







很多因页面代码的改变,网上scrapy爬虫的实例已经不能运行,自己便做了一个来试试。
scrapy的学习参照http://scrapy-chs.readthedocs.io/zh_CN/latest/
运行环境:
python 3.6.1
scrapy 1.4.0
所需要的包名:
openpyxl #用于excel操作
simplejson #用于json操作
流程分析
例子要抓取这个网页 http://www.imooc.com/course/list?page=1要抓取的内容是全部的课程标题,课程url,课程标题图片,课程图片路径,课程描述,学习人数
并且把数据存储为json格式和excel格式,并附上源代码。
通过浏览器的调试工具我们可以看到它们的结构
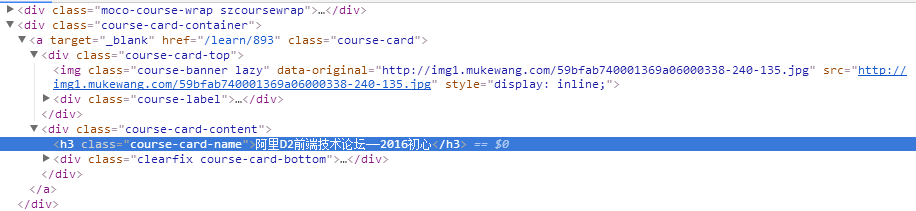
分析得出,要抓取的内容都在<div class="course-card-container"><a target=..>...</a></div>里面,所以抓取的xpath路径写为:
'//div[@class="course-card-container"]/a[@target="_blank"]'
已下载源代码的话,直接放在C盘下,打开dos输入
C:\>cd scrapytest就可以得到C:\scrapytest下的jsonData.json和excelData.xlsx,pic图片文件夹
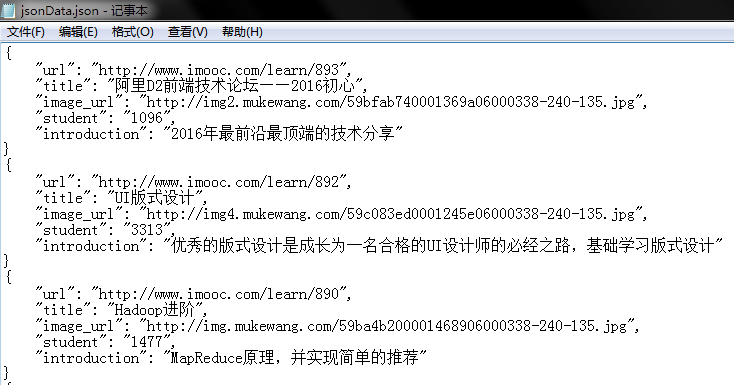
jsonData.json预览
excelData.xlsx预览

pic文件夹预览
代码有注解,如果下载附件后,程序运行有问题留言,有看到后回复的 。源代码下载:http://download.csdn.net/download/ekendy/9993448
。源代码下载:http://download.csdn.net/download/ekendy/9993448














 1503
1503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









