







前提
请先认真阅读下面两篇博文:
阮一峰博客(贝叶斯推断及其互联网应用(一):定理简介)
阮一峰博客(贝叶斯推断及其互联网应用(二):过滤垃圾邮件)
举例:
假设某种癌症的患病率是1%
若得了这种癌症,检查结果呈阳性的概率90%(敏感性sensitivity)
若没有得这种癌症,检查结果90%呈阴性(特异性specificity),但仍然有10%的可能性检查呈阳性。
在没有任何症状的情况下,你到医院检查,得到的结果是阳性。
那么你真正患癌症的概率是多少?
答:
先验概率:
P(C) = 0.01 = 1%(患病概率)
P(ℸC) = 0.99(非患病概率)
由前面,我们得知:
P(Pos|C) = 0.9(敏感性(患病情况下,检查呈阳性的概率))
P(Neg|ℸC) = 0.9(未患病情况下,检查呈阴性的概率)
即可得出:
P(Pos|ℸC) = 0.1(未患病情况下,检查呈阳性的概率)
联合概率:
P(C, Pos) = P(C) • P(Pos|C) (先验概率乘以敏感性)
P(ℸC, Pos) = P(ℸC) • P(Pos|ℸC)(在阳性情况下,未得癌症的概率)
P(Pos) = P(C, Pos) + P(ℸC, Pos)(被检测为阳性的概率)
那么:
P(Pos) = 0.01 • 0.9 + 0.99 • 0.1 = 0.108
P(C|Pos) = P(C) • P(Pos|C) / P(Pos) = 0.01 • 0.9 / 0.108 = 0.083333
结果:
你得癌症的概率是8.333% ,所以,如果真的被检测为癌症阳性。也不要悲观,因为误诊的概率还是非常大的。^_^
正题
决策面
前面我们提到,在监督学习中,我们需要大量的数据提供给计算机学习。这些数据都是经过标记(tagged)的数据。
那么“一般”(因为我们先讨论最简单的二值分类)的标记为二值的,也就是说True和False。
我们要喂给计算机这些经过标记的数据。计器学习算法会定义决策面(dicision surface,也就是可以根据数据的特性判定数据为True还是False的界线)。
如下:
假设提供的数据散点分布如下:
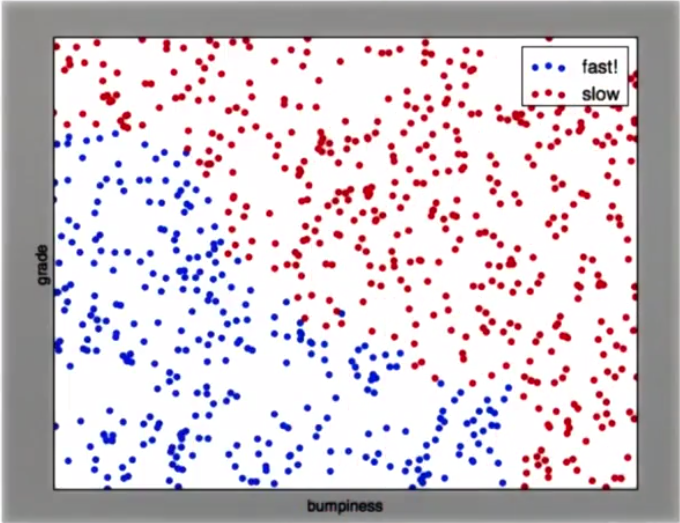
那么,经过良好的训练之后,或许我们会得到如下的决策面:

有了这样的决策面之后,再给计算机提供测试数据时,就可以确定该测试数据位于决策面的哪一侧,也就得到了True或False.
当然,大家也看到了这里有一定的准确率。当提供足够多的数据进行训练,这种准确率就会越来越高。当高到一定的程度时,我们就可以认为计算机“学会”了如何分类。
朴素贝叶斯(Naive bayes)
关于朴素贝叶斯的概念,及应用请参考阮一峰大侠的博客。
高斯朴素贝叶斯(GassianNB)
GassianNB是朴素贝叶斯算法的一种。而朴素贝叶斯算法也源于一个算法库:scikit-learn简写为sklearn
使用方法如下:
# 导入sklearn库中的高斯贝叶斯算法
from sklearn.naive_bayes import GaussianNB
# 创建分类器
clf = GaussianNB()
# 提供训练特性集(向量集)和训练标签(向量集)来训练此分类器
clf.fit(features_train, labels_train)
# 给训练好的分类器提供测试数据集(向量集)得到类别标签
print(clf.predict(features_test))假设你想知道这个训练好的分类器的精度,那么可以通过调用score函数。
# 给score函数提供测试集和对应的正确的标签集,返回精确度
accuracy = clf.score(features_test, labels_test)或者如下:
# 测试分类器
pred = clf.predict(features_test)
# 导入accuracy_score函数
from sklearn.metrics import accuracy_score
# 计算精度
accuracy = accuracy_score(pred, labels_test)总结
- 理解朴素贝叶斯理论
- 使用高斯贝叶斯分类器,对数据集进行训练。
- 使用测试集检测分类器的精度
- 朴素贝叶斯分类有优点也有缺点。优点:易于执行,特征空间大,运行容易,比较有效。缺点:会有间断(比如搜索芝加哥公牛,会得到芝加哥和公牛两种事物的结果),所以由多个单词组成且意义明显不同的短语就不适合朴素贝叶斯。
代码下载
以下代码来源:
高斯贝叶斯分类器 - 产生决策面
高斯贝叶斯分类器 - 精度
参考:
阮一峰博客(贝叶斯推断及其互联网应用(一):定理简介)
阮一峰博客(贝叶斯推断及其互联网应用(二):过滤垃圾邮件)
机器学习入门 - Udacity














 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









