






shuffle机制是mapreduce整个处理过程中的核心机制,涉及到了分组、排序、数据缓存以及中间结果传递(map结果怎么交付给reduce),其整个过程可以用一张图表示。
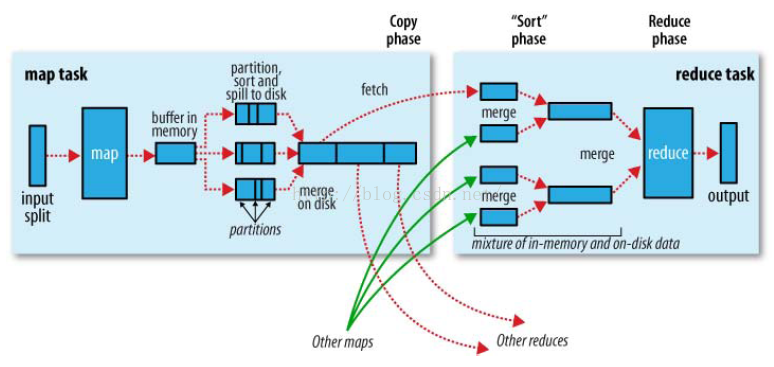
1.分组
当没有自定义分组时,默认所有的key在一个分组中。如果有自定义分组,则按照自定义的分组逻辑进行分组,对应图中的partitions,一个分组为一个partition。从图中可以看出一个partition被传递到一个reduce进行处理,也即有多少个partition就有多少个reduce进程。
此外,input split表示输入切片,mapreduce的输入路径是一个文件夹,程序默认读文件夹中的所有文件,这些文件在集群中是分散到多个datanode进行存储的,一个文件对应一个map进程。
2.排序
mapreduce程序在map、reduce过程中都有涉及到排序操作。
2.1 map过程中的排序
如图中map过程中的partition,sort,指的就是分组和排序,排序是按照map程序的key进行排序,key的数据类型都需要实现WritableComparable接口,具体的排序逻辑是按照key类中的compareTo方法。map排序的最终结果是对于该输入切片,数据按照分组逻辑进行分组后,每个分组中的数据也是有序的。
2.2 reduce过程中的排序
如果有多个分组和多个切片,那么同一个reduce接收的是来自各个map的处理结果,这些结果放在一起来看只是局部有序,因此在合并过程中需要再一次排序,这个排序仍然是按照map中的key。
3.数据缓存
map在处理过程中的输出结果(context.write())首先放在内存中,当分配的可用内存(可以通过配置文件指定,默认为100M)被占满时会溢出到磁盘,对应图中的spill to disk,我们知道内存操作是很快的,磁盘就不然。因此,mapreduce程序运行时比较慢的(读写磁盘是原因之一)。
这里牵涉到一个内存调优的问题,如果mapreduce可用内存分配的大,那么可能就不会溢出到磁盘或较少的溢出,整个map处理过程就比较快。
4.中间结果传递
map和reduce之间的信息传递靠的是MRAppmaster来协调,不同map的处理结果按照分组的不同被传递到不同的reduce进行combine操作。注意这里reduce从map拿到的不仅有溢出到磁盘结果信息还有内存中的缓存,对应图中的mixture of in-memory and on desk data.














 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









