。 特定的大小的速度取决于文本和正则表达式。 小这样的情况下,研究使用bitstate;在较大的情况下, 它。部分匹配,没有实际的比赛 。寻找一个部分(不固定)比赛要求匹配 引擎考虑比赛开始字节在每个字符串。 PCRE实现这一循环,试图从字符串中的每个字节 ,而研究的实现可以运行所有这些 。本研究分析 PCRE regexp实现比更彻底,导致潜在的加速。
这个基准搜索
有美元在随机生成的文本。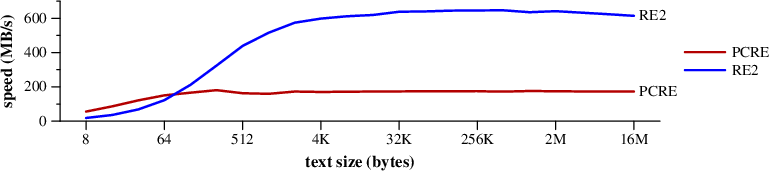
搜索速度 有美元在随机的文本。(MAC PRO)基于DFA的大部分时间都花在
memchr找领导APCRE的注意。A过,虽然它 似乎并没有多少优势。 我怀疑PCRE不会继续memchr在发现第一个A。下一个基准是有点困难,因为没有 领导角色
memchr为 看起来。[某]有美元。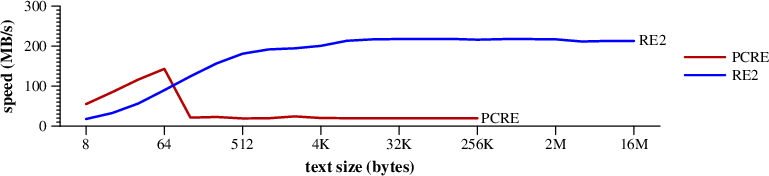
搜索速度 [某]有美元在随机的文本。(MAC PRO)PCRE退到慢得多的加工处理, 当RE2的DFA运行快速byte-at-a-time。
下一个基准是PCRE 看起来相当困难。
[ ~ ] *有美元。文本没有匹配的表达,但 PCRE扫描整个字符串的每个位置[ ~ ] *在实现没有比赛。 这最终以O(2)时间相匹配。 RE2的DFA是一个单一的线性。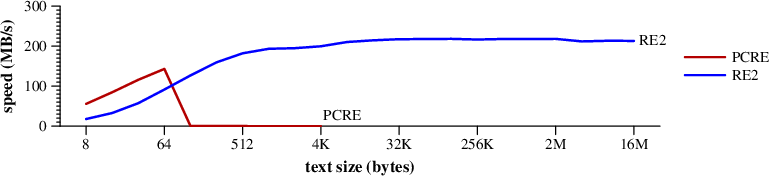
搜索速度 [ ~ ] *有美元在随机的文本。(MAC PRO)请注意,但在4K PCRE长文本。
搜索和分析使用 。另一个典型的重新发现和 是在分析一个特定的字符串。这个基准测试的随机生成一个文本
(650)253-0001最后再做一个 非锚固搜索(\ D { 3 } - | \(\ D { 3 } \)的+)(\ D { 3 } - D { 4 }),分别从7位数的电话代码 提取区。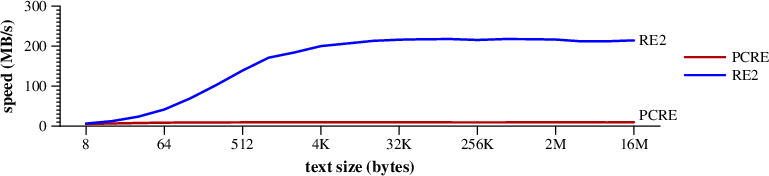
搜索和匹配速度 (\ D { 3 } - | \(\ D { 3 } \\)的+)(\ D { 3 } - D { 4 })
在结束了与随机的文本(650)253-0001。(MAC PRO)基于DFA的更快的搜索是负责改进的速度。
概要。 RE2大约需要10 KB的每个正则表达式,对比PCRE的50 kb左右。换 额外的空间,RE2保证线性时间性能, 虽然线性时间常数。
基于对速度运行的查询,问是否 字符串匹配但不要求submatch信息相同的 PCRE(,
方法::fullmatch或方法::partialmatch没有额外的参数)。当使用正则表达式来解析文本,RE2运行在大约相同的速度 作为明确的regexp PCRE。 它运行在大约一半的速度模糊的小比赛中, 和慢的暧昧中大的比赛。 数据大小涉及在这些情况下,通常是 足够小,运行时的区别是不是一个瓶颈。 (例如,任何性能损失比较解析文件消失所需的时间 名打开
RE2擅长在大量文本的搜索。 可以找到比多的比赛 PCRE,特别是如果搜索需要PCRE来。
这些基准比较的PCRE因为它是 最直接的比较:C / C + +和C / C + +,一个几乎相同的 接口。要强调, 基准是有趣的因为他们是比较 它的算法, 不是性能调优。 PCRE的选择算法,在至少在一般情况下, 被迫完全兼容的意义。
注意事项
研究明确不尝试处理所有的扩展, Perl了。 Perl扩展支持: 非贪婪的重复性;
\ D和 空;断言\,b,b,和\ Z。研究不支持任意的超前或lookbehind说法, 也不支持反向引用。 支持计数的重复,它是通过但\ D { 3 }成为D D D \ \ \), 这么大的重复计数是不明智的。 RE2支持Python风格(?P <名称> expr)不, 交替(?<名称> expr)和(?”name'expr)用网和Perl。基于PCRE的行为不匹配。有一些已知的情况下,研究不同 故意:
- 如果正则表达式包含一个重复的空字符串,
(*)+,然后PCRE将反复 序列作为结尾的空字符串,而不是具体的研究。 ,当(*)+反对AAAPCRE跑,+两次,一次比赛AAA第二次匹配空字符串。基于运行+只有一次,匹配AAA。因为政府捕获 右边的文本匹配,对于PCRE1美元将一个空字符串而研究1美元将AAA。 PCRE行为可以kludged为RE2如果。 - Perl和PCRE regexp不同的含义
\V。 Perl比赛只是垂直制表符的字符(VT,0x0b), 而PCRE匹配两个垂直制表符和换行符。 RE2选择。 - 在单线模式下,如果输入的文本的结尾是一个换行符, Perl和PCRE
美元在比赛之前或之后 最后的换行符。 RE2要求它的比赛后,结束了在很。 - 同样,在多行模式下,如果输入的文本结尾换行符 字符,Perl和PCRE不允许
^比赛后,通常 换行,在文本的最后的比赛。 RE2。 - 研究没有完全的国际化但不实施 基本Unicode属性类。
- 在UTF-8模式,PCRE POSIX定义否定
【[:^ XXX:] ]只有ASCII编码点的匹配, 所以【[:^α:] ]比赛的ASCII字符不在alpha,【^ [α] ]::匹配任何字符,不在alphaRE2改正:【[:^α:] ]和【^ [α] ]::这意味着任何Unicode字符不在alpha。
有少数的Perl和PCRE 模糊的特点,研究选择不执行。这些都是:
- “扩展”正则表达式的传统 遵循汉字代表 自己除非逃脱了规则,而 标点可能逃脱 除非是特殊的。
\ q应该有着特殊的意义 和\ #要匹配文字#。 Perl和PCRE接受了字母文字 信如果不(还)有意义。 因此,\ q匹配的文字Q意思是, 至少直到一个不同的介绍。 RE2拒绝未知逃脱字母而非 默默地把它们作为文字。 这有助于诊断使用的序列, RE2也不\ CX(见下文)。 - 研究不承认
\ CX作为或者剪切特性。 嵌入文字控制符使用C++字符串语法 或八进制或十六进制。 - 在POSIX,
b意味着退格键。 Perl,这意味着单词边界, 除了在字符类,当它意味着[ b ])。 RE2企图混淆不避免b作为 RE2 Backspace。b在POSIX模式, 识别边界在Perl作为文字模式, 始终拒绝在字符类匹配。 退位,嵌入一个字面上的退格键010。 - 研究不承认原子组合算子
(?>……)和+ +。这些主要是用来作为援助的性能带回溯。 研究提供了一个更。 - 研究不承认
\ C,G或X。 - 不承认 条件子模式研究
(?(……)……),(?#……)引用,模式(?R)(?1)(?P>foo),或C(?C. ..)。
默认情况下,RE2执行最多1MB(每1 为对象)
前卫和他们的DFA美国 这是足够的表达,但非常大的表达式 或模式与大数 重复可能超过这些限制。 耗尽内存在编译ok()重新。返回false, 详细解释error()重新。。 RE2不能跑出来,在文字记忆搜索: 将丢弃缓存的DFA 使用DFA和开始一个新的回收内存。 如果必须丢弃DFA太多,它会回落 上。概要
研究表明,它是可能使用自动机理论 实施现代回溯 像PCRE正则表达式库的几乎所有功能。因为它植根于自动机 理论基础,研究提供了强有力的 保证执行时间比,使高层次的分析 那将是困难的或不可能的Ad hoc实现 。最后,研究开源。有乐趣!
研究的实施和我的正则表达式的理解 都受益匪浅,和Rob Pike和 Ken汤普森的讨论在过去的几年。 Sanjay格玛沃特设计与实现C++接口文件其中, M的C + +界面模拟和来自 Srinivasan venkatachary。
filteredre2代码。 菲利普榛PCRE是一个惊人的 块代码。在比赛的大部分PCRE的正则表达式的特点 推RE2多会比其他方式越走越远, 和PCRE也作为一个优秀的实现对测试 感谢。本系列的下一篇文章”正则表达式匹配一卦指数,“幕后看看谷歌代码搜索工作。
- 如果正则表达式包含一个重复的空字符串,














 1124
1124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









