








大数据文摘作品
编译:丁慧、文明、Katherine Hou、云舟
高斯过程可能不是当前机器学习最火的研究方向,但仍然在很多前沿的研究中被使用到——例如,最近在AlphaGo Zero中自动调整MCTS超参数就使用了它。在建模能力和进行不确定性估计方面,它们具有非常高的易用性。
然而,高斯过程很难掌握,尤其是当你习惯了深度学习中其他常见的模型之后。所以本文希望在具备相当少的ML知识背景下,对高斯过程提供一个直观的理论介绍,请学习者下载notebook并实现本文中提到的所有代码。
Jupyter notebook 版本:
https://gist.github.com/Bridgo/429594942ff51037ecc703905e40c562
什么是高斯过程,为什么使用它?
高斯过程(Gaussian process, GP)是一个强大的模型,可以用来表示函数的分布。机器学习中的大多数现代技术都倾向于通过参数化函数,然后对这些参数(例如线性回归中的权重)进行建模来避免这种情况。
然而,GP是直接对函数建模的非参模型。这种方法带来的一个非常重要的好处是:不仅可以拟合任何黑箱函数,还可以拟合我们的不确定性。量化不确定性是非常有价值的——例如,如果允许我们随意探索(需要更多的数据),我们就可以选择尽可能高效地探索最不确定的领域。这是贝叶斯优化背后的主要思想。
如果你给我几张猫和狗的照片作为学习资料,然后给我一张新的猫的照片让我分类——我应该给出一个置信度相当高的预测。但是如果你给我一张鸵鸟的照片,强迫我判断它是猫还是狗——我最好还是给出一个置信度非常低的预测。
——Yarin Gal
对于这个介绍,我们将考虑一个没有噪声的简单回归模型设置(但GP可以扩展到多维和噪声数据):
假设我们需要拟合某个隐函数f:R—> R
已知数据X = [x1,…,xN]T,Y = [y1,…,yN]T,其中yi = f(xi)
我们要预测一些新的未观测点x*的函数值
使用高斯拟合函数
GP背后的关键思想是可以使用无限维多元高斯分布拟合函数。换句话说,输入空间中的每个点与一个随机变量相关联,并将多元高斯分布用来拟合这些点的联合分布。
那么,这究竟意味着什么呢?让我们从一个更简单的情况开始:一个二维高斯。已知:

通常它是高度表示概率密度的3D钟形曲线。但是,假如不是表示整个分布,我们只需要从分布中抽样。然后我们将得到两个值,我们可以绘制点d并在它们之间画一条线。

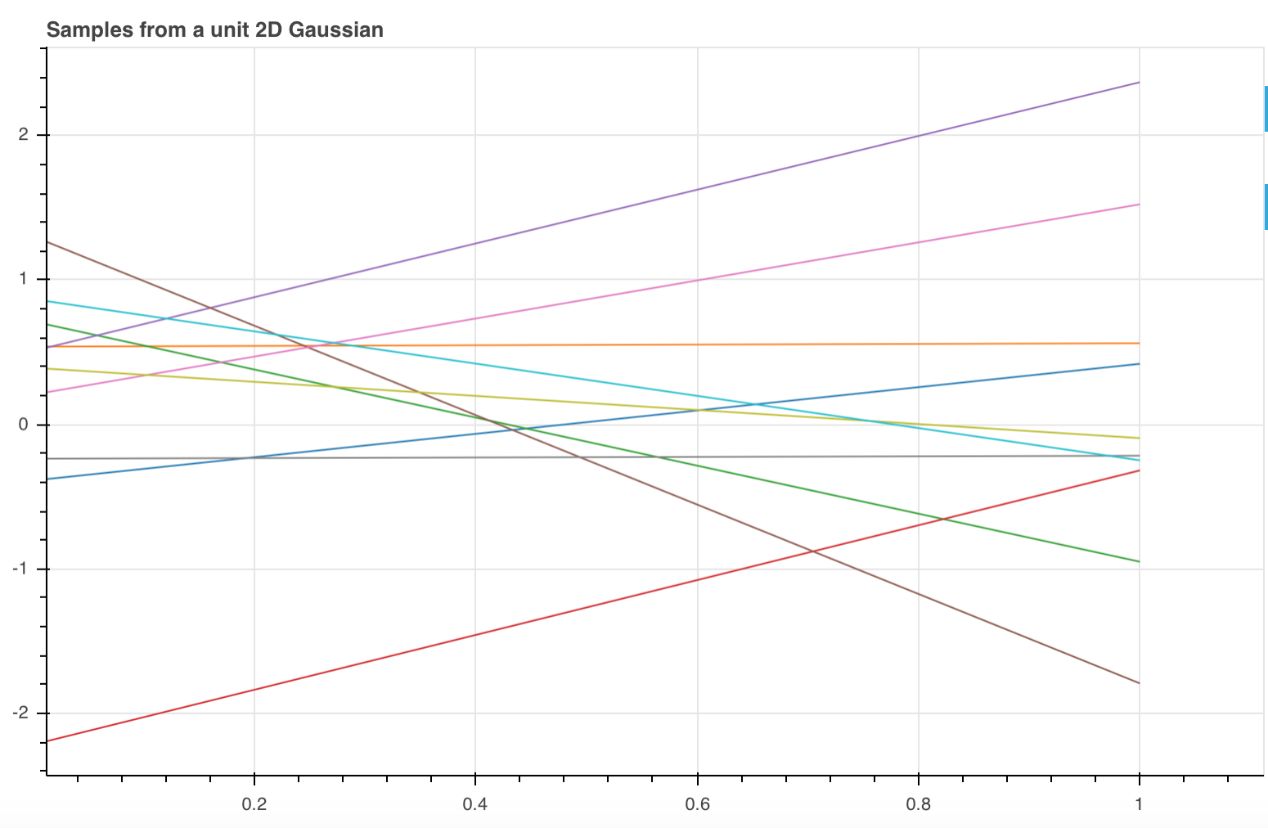
观察图中的这些直线,看起来像我们仅仅抽取了10个线性函数样本……如果我们现在使用20维的高斯函数,依次连接每个样本点,会发生什么样的变化呢?

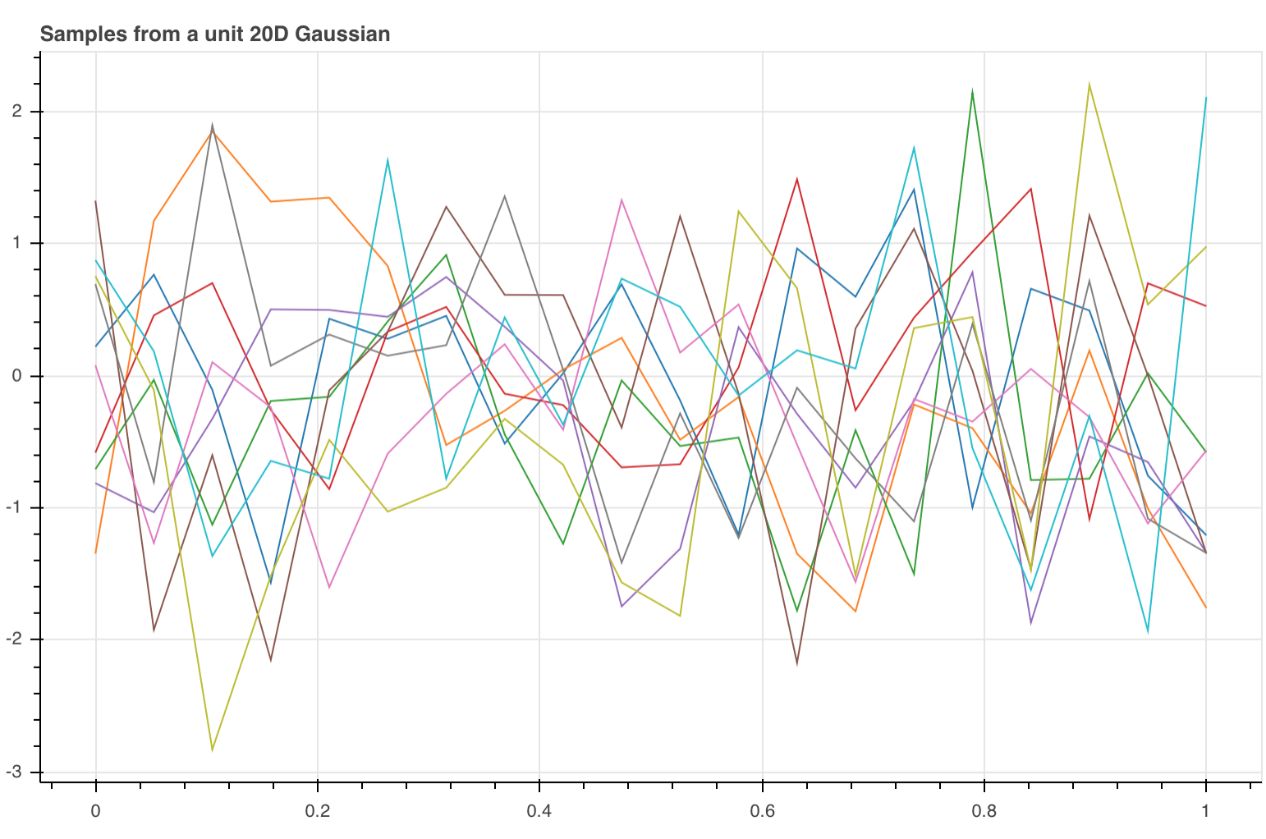
这些绝对看起来像多个函数,但相对于我们的目的,它们看起来噪声太大所以不可用。让我们进一步考虑可以从这些样本中得到什么,以及如何改变分布从而获得更好的样本……
多元高斯有两个参数,即均值和协方差矩阵。如果我们改变了均值的话,我们只会改变整体趋势(即如果均值是上升的整数,如np.arange(D),那么样本会呈现出整体正向线性趋势)&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









