









模型读取
读取bvlc_reference_caffenet 的模型结构以及训练好的参数,注意此处的模型结构为deploy,而非train时候的。
caffe.set_mode_cpu();%设置CPU模式
model = '../../models/bvlc_reference_caffenet/deploy.prototxt';%模型
weights = '../../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel';%参数
net=caffe.Net(model,'test');%测试
net.copy_from(weights); %得到训练好的权重参数
net %显示net的结构 运行我们就可以看到模型的结构了:

这里额外提一下,net 通过”.” 能显示的东西,除了上面输出的这些properties外,还有Net.m中定义的函数:
function self = Net(varargin)
function layer = layers(self, layer_name)
function blob = blobs(self, blob_name)
function blob = params(self, layer_name, blob_index)
function forward_prefilled(self)
function backward_prefilled(self)
function res = forward(self, input_data)
function res = backward(self, output_diff)
function copy_from(self, weights_file)
function reshape(self)
function save(self, weights_file) 输入数据整理
下面这张图片藏在E:\CaffeDev\caffe-master\examples\images\cat.jpg
①先把均值读进来
d = load('../+caffe/imagenet/ilsvrc_2012_mean.mat');
mean_data = d.mean_data;②读取图片
im = imread('../../examples/images/cat.jpg');%读取图片
IMAGE_DIM = 256;%图像将要resize的大小,建议resize为图像最小的那个维度
CROPPED_DIM = 227;%待会需要把一张图片crops成十块,最终softmax求出每一块可能的标签 设置在输入网络之前需要将图片resize的大小,一般我们会取图片长宽最小的那个,其次需要设置的是输入网络的图片的大小,注意与deploy.prototxt的输入一致,比如
name: "CaffeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } }
} 这里关注一下input_param,代表一次输入十张图片,每张图片三通道,每张图片大小是227*227。此外注意一下,在opencv中,彩色图像按照BGR存储,而matlab中读取的顺序一般是RGB。所以对这只猫需要进行如下处理:
im_data = im(:, :, [3, 2, 1]); %matlab按照RGB读取图片,opencv是BGR,所以需要转换顺序为opencv处理格式
im_data = permute(im_data, [2, 1, 3]); % 原始图像m*n*channels,现在permute为n*m*channels大小
im_data = single(im_data); % 强制转换数据为single类型
im_data = imresize(im_data, [IMAGE_DIM IMAGE_DIM], 'bilinear'); % 线性插值resize图像注意一下你在训练的train.prototxt中的预处理部分
transform_param {
mirror: true
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
} 这里最后一行代表进行了零均值处理,关于这一部分参数,可以看我前面用classification,exe手写识别时候提到的那个博客,介绍了如何看这一部分进行了怎样的预处理。
先零均值化一下,然后按照deploy和train的prototxt,将这只猫crop(分成)十块,采用的是classification.demo的分割方法,分别取猫的上下左右四个角以及中心的大小为deploy中提到的227*227大小。这是五个,然后再对图片翻转180°;合起来就是代表这只猫的十张图片:
im_data = im_data - mean_data; % 零均值
crops_data = zeros(CROPPED_DIM, CROPPED_DIM, 3, 10, 'single');%注意此处是因为prototxt的输入大小为宽*高*通道数*10
indices = [0 IMAGE_DIM-CROPPED_DIM] + 1;%获得十块每一块大小与原始图像大小差距,便于crops
%下面就是如何将一张图片crops成十块
n = 1;
%此处两个for循环并非是1:indices,而是第一次取indices(1),然后是indices(2),每一层循环两次
%分别读取图片四个角大小为CROPPED_DIM*CROPPED_DIM的图片
for i = indices
for j = indices
crops_data(:, :, :, n) = im_data(i:i+CROPPED_DIM-1, j:j+CROPPED_DIM-1, :);%产生四个角的cropdata,1 2 3 4
crops_data(:, :, :, n+5) = crops_data(end:-1:1, :, :, n);%翻转180°来一次,产生四个角的翻转cropdata,6 7 8 9
n = n + 1;
end
end
center = floor(indices(2) / 2) + 1;
%以中心为crop_data左上角顶点,读取CROPPED_DIM*CROPPED_DIM的块
crops_data(:,:,:,5) = ...
im_data(center:center+CROPPED_DIM-1,center:center+CROPPED_DIM-1,:);
%与for循环里面一样,翻转180°,绕左边界翻转
crops_data(:,:,:,10) = crops_data(end:-1:1, :, :, 5); 可视化提取出的这十个图像:
clear
clc
close all
%caffenet的解读:http://www.2cto.com/kf/201606/515700.html
%% 设置网络
addpath('..') %加入+caffe路径
caffe.set_mode_cpu();%设置CPU模式
model = '../../models/bvlc_reference_caffenet/deploy.prototxt';%模型
weights = '../../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel';%参数
net=caffe.Net(model,'test');%测试
net.copy_from(weights); %得到训练好的权重参数
net %显示net的结构
%% 预处理
d = load('../+caffe/imagenet/ilsvrc_2012_mean.mat');
mean_data = d.mean_data;%读取均值
im = imread('../../examples/images/cat.jpg');%读取图片
IMAGE_DIM = 256;%图像将要resize的大小,建议resize为图像最小的那个维度
CROPPED_DIM = 227;%最终需要把一张图片crops成十块,最终求出每一块可能的标签
im_data=im;
im_data = im(:, :, [3, 2, 1]); %matlab按照RGB读取图片,opencv是BGR,所以需要转换顺序为opencv处理格式
im_data = permute(im_data, [2, 1, 3]); % 原始图像m*n*channels,现在permute为n*m*channels大小
im_data = single(im_data); % 强制转换数据为single类型
im_data = imresize(im_data, [IMAGE_DIM IMAGE_DIM], 'bilinear'); % 线性插值resize图像
% im_data = im_data - mean_data; % 零均值
crops_data = zeros(CROPPED_DIM, CROPPED_DIM, 3, 10, 'single');%注意此处是因为prototxt的输入大小为宽*高*通道数*10
indices = [0 IMAGE_DIM-CROPPED_DIM] + 1;%获得十块每一块大小与原始图像大小差距,便于crops
%下面就是如何将一张图片crops成十块
n = 1;
%此处两个for循环并非是1:indices,而是第一次取indices(1),然后是indices(2),每一层循环两次
%分别读取图片四个角大小为CROPPED_DIM*CROPPED_DIM的图片
for i = indices
for j = indices
crops_data(:, :, :, n) = im_data(i:i+CROPPED_DIM-1, j:j+CROPPED_DIM-1, :);%产生四个角的cropdata,1 2 3 4
crops_data(:, :, :, n+5) = crops_data(end:-1:1, :, :, n);%翻转180°来一次,产生四个角的翻转cropdata,6 7 8 9
n = n + 1;
end
end
center = floor(indices(2) / 2) + 1;
%以中心为crop_data左上角顶点,读取CROPPED_DIM*CROPPED_DIM的块
crops_data(:,:,:,5) = ...
im_data(center:center+CROPPED_DIM-1,center:center+CROPPED_DIM-1,:);
%与for循环里面一样,翻转180°,绕左边界翻转
crops_data(:,:,:,10) = crops_data(end:-1:1, :, :, 5);
cat_map=zeros(CROPPED_DIM*2,CROPPED_DIM*5,3);%两行五列展示
cat_num=0;
for i=0:1
for j=0:4
cat_num=cat_num+1
cat_map(CROPPED_DIM*i+1:(i+1)*CROPPED_DIM,CROPPED_DIM*j+1:(j+1)*CROPPED_DIM,:)=crops_data(:,:,:,cat_num);
end
end
imshow(uint8(cat_map)) 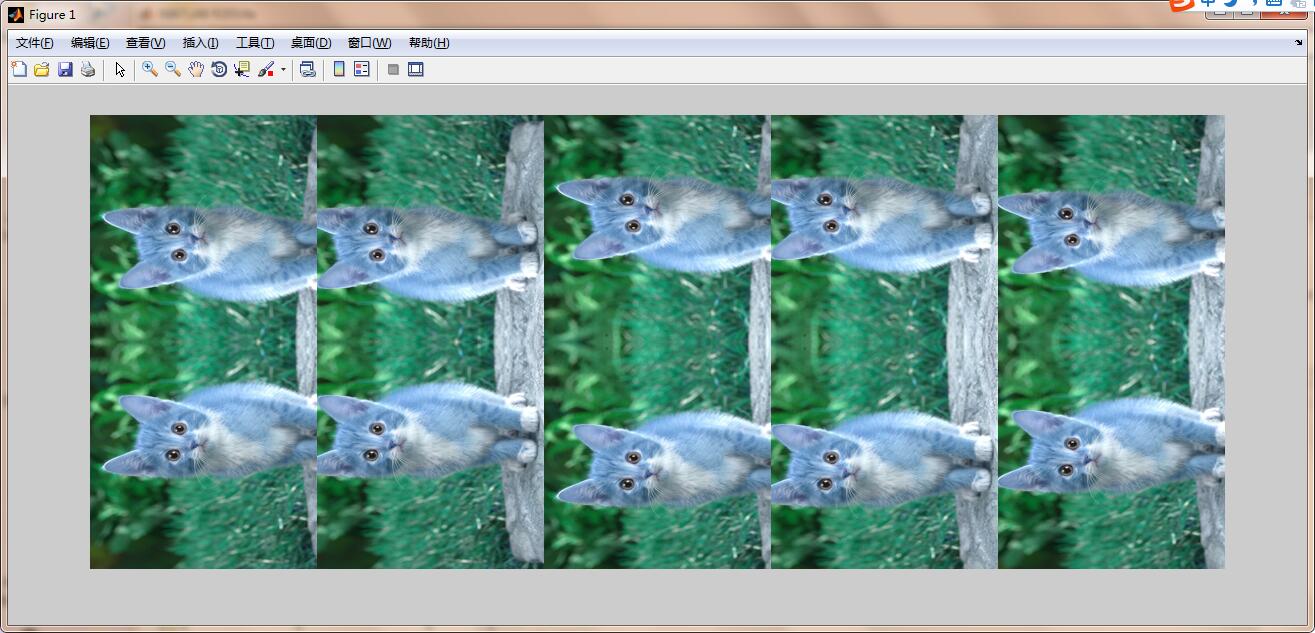
看着比较怪的原因在于,中间经过了matlab处理方式到opencv处理方式的转变,但是我们依旧用matlab输出了。
前向计算
res=net.forward({crops_data});
prob=res{1};
prob1 = mean(prob, 2);
[~, maxlabel] = max(prob1); 这一步完毕以后,整个网络就会充满参数了,权重,特征图均生成完毕,接下来可视化它们。
特征图可视化
特征图提取方法
说一下步骤,首先利用net 中的blob_name函数取出与deploy.prototxt对应的 top 名字,显示一下看看
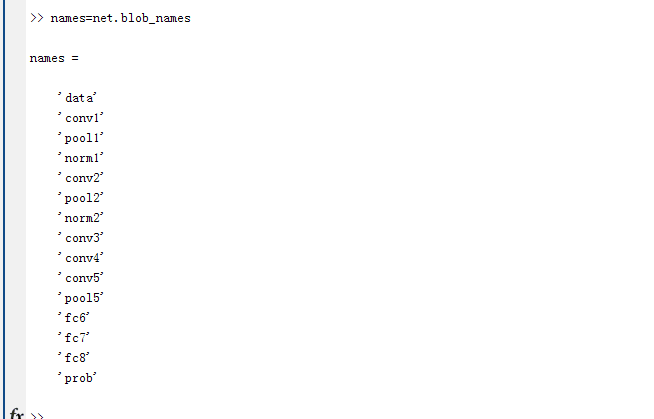
然后利用blob调用get_data()函数获取我们需要的特征图的值。注意,每一层的特征图是四维,看看前三层的特征图大小:

结合deploy中每一层的卷积核大小以及步长,利用 (当前层特征图大小 - 卷积核大小) / 步长+1=下一层特征图大小,可以推导出每一个featuremap 的前两维,第三个维度代表的是卷积核个数,featuremap {2}到featuremap {3}是池化了。第四个维度代表最开始输入了十张图
部分可视化方法
这一部分针对指定的第crop_num张图像在第map_num层进行可视化。注意,这一部分的可视化包含池化层等。
function [ ] = feature_partvisual( net,mapnum,crop_num )
names=net.blob_names;
featuremap=net.blobs(names{mapnum}).get_data();%获取指定层的特征图
[m_size,n_size,num,crop]=size(featuremap);%获取特征图大小,长*宽*卷积核个数*通道数
row=ceil(sqrt(num));%行数
col=row;%列数
feature_map=zeros(m_size*row,n_size*col);
cout_map=1;
for i=0:row-1
for j=0:col-1
if cout_map<=num
feature_map(i*m_size+1:(i+1)*m_size,j*n_size+1:(j+1)*n_size)=(mapminmax(featuremap(:,:,cout_map,crop_num),0,1)*255)';
cout_map=cout_map+1;
end
end
end
imshow(uint8(feature_map))
str=strcat('feature map num:',num2str(cout_map-1));
title(str)
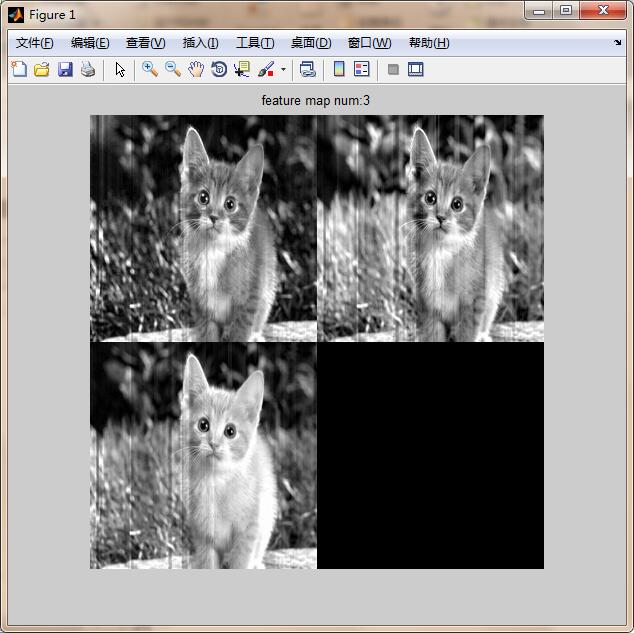
end 调用方法:
mapnum=1;%第几层的feature☆☆☆☆☆☆☆☆
crop_num=1;%第几个crop的特征图☆☆☆☆☆☆☆☆
feature_partvisual( net,mapnum,crop_num ) 中间有个处理细节是归一化然后乘以255,是避免featuremap的数值过小,或者有负数,导致特征图一片漆黑;在下面的权重可视化方法采取的是另一种处理。
读者可以更改”☆”标志的行中的数值去提取不同crop图像的不同层特征图。
第一层特征图:
第二层featuremap:

全部可视化
这一部分可视化每一张输入图片在指定卷积层的特征图,按照每一行为存储图片的特征图为图例。
function [ ] = feature_fullvisual( net,mapnum )
names=net.blob_names;
featuremap=net.blobs(names{mapnum}).get_data();%获取指定层的特征图
[m_size,n_size,num,crop]=size(featuremap)%获取特征图大小,长*宽*卷积核个数*图片个数
row=crop;%行数
col=num;%列数
feature_map=zeros(m_size*row,n_size*col);
for i=0:row-1
for j=0:col-1
feature_map(i*m_size+1:(i+1)*m_size,j*n_size+1:(j+1)*n_size)=(mapminmax(featuremap(:,:,j+1,i+1),0,1)*255)';
end
end
figure
imshow(uint8(feature_map))
str=strcat('feature map num:',num2str(row*col));
title(str)
end 调用方法:
mapnum=2;%第几层的feature☆☆☆☆☆☆☆☆
feature_fullvisual( net,mapnum ) 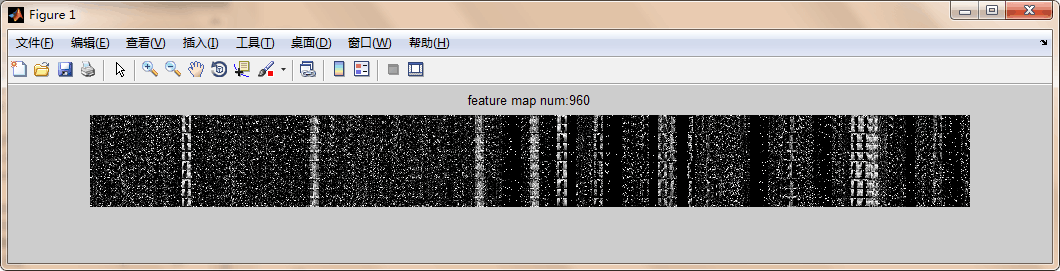
**
卷积核可视化
**
权重提取方法
先建议参考多通道卷积的概念:http://blog.csdn.net/u014114990/article/details/51125776,不看也行,注意这句话,每一个通道的卷积核是不一样的,同一个卷积核只在同一个特征图中共享,应该理解的没错吧o(╯□╰)o。(后续学习这篇,记得在人脸识别中,每个通道的卷积核是不一样的,然后进行重叠,即一个相加的过程,最后再加上偏置项。)
通过net 的layer_names 函数能够获取deploy.txt 对应的name 的名称,每一个name的blob对应两个值,分别是权重和偏置,提取方法如下:
layers=net.layer_names;
convlayer=[];
for i=1:length(layers)
if strcmp(layers{i}(1:3),'con')%仅仅卷积核能获取到权重
convlayer=[convlayer;layers{i}];
end
end
w=cell(1,length(convlayer));%存储权重
b=cell(1,length(convlayer));%存储偏置
for i=1:length(convlayer)
w{i}=net.layers(convlayer(i,:)).params(1).get_data();
b{i}=net.layers(convlayer(i,:)).params(2).get_data();
end 提取完毕以后观察一下每一层的权重维度,发现也是四维,显示一下前三个卷积核的维度:
size(w{1})= 11 11 3 96
size(w{2})= 5 5 48 256
size(w{3})= 3 3 256 384 前两个维度不说了,卷积核的大小,第三个维度代表卷积核的左边,也就是上一层的特征图的个数(对应前面说的每一个通道对应不同卷积核),第四个维度代表每一个通道对应的卷积核个数(也就是卷积核右边下一层的特征图的个数)。
部分可视化的方法
那么我们可视化也是可选的,需要选择哪一个特征图对应的卷积核,可视化方法如下:
function [ ] = weight_partvisual( net,layer_num ,channels_num )
layers=net.layer_names;
convlayer=[];
for i=1:length(layers)
if strcmp(layers{i}(1:3),'con')
convlayer=[convlayer;layers{i}];
end
end
w=net.layers(convlayer(layer_num,:)).params(1).get_data();
b=net.layers(convlayer(layer_num,:)).params(2).get_data();
w=w-min(min(min(min(w))));
w=w/max(max(max(max(w))))*255;
weight=w(:,:,channels_num,:);%四维,核长*核宽*核左边输入*核右边输出(核个数)
[kernel_r,kernel_c,input_num,kernel_num]=size(w);
map_row=ceil(sqrt(kernel_num));%行数
map_col=map_row;%列数
weight_map=zeros(kernel_r*map_row,kernel_c*map_col);
kernelcout_map=1;
for i=0:map_row-1
for j=0:map_col-1
if kernelcout_map<=kernel_num
weight_map(i*kernel_r+1+i:(i+1)*kernel_r+i,j*kernel_c+1+j:(j+1)*kernel_c+j)=weight(:,:,:,kernelcout_map);
kernelcout_map=kernelcout_map+1;
end
end
end
figure
imshow(uint8(weight_map))
str1=strcat('weight num:',num2str(kernelcout_map-1));
title(str1)
end 调用方法:
layer_num=1;%想看哪一个卷积核对应的权重☆☆☆☆☆☆☆☆☆☆
channels_num=1;%想看第几个通道对应的卷积核
weight_partvisual( net,layer_num ,channels_num ) 

全部可视化
将指定卷积层对应的每一个特征图的全部卷积核画出
function [ ] = weight_fullvisual( net,layer_num )
layers=net.layer_names;
convlayer=[];
for i=1:length(layers)
if strcmp(layers{i}(1:3),'con')
convlayer=[convlayer;layers{i}];
end
end
weight=net.layers(convlayer(layer_num,:)).params(1).get_data();%四维,核长*核宽*核左边输入*核右边输出(核个数)
b=net.layers(convlayer(layer_num,:)).params(2).get_data();
weight=weight-min(min(min(min(weight))));
weight=weight/max(max(max(max(weight))))*255;
[kernel_r,kernel_c,input_num,kernel_num]=size(weight);
map_row=input_num;%行数
map_col=kernel_num;%列数
weight_map=zeros(kernel_r*map_row,kernel_c*map_col);
for i=0:map_row-1
for j=0:map_col-1
weight_map(i*kernel_r+1+i:(i+1)*kernel_r+i,j*kernel_c+1+j:(j+1)*kernel_c+j)=weight(:,:,i+1,j+1);
end
end
figure
imshow(uint8(weight_map))
str1=strcat('weight num:',num2str(map_row*map_col));
title(str1)
end 

**
全连接探讨:
**
这里初步探索一下CaffeNet 的最后一个池化层pool5到第一个全连接层fc6的连接,我最开始的理解是直接把pool层所有的单元拉成一个列向量,不过分析以后,感觉应该是类似BP,pool5先被拉成一个一维向量,然后利用权重连接到fc6层的所有单元上,类似二部图的连接方法。
实验过程如下:
①首先提取出pool5的特征图大小:
>> A=net.blobs('pool5').get_data();
>> size(A) ans =
6 6 256 10 可以发现对于每一个输入图片(总共十张)都有256个6*6大小的特征图。预先计算一下256*6*6=9216
②然后提取出fc6的特征图大小:
>>B=net.blobs('fc6').get_data();
>> size(B) ans =
4096 10 然后发现pool5到fc6的连接并不是简单的拉成一维向量,而是利用了一个9216*4096的权重去将pool5的特征映射到fc6的单元中。
③验证一下是否如所想的映射方法, 只需要看看pool5到fc6的权重大小即可:
>>C=net.layers('fc6').params(1).get_data();
>> size(C)
ans =
9216 4096 发现果真如此,所以池化层到全连接层的确是用了一次映射而非简单的拉成向量。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









