







1 介绍
1.1 处理流程
当MYSQL 收到一条查询请求时,会首先通过关键字对SQL语句进行解析,生成一颗“解析树”,然后预处理器会校验“解析树”是否合法(主要校验数据列和表明是否存在,别名是否有歧义等),当“解析树”被认为合法后,查询优化器会对这颗“解析树”进行优化,并确定它认为最完美的执行计划。
1.2 衡量标准
MYSQL查询优化器衡量某个执行计划是否完美的标准是“使用该执行计划时的成本”,该成本的最小单位是读取一个4K数据页的成本。
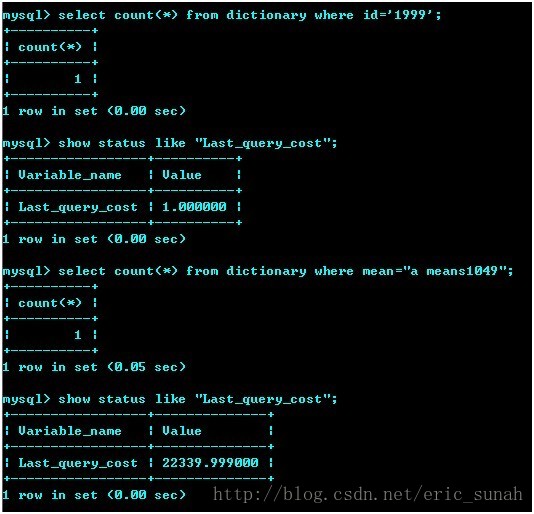
下面图中的数据说明,当使用id为条件查询时,查询的成本只有一个数据页,而使用mean(非索引)查询时,成本将近是22334个数据页
1.3 优化手段
下面列出了一些优化器常用的优化手段,但实际上远远不止这些
1. 重新定义关联表的顺序
对于多表关联的查询(INTER JOIN),优化器会根据数据的选择性来重新决定关联的顺序,选择性高的会被置前。
如果关联设计到N张表,优化器会尝试N!种的关联顺序,从中选出一种最优的排列顺序,如果有10张表进行关联,就有3628800种排序的可能,优化器可能需要经过3628800次的尝试才能得到一个最优的顺序。面对这种数量很大的排序任务,优化器并没有老老实实的尝试3628800次,而是当达到optimizer_search_depth指定的次数后,就会采用“贪婪模式”进行处理。这也表明关联表的数量不能太多
此功能可以通过STRAIGHT_JOIN关键字来进行屏蔽
2. 排序优化
当不能使用索引进行排序时,MYSQL会对结果集进行排序,这时候会采取两种策略:(1)如果结果集的容量小于“排序缓冲区”的容量,在内存中进行排序(2)如果查询的结果大于“排序缓冲区”,则先将结果集拆分成多个“排序缓冲区”可以容纳的子集,然后把各个子集排序的结果存放在磁盘上,最后对各个子集进行合并
在排序的过程中使用临时表的存储空间可能要比实际的存储空间大很多,主要是因为在排序的时候都会为每个字段保留最大的存储空间
当进行关联查询排序时,如果order by的字段全部来自第一张表,则在对第一张表进行关联处理时,就会进行排序动作(Extra 中会包含Using filesort),否则会对多表关联后的结果进行排序(Extra 中包含,Using temporary, Using filesort)。
在MYSQL5.6 之前的版本中, LIMIT关键字的作用只会在排序完之后才生效,所以即使在查询中包含了LIMIT,查询还是会对大量的数据进行处理
3. 等价规则
例如 出现 where 5=5 and a>5 会转化成where a>5
4. COUNT(),MIN(),MAX()
对于B-Tree索引而言,Max()/Min()的结果分别返回的是二叉树中最左边以及最右边的值,所以不需要进行表的访问就可以直接取到对应的值。
对于Count()函数而言,在MYISAM引擎中维护了一个对应的常量值,也不需要对表进行访问就可以直接取到Count的值。
经过这种优化过的SQL,在EXTRA中会出现 “Selecttables optimized away”的字样

5. 转化为常数表达式
首先要说明的是,在数据库对查询进行处理的时候, 以常数(Constant)的方式进行处理的速度是最快的。查询优化器在优化的过程中,如果发现一个表达式可以转换为常数,就会将表达式转换为常数进行处理。
在优化阶段,一个查询也可以转换为常数,例如 在索引列上执行Min(),在where中对主键或者是唯一键进行条件限制等。

6. 覆盖索引扫描
参见:http://blog.csdn.net/eric_sunah/article/details/16830057
7. 提前终止
在下列几种情况中,查询会提前终止,并不再对表进行扫描
· 当优化器发现查询的结果已经满足查询需求的时候。比如查询中用到了LIMIT
· Where的条件不成立的时候。例如 where id>100 and id <10

8. 等值传播
对于通过列关联的查询,某列的where条件可以自动的从一张表传递到另外一张表,例如
Select film.filmid from film
Inter join film_actor using (filmid)
Where film.filmid>50;
上面的查询只是显示的指出film.filmid>50,但是优化器在优化的工程中会将其转化为
Where film.filmid>50 and film_actor.filmid>50.
9. 列表IN()的比较
…..where id in(2,4,1,3,8,6) 这种类型的限制条件在很多的RDBMS中等同于
where id=2 or id=4 or id=3 or id=8 or id=6. 这种算法的复杂度是O(n).
而在MYSQL中,首先会对In列表进行排序,然后通过二分查找的方式进行比较,该方式的算法复杂度是O(log n).如果IN列表中的数据量非常的大,则效果会非常的明显














 4017
4017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









