






首先,我们来看一个例子。
你有一个朋友,他有一套750平方英尺的房子,他来问你能卖多少钱。
然后,你就找来了附近房子的最近买卖信息,然后把面积跟房价画了一条曲线出来。(注:例子与图来自Andrew NG的machine learning课程。)

如图,我们知道的只是上面一些点,横坐标是面积,纵坐标是房价。现在你要怎么预测朋友的房子卖多少钱呢?
开始,你觉得这些点像一条直线,于是就画了一条直线去进过尽量多的点,然后在750的地方画了一条竖线上去,得出房价为150K。
然后你又觉得这个拟合不是很好,你想到二次曲线的形状更符合点的分布,然后又有了蓝色的曲线,根据这条曲线,得出房价为200K。
可见准确的拟合数据的变化趋势是多么重要!
上述的问题就是一个回归问题,即根据已有的数据推测出一系列连续值的属性,从而能预测其他值的输出结果。
简单来说,回归就是求解一些数据服从的函数或者分布。
我们来看另外一个例子:
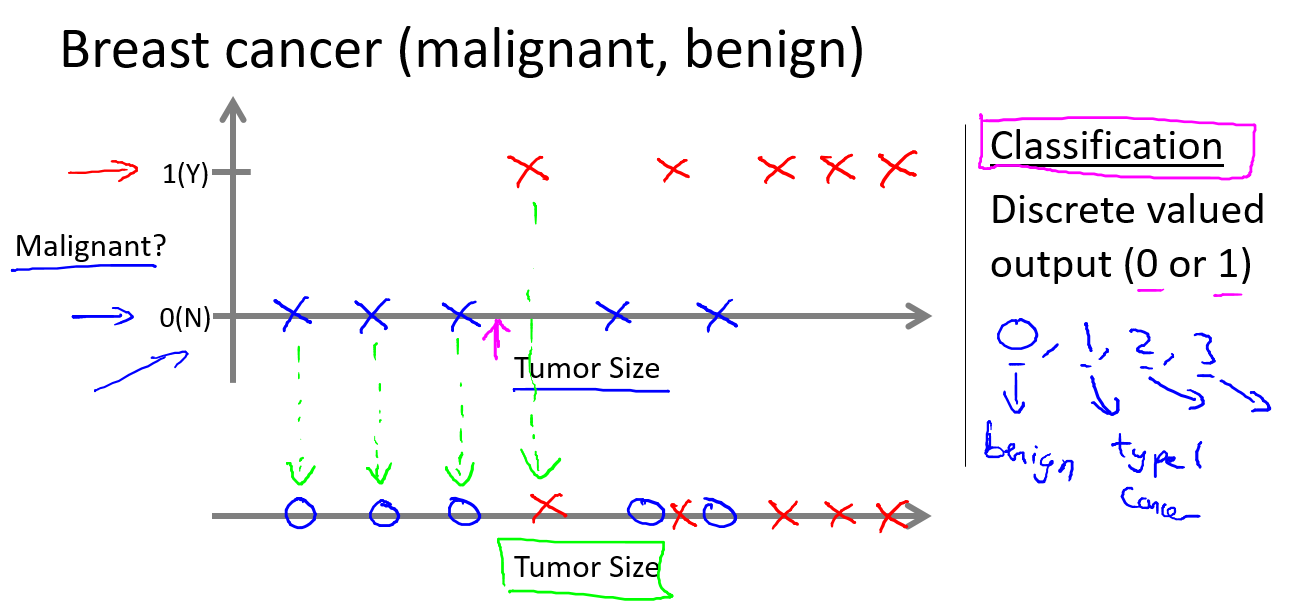
上图是肿瘤大小和是否为良性的关系,恶性肿瘤标记为1,良性标记为0.
我们发现这组数据不像之前的那样好找规律了。
于是,我们搜集了更多的信息,患者的年龄。
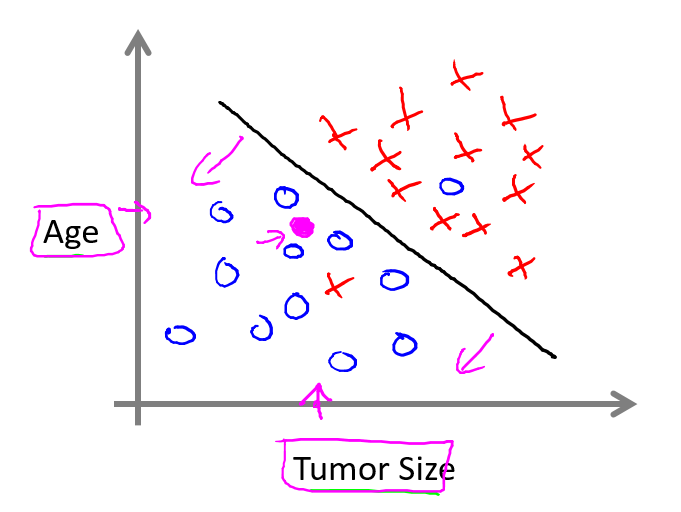
如图,横坐标是肿瘤大小,纵坐标是患者年龄,数据点中圆圈代表良性,×代表恶性。
这次,我们换一种做法,在这个数据空间里找一条直线,但不是过这些点,二是将这些点分在直线两侧。
然后有新的患者,我们将他的特征描到这个空间中,看他属于哪一边,这样就可以大致判断肿瘤的性质。
上面这个问题属于分类问题,即通过已知数据推测出离散的输出值。
这一部分我们通过两个例子解释了回归和分类的区别,这两种算法都是属于监督学习的范畴。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









