







原书第三版
Jiawei Han Micheline Kamber Jian Pei 著
第七章 高级模式挖掘
模式挖掘:一个路线图
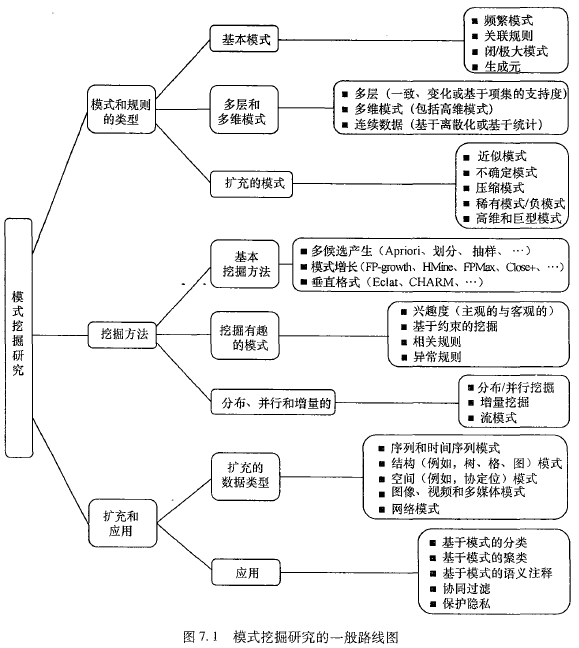
- 多层关联规则:涉及不同的抽象层
例如:buy(电脑)=》buy(打印机),buy(手提电脑)=》buy(彩色打印机) - 多维关联规则:涉及两个或多个维
例如:age(20~29岁),并且income(五万到六万)=》buy(iPad)
多层、多维空间中的模式挖掘
挖掘多层关联规则
一般而言,采用自顶向下策略,在每个概念层累积计数,计算频繁项集,直到不能再找到频繁项集。对于每一层,可以使用发现频繁项集的任何算法。
对于所有层使用一致的最小支持度(一致支持度)
搜索被简化,但如果阈值设置太高,则可能错失在较低抽象层中出现的有意义的关联。如果阈值设置太低,则可能会产生出现在较高抽象层的无趣的关联。在较低层使用递减的最小支持度(递减支持度)
抽象层越低,对应的阈值越小。使用基于项或基于分组的最小支持度(基于分组的支持度)
建立用户指定的基于项或基于分组的最小支持度阈值。
挖掘多层关联的一个严重副作用是,由于项之间的“祖先”关系,可能产生冗余规则。
例如:buy(手提电脑)=》buy(HP打印机),buy(戴尔手提电脑)=》buy(HP打印机)
后一个规则可能是无用的,如果置信度或者支持度显示它不提供任何附加信息。
挖掘多维关联规则
把每个数据库属性或数据仓库的维看做一个谓词,则可以挖掘包含多个谓词的关联规则。
- 单维或维内关联规则
buy(数码相机)=》buy(HP打印机),因为包含单个谓词的多次出现。 - 多维或维间关联规则
age(20~29岁),并且occupation(学生)=》buy(手提电脑),因为包含多个谓词且均只出现一次。 - 混合维关联规则
age(20~29岁),并且buy(手提电脑)=》buy(HP打印机),因为包含某些谓词的多次出现。
根据量化属性的处理,挖掘多维关联规则的技术可以分为两种基本方法:
- 使用量化属性的静态离散化挖掘多维关联规则
如对income属性,用区间值进行划分。这里离散化是静态的和预先确定的。离散化的数值属性具有区间标号,可以像标称属性一样处理。 - (动态)量化关联规则
根据数据分布将量化属性离散化或聚类到“箱”。该策略将数值属性的值处理成数量。
在多维关联规则挖掘中,不是搜索频繁项集,而是搜索频繁谓词集。例如{age, occupation, buy}是一个3-谓词集
挖掘量化关联规则
基于数据立方体挖掘
数据立方体在多维空间存储聚集信息(例如:计数)。使用n维方体的单元存放对应的n-谓词集的支持度计数。
0-D(顶点)方体包含与任务相关数据中事务的总数。基于聚类的方法
一般假定是,有趣的频繁模式或关联规则通常在量化属性相对稠密的簇中发现自顶向下的方法
对每个量化维,可以使用一种标准的聚类算法,发现该维上满足最小支持度阈值的簇。然后考虑该簇与另一维的一个簇或标称属性值组合生成的二维空间,看这一组合是否满足最小支持度阈值。如果满足,则继续在该二维区域搜索簇,并进一步考察更高维空间。自底向上的方法
发现高维聚类很困难,因此这种方法不太现实

挖掘稀有模式和负模式
在珠宝销售数据中,购买钻石表示稀有的,然而涉及钻石表销售的事务可能是令人感兴趣的。在超市数据中,一起购买经典可乐和无糖可乐可能是一个负(相关)模式。
- 非频繁(稀有)模式
支持度低于用户指定的最小支持度阈值的模式。在实际中,可以指定稀有模式的其他条件。比如,至少包括一件价格超过500美元的商品。 负模式
如果项集X和Y都是频繁的,但很少一起出现( sup(X∪Y)<sup(X)×sup(Y) ),则项集X和Y是负相关的,并且模式 X∪Y 是负相关模式,如果 sup(X∪Y)<<sup(X)×sup(Y) ,则项集X和Y是强负相关的,并且模式 X∪Y 是强负相关模式
此条定义不是零不变的如果X和Y是强负相关的
sup(X∪Y¯)×sup(X¯∪Y)>>sup(X∪Y)×sup(X¯∪Y¯)
此条定义不是零不变的假设项集X和Y都是频繁的,如果( (P(X|Y)+P(Y|X))/2<ε ),其中 ε 是负模式阈值,则 X∪Y 是负相关模式。
此条定义是零不变的
基于约束的频繁模式挖掘
让用户说明他们的这种直观或期望,作为限制搜索空间的约束条件。
- 知识类型约束:指定待挖掘的知识类型,如关联、相关、分类或聚类。
- 数据约束:指定任务相关的数据集。
- 维/层约束:指定挖掘中所使用的数据维(或属性)、抽象层,或概念分层结构的层次。
- 兴趣度约束:指定规则兴趣度的统计度量阈值,如支持度、置信度和相关性。
- 规则约束:指定要挖掘的规则形式或条件。
下面主要讨论最后一点,基于规则约束的挖掘。
关联规则的元规则制导挖掘

基于约束的模式生产:模式空间剪枝和数据空间剪枝
挖掘关联规则的约束举例
销售数据库,包含以下内容:
- item(item_ID, item_name, description, category, price)
- sales(transaction_ID, day, month, year, store_ID, city)
- trans_item(item_ID, transaction_ID)
假设查询为“对于芝加哥2010年的销售,何种廉价商品(低于10美元)促进了何种昂贵商品(高于50美元)的销售的模式或规则”
这个查询包括4个约束:
- sum(I.price)<10,I表示廉价商品的item_ID
- min(J.price)>50,J表示昂贵商品的item_ID
- T.city = Chicago
- T.year = 2010,T表示transaction_ID
用模式剪枝约束对模式空间剪枝
检查候选模式,确定模式是否可以被剪掉。
- 反单调的
考虑规则约束sum(I.price) < 100,如果一个候选项集中的商品价格和不小于100美元,则该项集可以从搜索空间中剪枝,因为再向该商品集中添加商品会使它更贵。
换言之,如果一个项集不满足该规则约束,则它的任何超集也不可能满足该约束。
如果一个规则具有这种性质,则称它是反单调的。
注意,像avg(I.price) <10这样的约束不是反单调的。
- 单调的
例如约束sum(I.price)>100,如果一个项集满足该约束,则它的超集也满足。这样的规则约束是单调的。
- 简洁的约束
可以枚举并且仅枚举确保满足该约束的所有集合。比如min(J.price)>50是简洁的。
- 可转变的约束
例如avg(I.price) <10既不是单调也不是反单调的,但是如果事务中的项按照单价递增的顺序添加到项集中,则该约束变成反单调的。
- 不可转变的约束
用数据剪枝约束对数据空间剪枝
检查数据集,确定特定的数据片段在剩下的挖掘过程中是否对其后的可满足模式的产生有贡献。
- 数据简洁性
如果一个挖掘查询要求被挖掘的模式必须包含数码相机,则可以在挖掘过程开始前就剪掉所有不包含数码相机的事务。 - 数据反单调
在挖掘过程中,如果一个数据项不满足数据反单调约束,则可以剪掉它。
例如约束为sum(I.price)>100,假设当前频繁项集S不满足约束,比如S中商品价格和为50美元,如果Ti中剩下的频繁项,{i2.price=5, i5.price=10}则Ti不能使S满足约束,可以剪掉。
注意,仅限于基于模式增长的挖掘算法。如果使用Apriori算法,则数据反单调性不能用于对数据空间剪枝,一个数据项不能对一个给定模式的超模式形成贡献,但仍然可能对其他活跃模式的超模式有贡献。
挖掘高维数据和巨型模式
典型方法的搜索空间随维数呈指数增长。为了挖掘高维数据,一个方向是进一步利用垂直数据格式,又称为行枚举。从少量行大量维的数据变为大量行少量维的数据集。第二个方向是模式融合,用于挖掘巨型模式(长度非常长),下面具体介绍。
通过模式融合挖掘巨型模式
Apriori算法不可避免会产生大量中型模式,使得它不可能到达巨型模式。
即使像FP-growth这样的深度优先方法也很容易在达到巨型模式前被数量巨大的子树困扰。
模式融合:融合少量较短的频繁模式形成巨型模式候选。得到巨型频繁模式完全集的一个很好的近似解。
首先以有限的宽度遍历树。
每个模式的增长不是添加一个项,而是与池中多个模式凝聚。

由于模式融合是巨型模式的近似解,所以引进一个质量评估模型,评估算法返回的模型。
核模式定义:

还是不太理解d的意义
较长或巨型模式有更多的核模式,因此巨型模式更鲁棒。
模式融合包括两个阶段:
- 池初始化
一个短长度(长度不超过3)的频繁模式的完全集 - 迭代的模式融合
取用户指定的参数K(要挖掘模式的最大个数)为输入。每次迭代中,从当前池取K个种子,找出直径为τ的球内的所有模式。每个“球”中的所有模式融合在一起,形成一个超模式集。这些超模式形成新的池。
挖掘压缩或近似模式
为了压缩挖掘产生的巨大的频繁模式集,同时维持高质量的模式,可以挖掘频繁模式的压缩集合或近似集合。
通过模式聚类挖掘压缩模式
根据模式的相似性和支持度对模式进行分组。使用一种称为δ-簇的紧密性度量对频繁模式聚类。代表模式从每个簇中选取,代表模式应该能够表达该簇中的所有其他模式,从而提供频繁模式集的一个压缩版本。
闭模式是频繁模式的无损压缩,极大模式是有损压缩。

利用距离度量的问题是1、聚类质量不能保证;2、也许不能为每个簇找到一个代表模式,为了克服,出现了δ-簇的概念。δ(0≤δ≤1)度量簇的紧密性。

此时,只需要计算每个模式P与簇代表Pr之间的距离。

给定一个事务数据库,最小支持度min_sup和聚类质量度量δ,模式压缩问题是找到一个代表模式的集合R,使得对于每个频繁模式P(关于min_sup)存在一个代表模式Pr属于R,它覆盖了P,并且R最小化。
提取感知冗余的top-k模式
在许多情况下,频繁模式不是相互独立的。
感知冗余的top-k模式:不仅具有高显著性,而且具有低冗余的k个代表模式的集合。
- 显著性、冗余性定义
显著性度量可以使客观的或主观的:客观度量包括支持度、置信度、相关度和tf-idf;主观度量基于用户对数据的信赖。
满足0≤R(p,q)≤min(S(p),S(q))
于是,发现感知冗余的top-k模式的问题转换成发现最大化边缘显著性的k-模式集问题。

下图直观显示了三种k模式的区别(显著性用灰度表示),目的是找出3个最能代表集合的模式

模式搜索与应用
频繁模式的语义注解
类似于字典,为频繁模式提供有结构的注解。
一般而言,一个模式的隐藏含义可以从具有类似意义的模式,与它共同出现的数据对象和该模式出现的事务中推断。
关于模式p的语境建模:

下面,如何为每个语境指示符设定权重?互信息是多个可能的权重函数之一。
(互信息的定义不再具体列出)
使用语境模型,可以用如下步骤完成模式注解:

模式挖掘的应用
在许多数据密集型应用中,模式挖掘作为预处理,广泛地用于噪声过虑和数据清理。
模式挖掘常常有助于发现隐藏在数据中的固有结构和簇。
研究发现可以使用频繁模式作为构件,建立高质量的分类模型,成为基于模式的分类。
频繁模式也可以用于高维空间中子空间的有效聚类。
对于时间空间数据、时间序列数据、图像数据、视频数据和多媒体数据的分析,模式分析是有用的。
模式挖掘还用于序列或结构数据分析,如树、图、子序列和网络分析。
频繁模式和有判别力的模式可以用做基本的索引结构,帮助搜索大型复杂的、结构化的数据集和网络。
频繁模式还可以用于推荐系统。
加油!















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









