







原书第三版
Jiawei Han Micheline Kamber Jian Pei 著
第二章 认识数据
在进行数据挖掘之前,首先需要准备好数据,熟悉数据。
数据对象与属性类型
一个数据对象代表一个实体,又称样本、实例、数据点或对象。
属性是一个数据字段,表示数据对象的一个特征,又称维、特征和变量。
- 标称属性:一些符号或事物的名称。
- 例如:hair_color(黑色,金色,棕色,白色)
- 也可能是数值,例如用1表示头发黑色,2表示头发白色等,或者用户的User_ID为数值,但是这些都不具有数值属性,也就是说,数学运算是没有意义的。
二元属性:一种标称属性(又称布尔属性)
- 0或1
- 例如:男或女;有病或没病
- 对称的:两种状态具有同等价值,携带相同的权重
- 非对称的:结果不是同样重要。如HIV的检查结果,用1对最重要的结果编码(如HIV阳性)
序数属性:可能的值之间具有有意义的序。相继值之间的差未知。
- 例如:饮料容量:大、中、小。等级评定:优、良、中、差。
- 这些值具有有意义的先后次序,但是我们不能说“大”比“中”多多少。
以上三种属性都是定性的,即它们描述对象的特征,而不给出实际大小或数量
数值属性:定量的
- 区间标度属性属性
- 用相等的单位尺度度量。区间属性的值有序,但是不能用比率谈论这些值。
- 例如:不能说10℃比5℃暖两倍
- 比率标度属性
- 具有固有零点的数值属性。
- 区间标度属性属性
离散属性与连续属性
数据的基本统计描述
把握数据的全貌
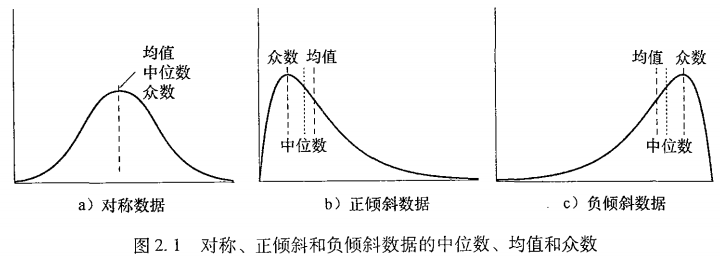
中心趋势度量:均值、中位数和众数
均值(mean)
均值
加权算术平均
- 均值对极端值(例如:离群点)很敏感
- 为了抵消影响,采用截尾均值(去掉头尾x%的数据)
中位数(median):有序数据值的中间值
- 若为个数为偶数,则取中间两个值中的任意值,如果为数值属性,一般取两者的均值。
- 若观测的数量很大,可以用差值计算近似值
- 众数(mode):集合中出现最频繁的值
- 对于适度倾斜(非对称)的单峰数值数据,有以下近似
- 对于适度倾斜(非对称)的单峰数值数据,有以下近似
- 中列数(midrange):数据集中最大和最小值的平均值。
度量数据散布:极差、四分位数、方差、标准差和四分位数极差
- 极差:最大值与最小值之差
分位数:取自数据分布的每隔一定间隔上的点,把数据划分成基本上大小相等的连贯集合
- 四分位数:3个数据点,把数据划分成4个相等的部分。
- 四分位数极差:IQR = Q3 – Q1(第3个和第1个四分位数之差)
- IQR可用于挑选离群点,挑选落在第3个四分位数之上或第1个四分位数之下至少1.5*IQR处的值。
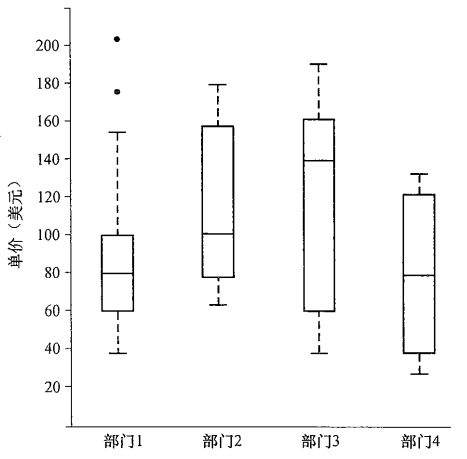
盒图:体现了五数概括
- 分布的五数概括:最小值、四分位数Q1、中位数、四分位数Q3和最大值(按次序写出,其中中位数也是四分位数Q2
- 盒图的端点一般在四分位数上,即盒的长度为IQR
- 中位数用盒内的线表示
- 盒外的两条线(称作胡须)延伸到最小和最大观测值(仅当最高和最低观测值超过四分位数不到1.5*IQR时,胡须扩展到它们,否则胡须出现在四分位数的1.5*IQR之内的最极端的观测值处终止,剩下情况单独绘出)
- 方差和标准差:指出数据分布的散步程度
方差
- 标准差是方差的平方根
- 标准差度量关于均值的发散,仅当选择均值作为中心度量时使用。
数据的基本统计描述的图形显示
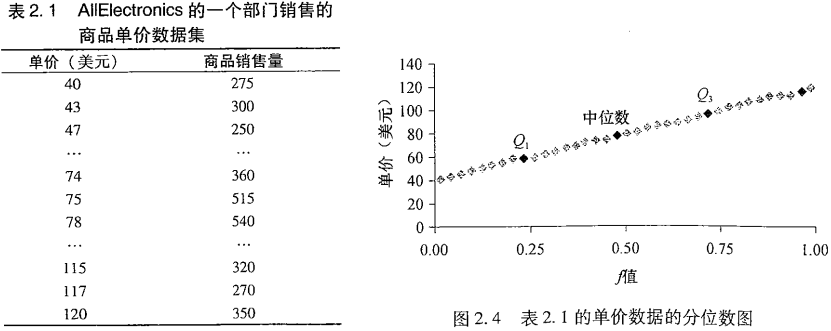
分位数图
- X按递增序排序,每个观测值xi与一个百分数fi配对。
- 意思是大约fi * 100%的数据小于值xi
- X按递增序排序,每个观测值xi与一个百分数fi配对。
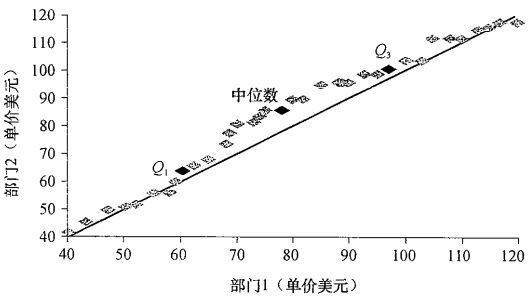
分位数-分位数图(又称q-q图)
- 对着另一个对应的分位数,绘制一个单变量分布的分位数。
- 观察从一个分布到另一个分布是否有漂移
例如Q1这个点表示,在部门1中,25%的价格数据低于60美元,在部门2中,25%的价格数据低于64美元。
直方图
- 对于X的每个已知值,条的高度表示该X值出现的概率(即计数)
- 如果X是数值的,X的值域被划分成不想交的连续子域(称作桶或者箱)。
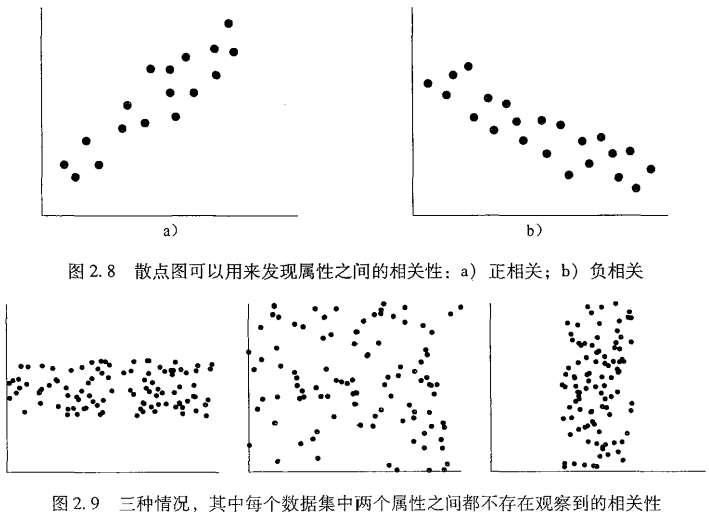
散点图
- 不同于以上三者是衡量单变量的,散点图确定两个数值变量之间是否存在联系、模式或趋势
- 不同于以上三者是衡量单变量的,散点图确定两个数值变量之间是否存在联系、模式或趋势

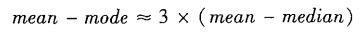
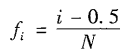
数据可视化
通过图形清晰有效地表达数据
基于像素的可视化技术
值越小,颜色越淡
对于宽窗口,以线性方法填充的效果不够好。第一个元素与前一行的最后一个元素相隔太远,但是在全局序下他们是彼此贴近的。这种情况下,可以采用空间填充曲线。
另外,窗口不必是矩形的。圆弓分割技术使用圆弓形窗口。
几何投影可视化技术
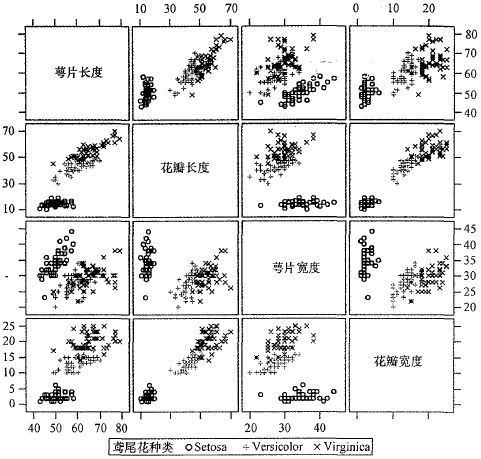
理解多维空间的数据分布散点图:使用笛卡尔坐标显示多维数据点。
- 对于维数超过4的数据集,散点图一般不太有效。采用散点图矩阵。
散点图矩阵是二维散点图的n*n网络
随着维数的继续增加,另一种技术称为平行坐标。绘制n个等距离,相互平行的轴,每维一个。缺点是当数据集大时,可读性较差,视觉上重叠较多。
基于图符的可视化技术
切尔诺夫脸:用眼、耳、口、鼻等的形状、大小、位置和方向表示维的值。
- 缺点:在表示多重联系的能力方面存在局限性。而且未显示具体的数据值。数据在面部位置的映射需谨慎选择。
- 眼睛的大小和眉毛的歪斜是重要的。
人物线条画:把多维数据映射到5段人物线条画上。每个画都有四肢和一个躯体。两个维被映射到显示轴,其余维被映射到四肢角度和(或)长度。
层次可视化技术:把所有维划分成子空间,这些子空间按层次可视化。
- 世界中的世界(n-Vision)
- 树图
可视化复杂对象和关系
- 标签云


度量数据的相似性和相异性
相似性和相异性都称为邻近性
- 数据矩阵(对象-属性结构):采用关系表的形式或n*p(n个对象,p个属性)矩阵
相异性矩阵(对象-对象结构):n个对象两两之间的邻近度
d(i,j)是对象i和对象j之间的相异性,数值越大差异越大(最下为0,无差异)。d(i,j) = d(j,i),矩阵是对称的。
对于标称数据,相似性sim(i,j) = 1 - d(i,j)标称属性的邻近性度量
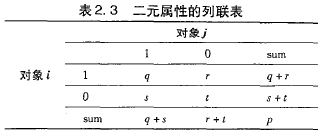
二元属性的邻近性度量
对于标称属性可以进行二元属性编码,为M种状态的每个状态创建一个二元属性(即该状态的二元属性值为1,其余为0)
q:对象i和j都取1的属性数
r:对象i取1,对象j取0的属性数
s:对象i取0,对象j取1的属性数
t:对象i和j都取0的属性数对称二元属性
非对称的二元属性
负匹配数t被认为是不重要的。
相似性被称为Jaccard系数
数值属性的相异性
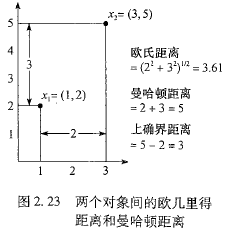
在某些情况下,计算距离之前数据应该规范化,试图给所有属性相同的权重欧几里得距离
曼哈顿距离
闵可夫斯基距离(Lp范数)
Lp范数中的p,在上面公式中写为h,p=1即为曼哈顿距离,p=2表示欧几里得距离。上确界距离(切比雪夫距离)
是h趋于无穷时,闵可夫斯基距离的推广。
- 序数属性的邻近性度量
- 混合类型属性的相异性
可能包含上面列举了所有属性类型
余弦相似性
有时会出现稀疏的数值数据(0很多),采取传统的距离度量,可能会因为过多的0项导致彼此不相似,例如词频统计,可能很多词在两句话中都没有出现,需要关注的是它们共有的词,以及这些词出现的频率。
余弦值越接近1,意味着夹角越小,也就是匹配度越大。当属性是二值属性时,简单变化如下:
这个函数被称为Tanimoto系数。
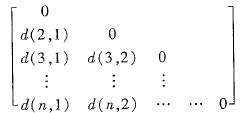

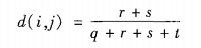
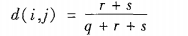
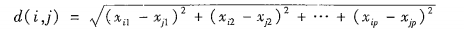
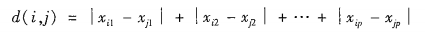
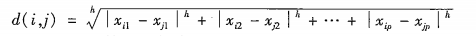
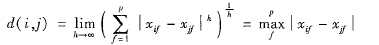


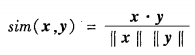
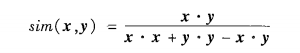
自己加油加油 笨鸟后飞也要飞呀飞















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









