







来自UC Berkeley & Facebook AI Research在CVPR2015上发表的文章。
这篇文章的亮点在于所建的“人体”识别数据库是一个真正意义上的unconstrained setting,并且通过结合肢体的poselet,能够很好地识别人物的身份,而不是仅限于对人脸的识别。
1. PIPA unconstrained数据库的建立
motivation如下图,从我们人眼来说,可以通过姿态、肤色等信息轻易地识别一些非正脸的图片,而对于目前的人脸识别技术来说显然做的还不够。其原因之一是并没有这样的公开数据库,因此——

新建数据库:People In Photo Albums(PIPA) dataset
数据量:37107 photos/ 63188 instances/ 2356 ids(分清楚3个概念:photo表示一张图片,instance表示图片中的一个人物,id表示身份)
建库过程:
1. 筛选Album: Flickr下载上千album,然后去除掉描述风景等非人的照片集
2. 为人物贴标签: 将每个相册中出现两次以上的人物用不同颜色的bounding box将头部区域圈出(不同颜色表示不同id)。
注意是头的位置不是脸的位置,有一半的人都是没有脸的。如果头部被遮挡,则框出头部应该出现的位置(这些位置有可能在照片尺寸以外)。对于crowded scene, 圈出少于10人。
3. 不同相册同一人物的融合:只针对同一个用户上传到flickr中的不同相册
4. 样本数量统一:将少于10张照片的人物去除,将多于99张图片的人物保留99张图片在数据集中(这是为了防止少数人过多图片会对数据集造成bias),其他的移到”leftover”中(leftover包含了11437 instances/ 54 ids)
5. 数据集组建:随机分成3组:训练集,验证集,测试集,大小比例约为50%:25%:25%(No. of instances)。同一个用户上传的所有照片只存在上述某一组中,保证3组set的ids/ instances/ photos都相互不相交。
2. 姿态不变的人物识别
识别过程:Pose Invariant Person Recognition(PIPER)
识别整合了以下3部分:
1.基于人体整体的一个分类器(global classifier),由CNN训练(网络结构为AlexNet, 将其fine-fune成实现identity recognition的任务)
2. 基于107个poselet的分类器(poselet classifier),由CNN训练,同上
3. 最终训练一个二分类的SVM分类器,即对于某个特定的instance,是否属于某个特定的id(由DeepFace 256D feature训练而成)
因此PIPER是3个网络的结合,AlexNet-based global classifier+107 AlexNet-based poselet classifiers+DeepFace-based SVM.
下面详细介绍分类器的训练过程。
2.1 计算part activation
对于每个instance,从其头部的bounding box中(ground truth)通过偏移和尺度变换估计其他部件所在的位置(ground truth bounds),然后用poselets[2]对图片进行检测得到各个部件的位置和激活程度(score),如图4就是poselet的检测。要注意的是,并不是每个instance的每个poselet都能被激活,后面会提到未激活怎么办。然后通过二分图(bipartite graph)将ground truth bounds 和poselets的预测做一个匹配,使得和某个ground truth 区域具有更多重叠区域和更高分数的poselet具有原来ground truth 区域的label。最终输出一系列标明身份的部件激活程度(poselet activations)。然后我们对每个poselet提取patch用来训练part-based classifiers.

2.2 训练部件分类器(part-based classifier)Pi(y|X)
对于每个instance的full body area,使用其在CNN网络FC7层的输出特征X训练一个多类SVM来预测identity,将此结果表示为P0(y|X).
对于部件i的patch,我们已知它的身份y,使用其FC7层的输出特征X,训练多类SVM分类器来预测其身份(也就是说对每个部件训练一个SVM分类器),记为^Pi(y|X).
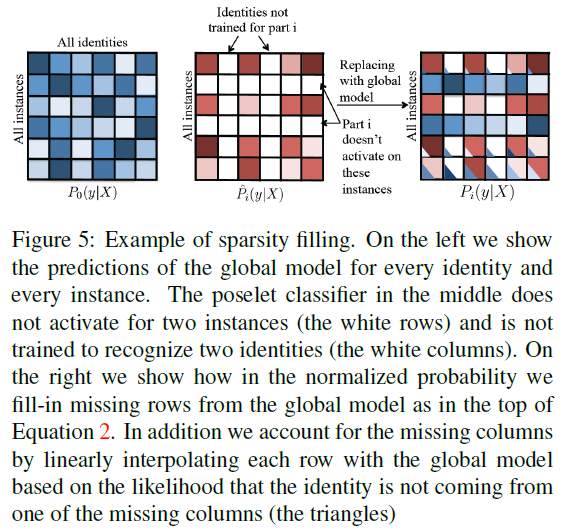
注意^Pi是稀疏的:每个poselet只有在instance处于特定的姿态时才进行激活,比如有些poselet的激活概率是50%,有些只有5%。另外,并不是所有的id都有所有poselet的instance的,因此训练part i的SVM分类器的数据也只是所有数据的一个子集Fi,那么^Pi(y|X)只有当y∈Fi时有值,其他情况为0。这种稀疏特性(sparsity)与人物的姿态有关而几乎与身份无关,因此我们试图消除这种特性。
sparse filling的方法处理sparsity:首先计算图片的每个poselet的激活程度(得分程度),如果没有激活(得分很低),则使用full body classifier来代替。计算公式如下:
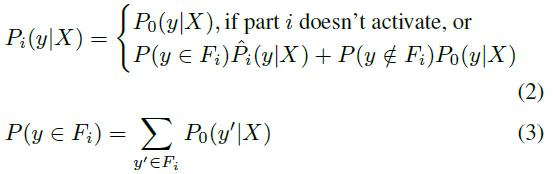
不知道我讲清楚没==、给个图大家消化消化。(我保证你们看完这个图就更不清楚了。。)
SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。目前,构造SVM多类分类器的方法主要有两类:一类是直接法,直接在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类。这种方法看似简单,但其计算复杂度比较高,实现起来比较困难,只适合用于小型问题中;另一类是间接法,主要是通过组合多个二分类器来实现多分类器的构造,常见的方法有one-against-one和one-against-all两种。
a.一对多法(one-versus-rest,简称1-v-r SVMs)。训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
b.一对一法(one-versus-one,简称1-v-1 SVMs)。其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。Libsvm中的多类分类就是根据这个方法实现的。
2.3 计算部件权重wi
在通过部件分类器以后我们可以得到其预测的结果,当然啦不同的部件所能表示的信息重要程度不同,所以使用验证集来计算部件的权重。首先将验证集等分成两份。在其中一份上训练part-based SVMs然后在另一份上计算所有instance的
Pi(y|X)
,然后反过来做一次。令
Pji(y|X)
表示part i的分类器在给定特征X时预测instance j的身份为y的概率。这是一个二值的分类问题,instance j身份为y的概率为1或-1.如果我们共有K个部件,则instance j的特征向量为K+1维:
[Pj0(y|X),Pj1(y|X),...,Pjk(y|X)]
通过训练一个线性SVM来预测身份,wi即为SVM的权重。
最终的身份预测是对上述概率的线性加权,然后取最大的s(X,y)中的y作为最终的身份:
s(X,y)=∑iωiPi(y|X)
,
ωi
为对part i的权重,
Pi(y|X)
为part i预测y|X下的归一化概率。
3. Experiments
实验主要分为3个部分:person recognition, one-shot person identification, unsupervised person retrival.
所有实验中我们使用PIPA数据集的training set作为训练global model和poselet的deep networks的数据,另外使用验证集来计算部件权重w。并在测试集上进行测试。
3.1 person recognition
将测试集分为两部分,第一部分训练分类的SVM,然后在第二部分上计算Pi(y|X),然后反过来做一次。接着结合验证集训练得到的w,得到最终的预测结果max[s(X,y)]下的y。
一些在deepface中误分类而PIPER正确分类的测试样例如图6所示,

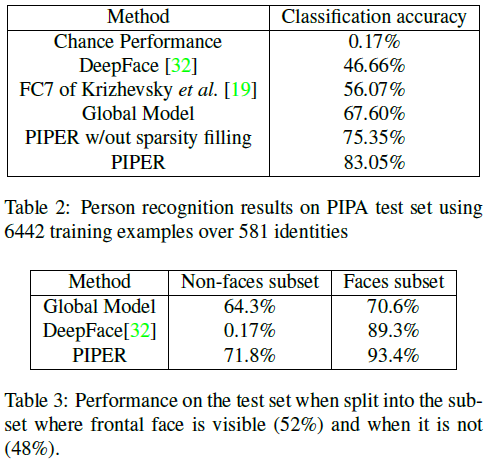
总的识别精度如表2、3所示。第一个baseline是DeepFace[32],它虽然很精确,但是是一个正面人脸的识别器,在我们48%没有正面人脸的数据下不能使用,因此我们使用chance performance。第二个baseline是AlexNet[19],我们使用其在ImageNet上pretrained model的FC7层特征训练的SVM来做分类。Global Model就是AlexNet在我们的training set上fine tune以后的结果,也是我们的full body recognizer。我们也测试了我们的model在经过sparse filling和未经过sparse filling两种情况下的实验结果,7%的performance gap说明sparsity filling是非常有效的。
3.2 One-shot learning
感觉没啥好讲的,略过
3.3 Unsupervised identity retrival
身份检索的意思是:给定一个instance,我们计算在其K个最近邻具有相同id的instance的可能性。
我们首先在验证集的一个split上训练SVMs用于预测验证集的366个id。然后将这些SVMs用于测试集,获得每个part 366D的feature vector, 然后通过验证集上训练的w和公式(1)得到最终的一个366D feature vector。对于测试集上的每个instance,通过欧式距离计算K最近邻,然后我们视检索为成功当且仅当K最近邻中有至少一个和query具有相同身份。结果显示64%的NN是和query相同身份的,而fine tuned AlexNet在这些query下的测试效果仅为50%.

论文到这里就结束了,我觉得搞这么多分类器来做得分叠加是一个很简单暴力的想法。我们能够想到该方法效果肯定比deep face好,说白了就是寻找有区分性的特征(poselet),然后组合分类器。但是该方法需要每个poselet训练一个分类器(可用fine-tune),开销比较大。














 8018
8018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









