










一、概述
Nova(OpenStack Compute Service)是 OpenStack 最核心的服务,负责维护和管理云环境的计算资源,同时管理虚拟机生命周期。
Nova 在整个 OpenStack 架构中的位置如下图:
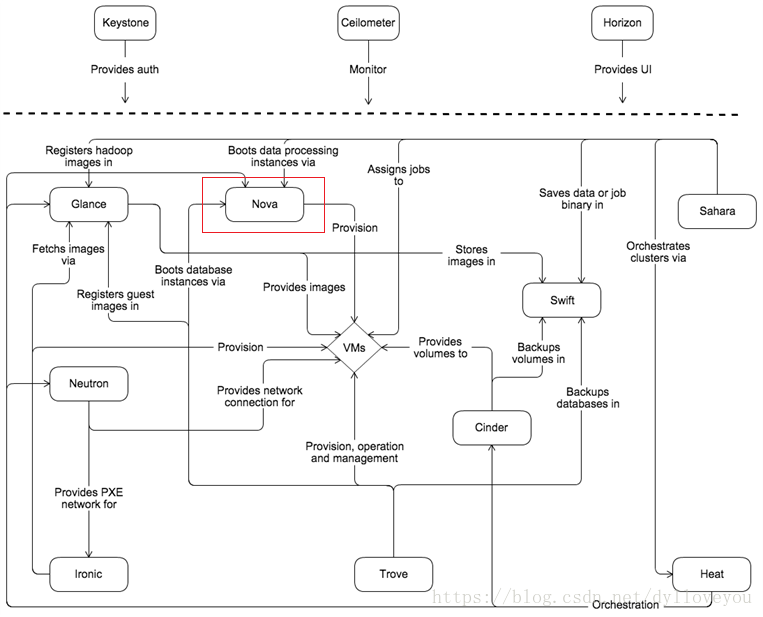
在上图中可以看到,OpenStack 很多组件都为 Nova 提供支持:
Glance 为 VM 提供镜像;
Cinder 和 Swift 分别为 VM 提供块存储和对象存储;
Neutron 为 VM 提供网络连接。
二、架构
Nova 逻辑架构如下图所示(红色方框内为 Nova 组件,方框外为 Nova 和 OpenStack 其他服务之间的调用关系):
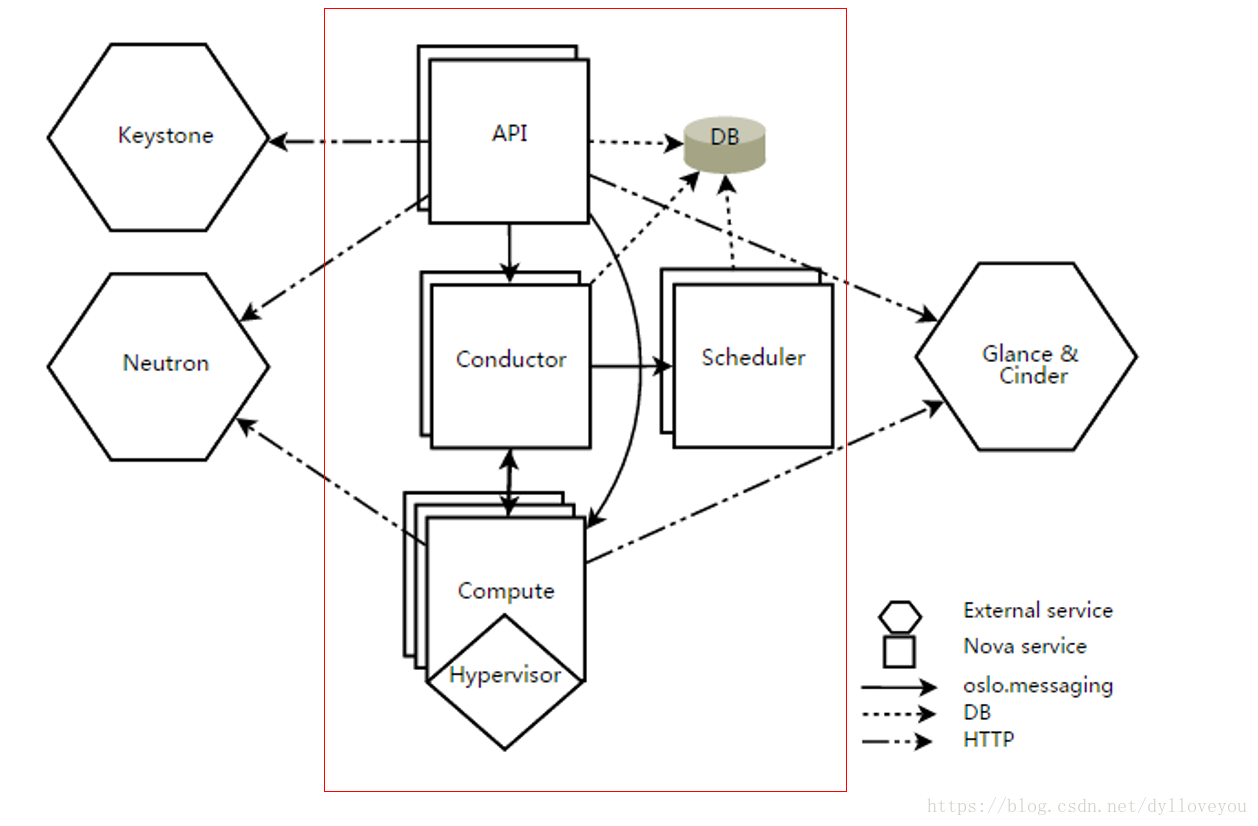
1.API
nova-api
接收和响应客户的 API 调用。
2.Compute Core
nova-scheduler
虚机调度服务,负责决定在哪个计算节点上运行虚机。
nova-compute
管理虚机的核心服务,通过调用 Hypervisor API 实现虚机生命周期管理。
Hypervisor
计算节点上跑的虚拟化管理程序,虚机管理最底层的程序。不同虚拟化技术提供自己的 Hypervisor。 常用的 Hypervisor 有 KVM,Xen,VMWare 等。
nova-conductor
nova-compute 经常需要更新数据库,比如更新虚机的状态。 出于安全性和伸缩性的考虑,nova-compute 并不会直接访问数据库,而是将这个任务委托给 nova-conductor。
3.Console Interface
nova-console
用户可以通过多种方式访问虚机的控制台:
nova-novncproxy,基于 Web 浏览器的 VNC 访问。
nova-spicehtml5proxy,基于 HTML5 浏览器的 SPICE 访问。
nova-xvpnvncproxy,基于 Java 客户端的 VNC 访问。
4.Database
Nova 会有一些数据需要存放到数据库中,一般使用 MariaDB。
Nova 使用命名为 “nova” 的数据库。
5.Message Queue
在架构图上我们看到 Nova 组件之间的连线,它们都通过 Message Queue 联系。
OpenStack 默认是用 RabbitMQ 作为 Message Queue。
Nova 部署架构如下图:
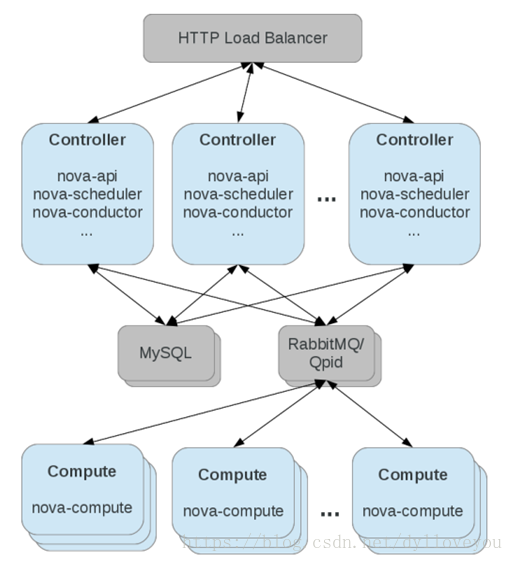
部署架构特点:
- 无中心结构
- 各组件无本地持久化状态
- 可水平扩展
- 通常将nova-api、nova-scheduler、nova-conductor组件合并部署在控制节点上
- 通过部署多个控制节点实现HA和负载均衡
- 通过增加控制节点和计算节点实现简单方便的系统扩容
三、组件设计思想
这里介绍的 Nova 组件设计思想,其实也是 OpenStack 的组件设计思想,OpenStack 的所有组件设计都遵循此思想。
1. API 前端服务
nova-api 作为 Nova 组件对外的唯一窗口,向客户暴露 Nova 能够提供的功能。当客户需要执行虚机相关的操作,能且只能向 nova-api 发送 REST 请求。
设计 API 前端服务的好处在于:
- 对外提供统一接口,隐藏实现细节
- API 提供 REST 标准调用服务,便于与第三方系统集成
- 可以通过运行多个 API 服务实例轻松实现 API 的高可用,比如运行多个 nova-api 进程
2. Scheduler 调度服务
对于某项操作,如果有多个实体都能够完成任务,那么通常会有一个 scheduler 负责从这些实体中挑选出一个最合适的来执行操作。
Nova 有多个计算节点, 当需要创建虚机时,nova-scheduler 会根据计算节点当时的资源使用情况选择一个最合适的计算节点来运行虚机。
除了 Nova,块服务组件 Cinder 也有 scheduler 子服务。
3. Worker 工作服务
调度服务只管分配任务,真正执行任务的是 Worker 工作服务。
在 Nova 中,这个 Worker 就是 nova-compute 了。 将 Scheduler 和 Worker 从职能上进行划分使得 OpenStack 非常容易扩展:
- 当计算资源不够了无法创建虚机时,可以增加计算节点(增加 Worker)
- 当客户的请求量太大调度不过来时,可以增加 Scheduler
4. Driver 框架
OpenStack 作为开放的云操作系统,支持业界各种优秀的技术。这种开放的架构使得 OpenStack 能够在技术上保持先进性,具有很强的竞争力,同时又不会造成厂商锁定(Lock-in)。OpenStack 的这种开放性一个重要的方面就是采用基于 Driver 的框架。
以 Nova 为例,OpenStack 的计算节点支持多种 Hypervisor。 包括 KVM, Hyper-V, VMWare, Xen, Docker, LXC 等。
nova-compute 为这些 Hypervisor 定义了统一的接口,hypervisor 只需要实现这些接口,就可以 driver 的形式即插即用到 OpenStack 中。
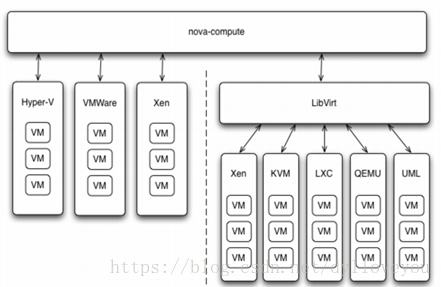
Glance、Cinder 和 Neutron 都有 driver 框架的应用 。
5. Messaging 服务
nova-* 子服务之间的调用严重依赖 Messaging。Messaging 是 nova-* 子服务交互的中枢。带来以下好处:
- 解耦各子服务。子服务不需要知道其他服务在哪里运行,只需要发送消息给 Messaging 就能完成调用。
- 提高性能。异步调用使得调用者无需等待结果返回。这样可以继续执行更多的工作,提高系统总的吞吐量。
- 提高伸缩性。子服务可以根据需要进行扩展,启动更多的实例处理更多的请求,在提高可用性的同时也提高了整个系统的伸缩性。而且这种变化不会影响到其他子服务,也就是说变化对别人是透明的。
6. Database
OpenStack 各组件都需要维护自己的状态信息。比如 Nova 中有虚机的规格、状态,这些信息都是在数据库中维护的。每个 OpenStack 组件都有自己的数据库。
总结 Nova 组件设计思想的特点:
- 分布式:由多个逻辑和物理上均可分离的组件组成,实现灵活部署
- 无中心:可以通过增加组件部署实例来实现水平扩展
- 无状态:所有组件无本地持久化状态数据
- 异步执行:大部分执行流通过消息机制实现异步执行
- 插件化、可配置:大量使用插件机制、配置参数实现灵活的扩展与变更
- RESTful API:支持 RESTful 方式访问的 API,方便客户端访问,方便集成到其他应用系统
四、组件详解
在详细讲解 Nova 各个组件之前,先以虚拟机创建流程为例介绍各组件之间的交互。
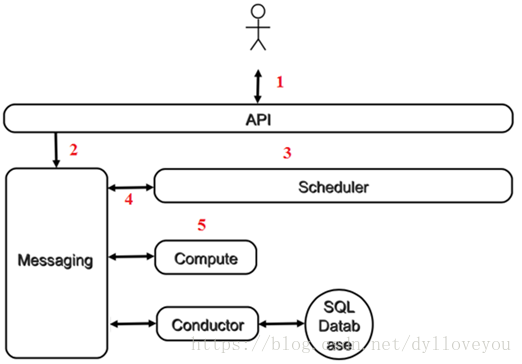
1)客户(可以是 OpenStack 最终用户,也可以是其他程序)向 API(nova-api)发送请求:“帮我创建一个虚机”。
2)API 对请求做一些必要处理后,向 Messaging(RabbitMQ)发送了一条消息:“让 Scheduler 创建一个虚机”。
3)Scheduler(nova-scheduler)从 Messaging 获取到 API 发给它的消息,然后执行调度算法,从若干计算节点中选出节点 A。
4)Scheduler 向 Messaging 发送了一条消息:“在计算节点 A 上创建这个虚机”。
5)计算节点 A 的 Compute(nova-compute)从 Messaging 中获取到 Scheduler 发给它的消息,然后在本节点的 Hypervisor 上启动虚机。
6)在虚机创建的过程中,Compute 如果需要查询或更新数据库信息,会通过 Messaging 向 Conductor(nova-conductor)发送消息,Conductor 负责数据库访问。
1. nova-api
nova-api 是整个 Nova 组件的门户,所有对 Nova 的请求都首先由 nova-api 处理。 nova-api 向外界暴露若干 HTTP REST API 接口。OpenStack CLI,Dashboard 和其他需要跟 Nova 交换的组件会使用这些 API。
在 keystone 中我们可以查询 nova-api 的 endponits。客户端就可以将请求发送到 endponits 指定的地址,向 nova-api 请求操作。
nova-api 对接收到的 HTTP API 请求会做如下处理:
1)检查客户端传人的参数是否合法有效
2)调用 Nova 其他子服务的处理客户端 HTTP 请求
3)格式化 Nova 其他子服务返回的结果并返回给客户端
只要是跟虚拟机生命周期相关的操作,nova-api 都可以响应。大部分操作都可以在 Dashboard 上找到。
2. nova-conductor
nova-compute 需要获取和更新数据库中实例的信息。但 nova-compute 并不会直接访问数据库,而是通过 nova-conductor 实现数据的访问:
1)实现更高的系统安全性
在 OpenStack 的早期版本中,nova-compute 可以直接访问数据库,但这样存在非常大的安全隐患。因为 nova-compute 这个服务是部署在计算节点上的,为了能够访问控制节点上的数据库,就必须在计算节点的 /etc/nova/nova.conf 中配置访问数据库的连接信息。如果任意一个计算节点被黑客入侵,都会导致部署在控制节点上的数据库面临极大风险。
为了解决这个问题,从 G 版本开始,Nova 引入了一个新服务 nova-conductor,将 nova-compute 访问数据库的全部操作都放到 nova-conductor 中,而且 nova-conductor 是部署在控制节点上的。这样就避免了 nova-compute 直接访问数据库,增加了系统的安全性。
2)实现更好的系统伸缩性
nova-compute 与 nova-conductor 是通过消息中间件交互的。这种松散的架构允许配置多个 nova-conductor 实例。在一个大规模的 OpenStack 部署环境里,管理员可以通过增加 nova-conductor 的数量来应对日益增长的计算节点对数据库的访问。
3. nova-scheduler
nova-scheduler 解决如何选择在哪个计算节点上启动实例的问题。
当创建实例时,用户会提出资源需求,例如 CPU、内存、磁盘各需要多少。OpenStack 将这些需求定义在 flavor 中,用户只需要指定用哪个 flavor 就可以了。nova-scheduler 会按照 flavor 去选择合适的计算节点。
OpenStack 的虚拟机调度策略主要是由 FilterScheduler 和 ChanceScheduler 实现的,其中FilterScheduler 作为默认的调度器实现了基于主机过滤(filtering)和权值计算(weighing)的调度算法,而 ChanceScheduler 则是基于随机算法来选择可用主机的简单调度器。
FilterScheduler调度过程分为两步:
1)通过过滤(filtering)选择满足条件的计算节点(运行 nova-compute)。
2)通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建实例。
详情请参考 《OpenStack Nova 总结(02)- 虚拟机调度算法》
4.nova-compute
nova-compute 在计算节点上运行,负责管理节点上的实例。OpenStack 对实例的操作,最后都是交给 nova-compute 来完成。nova-compute 与 Hypervisor 一起实现 OpenStack 对实例生命周期的管理。
由前面介绍的 Driver 框架可知,nova-compute 通过 Driver 架构支持多种 Hypervisor。nova-compute 为各种 Hypervisor 定义了统一的接口,Hypervisor 只需要实现这些接口,就可以 Driver 的形式即插即用到 OpenStack 系统中。
可以在 /nova/nova/virt/ 目录下查看到 OpenStack 源代码中已经自带了上面这几个 Hypervisor 的 Driver。
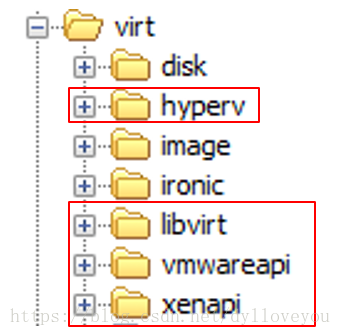
某个特定的计算节点上只会运行一种 Hypervisor,只需在该节点 nova-compute 的配置文件 /etc/nova/nova.conf 中配置所对应的 compute_driver 就可以了。
nova-compute 的功能可以分为两类:
- 定时向 OpenStack 报告计算节点的状态
- 实现实例生命周期的管理
1)定时向 OpenStack 报告计算节点的状态
每隔一段时间,nova-compute 就会报告当前计算节点的资源使用情况和 nova-compute 服务状态。可以查看日志 /var/log/nova/nova-compute.log:

这样OpenStack 就能得知每个计算节点的 vcpu、ram、disk 等信息。nova-scheduler 的很多 Filter 才能根据计算节点的资源使用情况进行过滤,选择符合 flavor 要求的计算节点。
2)实现实例生命周期管理
OpenStack 对实例最主要的操作都是通过 nova-compute 实现的,包括实例的启动、关闭、重启、暂停、恢复、删除、调整实例大小、迁移、创建快照等。
这里简单介绍一下实例创建操作。
当 nova-scheduler 选定了部署实例的计算节点后,会通过消息中间件 RabbitMQ 向选定的计算节点发出创建实例的命令。
该计算节点上运行的 nova-compute 收到消息后会执行实例创建操作。日志 /var/log/nova/nova-compute.log 会记录整个操作过程。
nova-compute 创建实例的过程可以分为 4 步:
a.为实例准备资源
b.创建实例的镜像文件
c.创建实例的 XML 定义文件
d.创建虚拟网络并启动实例
详情请参考《OpenStack虚拟机创建流程》
注:此总结基于 OpenStack Mitaka 版本,最新版可能稍有不同。
参考文档
http://www.cnblogs.com/CloudMan6/p/5410447.html
http://www.cnblogs.com/CloudMan6/p/5427981.html
http://www.cnblogs.com/CloudMan6/p/5436855.html
http://www.cnblogs.com/CloudMan6/p/5451276.html
https://blog.csdn.net/karamos/article/details/80124099
《2015 OpenStack技术大会-Nova的架构职责与设计思想-章宇》














 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









