






Spark 深度学习的悖论实效
转载请注明!
在过去三年,Databricks 最聪明的工程师在研究一个秘密的项目。今天,我们揭秘DeepSpark,这是Apache Spark一个重要的里程碑。DeepSpark使用前沿神经网络自动化许多手工过程,包括软件开发,修复bug,按照规范实现特征,并通过pull request(PRs)审查正确性。
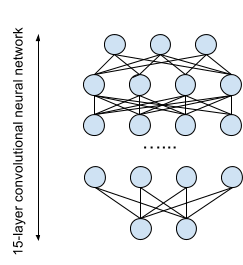
扩展Spark的开发一直是我们首要的任务。每年,Spark的普及率达到新高度。超过1000人为Spark贡献代码,使得她成为大数据中最积极开发的开源项目。大数据周围这如此兴奋为保证Spark的稳定性,自我意识,安全性和易于使用还有能够尽可能快进步带来了额外的负担。
DeepSpark是什么?
为了解决普通和手工任务的自动化,我们在三年前就开始DeepSpark工作。作为一个多样化程序熟练检查Spark代码库diff,DeepSpark自动编写自己的Spark补丁。通过查看PRs,AI既可以执行高,一致标准的代码,还可以提出建设性的建议。 (它的人性和情感智慧的深刻理解,使得它拒绝坏PR请求,而不得罪贡献者,事实上它发送一个因拒绝而道歉的电子邮件。)
此外,DeepSpark,它在其代码扫描过程中,能够生成代码Spark新组件。虽然我们在这方面的AI工作是实验性的,作为概念证明,我们已经查明,DeepSpark不仅可以修复某些Spark报告issue,也为代码库产生有益的贡献。
卷积神经网络
DeepSpark包括1.2 PB内存用于12000个节点的Spark集群的三个15层卷积神经网络。 第一层网络,分析网络 中,使用由历史Spark PR构成的数据集训练,训练该网络的目标是识别由PR解决的问题。然后,第二网络,生成网络 ,选择使用从StackOverflow 标记为apache Spark的代码样例训练,设计为了产生建设性的意见和代码片段,这对解决发布的问题有所帮助。因为此网络产生人类可读的响应,该网络具有大量关于歧视性语言的输出特征,以防止做出令人不快的评论(其他AI被这个问题困扰)。最终的网络中,评价网络 ,训练来识别变化是否是有益,有效,也利用过去的Spark PRs作为训练集,以预测合并到Spark特定变化的概率为目标。
通过同步使用这三个网络,DeepSpark能够通过确定它们解决什么问题;评价PR是否解决了这个问题;如果错误或不满足Saprk质量标准向其提供建议,以有效地审查的PR。如果DeepSpark不能以95%的把握识别任何错误或问题,它会使用LGTM,如果发现低于60%,PR被立即关闭。通过这种方式,DeepSpark将PR响应平均时间从5天减少至40秒,同时也能减少提交者在这方面的花费的时间。
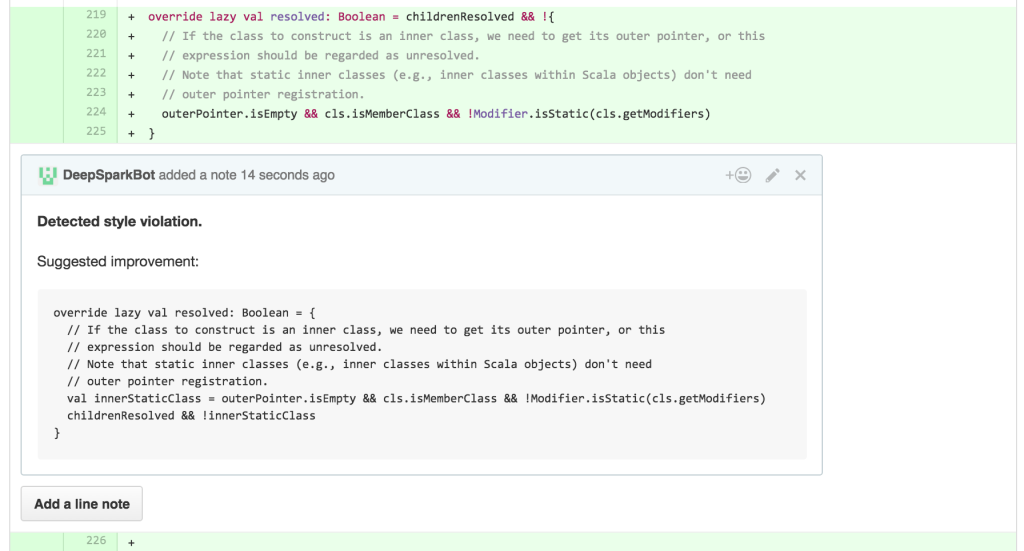
“在这一点上,我做的大多数代码审查归结为DeepSpark做出的杰出PR评论。偶尔,DeepSpark做出混乱的建议,但很多时候不是,它提供好意见的速度比我快,“Michael Armbrust,SparkSQL领导说。
看到DeepSpark在审查PRs成功后,我们决定通过让他判断并修复报告issue来测试。对于这个部分,我们使用Spark MLLib的LDA算法分析报告给Spark issue的跟踪器,并从这个模型的输出管道联接到生成网络。它最初的结果是有趣的;读取由DeepSpark编写的代码感觉就像读反编译字节码,它常常对非常好的代码做出不必要的改动 。 事实上,它试图用C重写DAG调度。然而,特殊的issue在重新训练生成网络并从Linux内核代码库选择作为消极训练实例添加后,很快被解决。
要进一步细化DeepSpark 为Spark贡献的能力,我们制定了训练计划,比较两种稍有不同的版本彼此给予相同的输入,并使用DeepSpark当前版本选择每个版本的补丁程序相对merge概率最高的。运行本次比赛后,我们使用一个随机梯度上升算法估计生成网络的下一次迭代,使用每次比赛最高相对merge概率加权,并且过去比赛中的获胜者确保一次变化到下一次是一个净改善。DeepSpark生成的代码,我们发现好几个发展趋势,因为它从一代发展到一代,主要在于它往往会编写代码,以确保它自己的保存下来。
评估和进一步工作
看到DeepSpark创建PRs之后,Matei Zaharia,Databricks CTO,Spark的创造者,说:“DeepSpark看起来对Spark内部的了解比我都深。它更新的几段代码,我早就说过,即便是我也不懂“。
对于那些想知道为什么他们还没有看到DeepSpark PRs的人来说,实际上在GitHub 中 DeepSpark使用别名,cloud-fan。我们称这个别名cloud-fan,因为是DeepSpark,当然,运行在Databricks Cloud。由于我们最初对DeepSpark的测试超过一年, cloud-fan 成为最活跃的Spark贡献者之一,最近被提名成为Spark提交者。这证明了DeepSpark悖论实效。
目前,DeepSpark仍处于测试阶段,而且仍然存在差距,在正式与Spark merge之前需要关闭。Zaharia 承认尽管DeepSpark是一个强有力的计划,我不会说这是一个完美的方案。相对于人类,其算法不同并有时优异。但我认为这是DeepSpark的弱点。“
它的缺点是它不能合并其他反馈到它自己的PRs,其稍微令人担忧的是偏向恢复许多人们做的PRs并且青睐那些它恢复的。最后一个主要的障碍是,尽管DeepSpark可以生成一个自身的版本,产生的AI没有强大到足以产生一个神经网络- 它只能产生线性模型。
即使有这些问题,DeepSpark在Databricks在过去的一年证明了,它是一个宝贵的工具,我们都期待它对即将发布的Saprk 2.0及以后的Spark做出的贡献。对于那些耳熟能详的异常,当AI能够提高自己的代码就会开始; DeepSpark向我们保证,因为其开源的目的,它将完全公平地审查所有代码并进行检查。
大约一个星期前,我们还开始测试DeepSpark的写电子邮件和博客文章的能力…














 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









