










1.简介
在样本有限的情况,样本分布不规律且含有噪声的情况下,用最近邻来做决策难免有一定风险,因此对其引入打分机制,对未知样本的决策,不仅仅只依赖于最近的那一个已知样本,更可靠的做法是选择k个距离未知样本最近的已知样本,然后在这k个类别中进行打分来决定最后应该决策给谁。显然,最近邻就是1近邻。
另外,回顾下前面在讲概率密度函数的非参数估计时,是不是也提到了k近邻,没错,这篇文章就来认真的学习下k近邻。
2.主要思想
假设有已知样本,同样有c类,
;
对于新来未知样本x,假如现在已经找到了已知样本中与其最近的k个近邻样本,设其中有个的类别为
,则该类的判别函数为:
对应的决策规则为:
若,则
;
3.错误率分析
在最近邻中得到的有关错误率的结论,对于k近邻仍然适用;
设贝叶斯错误率为,当样本数
时,令
,则有:
图形表示如下:
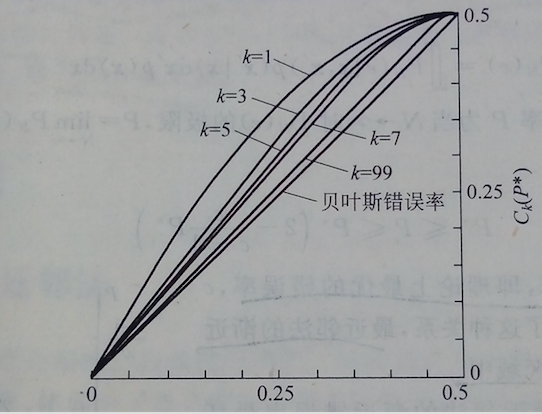
可以看出,随着近邻样本数k的增加,上界会逐渐变小,最终上界会无比接近于下界,这时k近邻就达到了最优错误率,即贝叶斯错误率,当然前提依然是样本数无限多。
另外要注意,这里k增加到很大很大时,这个很大必须要远小于样本数n,小到可以忽略,这也正是在用k近邻估计概率密度函数时为什么需要对k进行限制,所以在实际应用时一定要对k进行适当选择,对于两类问题k最好为奇数以避免打分相同,对于多类问题,如果出现打分相同的情况,就要考虑引入其他的打分机制。对于具有稀疏性的样本,可以根据离新的未知样本的距离远近来对打分进行加权,这样做可以减小稀疏样本中差别太大导致打分的不合理性和不公平性。
最后要注意的是,不管是最近邻还是k近邻,它只是给出一种决策方法,并不需要我们利用已知样本数据事先训练出一个判别函数,而是直接根据已知样本对新的未知样本进行分类决策,所以近邻法跟一般的设计分类器方法不太一样,它有点特殊,但也是它的优越之处,但是它也有缺陷,那就是需要对已知训练样本进行遍历,而这种遍历就要求必须存储每一个已知样本,因而计算量和存储都不会太小,后来有人为了改善其计算性能也做了很多改进,后续会学习到。














 4428
4428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









