







本文分一下几块:磁盘简介,磁盘调度,文件存储,存储的数据结构,常见磁盘类型,磁盘问题。
磁盘简介
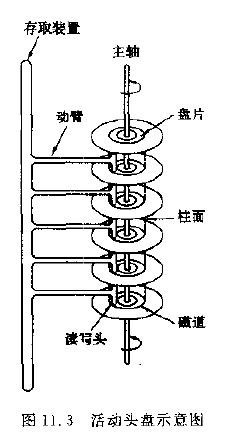
如上图所示,是一个活动头盘的示意图,当磁盘驱动器执行读/写功能时。盘片装在一个主轴上,并绕主轴高速旋转,当磁道在读/写头(又叫磁头)下通过时,就可以进行数据的读 /写了。以下介绍一个相关概念。
固定头盘:固定头盘的每一个磁道上都有独立的磁头,它是固定不动的,专门负责这一磁道上数据的读/写。
活动头盘: (如上图)的磁头是可移动的。每一个盘面上只有一个磁头(磁头是双向的,因此正反盘面都能读写)。它可以从该面的一个磁道移动到另一个磁道。所有磁头都装在同一个动臂上,因此不同盘面上的所有磁头都是同时移动的(行动整齐划一)。
磁道:当磁盘旋转时,磁头若保持在一个位置上,则每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道。
磁道密度:盘片同心圆半径区域,每英寸所含的磁道数。
扇区:磁盘上的每个磁道被等分为若干个弧段,这些弧段便是磁盘的扇区。
柱面:硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的“0”开始编号,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面。
坏扇区:在硬盘中无法被正常访问或不能被正确读写的扇区都称为Badsector。一个扇区能存储512Bytes的数据,如果在某个扇区中有任何一个字节不能被正确读写,则这个扇区为Badsector。除了存储512Bytes外,每个扇区还有数十个Bytes信息,包括标识(ID)、校验值和其它信息。这些信息任何一个字节出错都会导致该扇区变“Bad”。
磁盘簇:扇区是磁盘最小的物理存储单元,但由于操作系统无法对数目众多的扇区进行寻址,所以操作系统就将相邻的扇区组合在一起,形成一个簇,然后再对簇进行管理。每个簇可以包括2、4、8、16、32或64个扇区。显然,簇是操作系统所使用的逻辑概念,而非磁盘的物理特性。(簇(CLUST)的本意就是“一群”、“一组”,即一组扇区(一个磁道可以分割成若干个大小相等的圆弧,叫扇区)的意思。
磁盘盘片:是将磁粉附着在铝合金(新材料也有用玻璃)圆盘片的表面上,这些磁粉被划分成称为磁道的若干个同心圆,在每个同心圆的磁道上就好像有无数的任意排列的小磁铁,它们分别代表着0和1的状态.当这些小磁铁受到来自磁头的磁力影响时,其排列的方向会随之改变。利用磁头的磁力控制指定的一些小磁铁方向,使每个小磁铁都可以用来储存信息。
位密度:单位长度的位数。
磁盘容量:磁道数*扇区数*扇区内字节数*面数*片数。
磁头:硬盘的磁头是用线圈缠绕在磁芯上制成的,最初的磁头是读写合一的,通过电流变化去感应信号的幅度。对于大多数计算机来说,在与硬盘交换数据的过程中,读操作远远快于写操作,而且读/写是两种不同特性的操作,这样就促使硬盘厂商开发一种读/写分离磁头。
磁盘碎片:其实磁盘碎片应该称为文件碎片,是因为文件被分散保存到整个磁盘的不同地方,而不是连续地保存在磁盘连续的簇中形成的。 当应用程序所需的物理内存不足时,一般操作系统会在硬盘中产生临时交换文件,用该文件所占用的硬盘空间虚拟成内存。虚拟内存管理程序会对硬盘频繁读写,产生大量的碎片,这是产生硬盘碎片的主要原因。 其他如IE浏览器浏览信息时生成的临时文件或临时文件目录的设置也会造成系统中形成大量的碎片。
磁盘分区:计算机中存放信息的主要的存储设备就是硬盘,但是硬盘不能直接使用,必须对硬盘进行分割,分割成的一块一块的硬盘区域就是磁盘分区。在传统的磁盘管理中,将一个硬盘分为两大类分区:主分区和扩展分区。主分区是能够安装操作系统,能够进行计算机启动的分区,这样的分区可以直接格式化,然后安装系统,直接存放文件。
平均寻道时间:它是指硬盘在接收到系统指令后,磁头从开始移动到移动至数据所在的磁道所花费时间的平均值,它一定程度上体现硬盘读取数据的能力,是影响硬盘内部数据传输率的重要参数,单位为毫秒(ms)。不同品牌、不同型号的产品其平均寻道时间也不一样,但这个时间越低,则产品越好,现今主流的硬盘产品平均寻道时间都在在9ms左右。
平均旋转延迟:首先,读写头沿径向移动,移到要读取的扇区所在磁道的上方,这段时间称为寻道时间(seek time)。读写头起始位置与目标位置之间的距离不同,寻道时间也不同,一般为2--30毫秒,平均约为10毫秒。然后,通过盘片的旋转,使得要读取的扇区转到读写头的下方,这段时间称为旋转延迟时间(rotational latency time)。一个7200(转 /每分钟)的硬盘,每旋转一周所需时间为60×1000÷7200=8.33毫秒,则平均旋转延迟时间为8.33÷2=4.17毫秒(平均情况下,需要旋 转半圈)。按照同样的计算方法,一个5400(转/每分钟)的硬盘,平均旋转延迟时间为60×1000÷5400÷2=5.56毫秒。
平均存取时间:平均寻道时间与平均旋转延迟时间之和。
转速:是硬盘内电机主轴的旋转速度,也就是硬盘盘片在一分钟内所能完成的最大转数。转速的快慢是标示硬盘档次的重要参数之一,它是决定硬盘内部传输率的关键因素之一,在很大程度上直接影响到硬盘的速度。硬盘的转速越快,硬盘寻找文件的速度也就越快,相对的硬盘的传输速度也就得到了提高。硬盘转速以每分钟多少转来表示,单位表示为RPM,RPM是Revolutions Perminute的缩写,是转/每分钟。
举例:
假设一个有3个盘片的硬盘,共有4个记录面,转速为7200/分钟,盘面有效记录区域的外直径为30CM,内直径为10CM,记录位密度为250位/MM,磁道密度为8道/mm,每个磁道分16扇区,每扇区512字节。
总磁道数:Ct=m*(de-di)/2*磁道密度=4*(30-10)*10/2*8=3200。
非格式化容量:Cuf=总磁道数*内径磁道周长*位密度=3200*3.14*10*10*250/8=29.95M。
格式化容量:Cf=总磁道数×每扇区数×每扇区字节数=4*=25M。
平均数据传输速率:Cg=每磁道扇区数×每扇区字节数×转速/60=983040=960KB/S。
磁盘调度
当有多个进程访问磁盘,应采用一种最佳的调度算法,以使各进程对磁盘的平均访问时间最小。由于在访问磁盘的时间中,最主要是寻道时间,因此,磁盘调度目标,是使磁盘的平均寻道时间最小。常用的方法有:
1先来先服务(FCFS)。
2最短寻道时间优先(SSTF)。
该算法选择这样的进程,其要求访问的磁道,与当前磁头所在的磁道距离最近,以使每次的寻址时间最短,但这种算法不能保证平均寻址时间最短。
3扫描算法(SCAN) 。
SSTF算饭会导致某些进程“饥饿“,该算法不仅考虑到欲访问的磁道与当前磁道间的距离,更优先考虑的是磁头当前的移动方向。SCAN算法所考虑的下一个访问对象,应是其欲访问的磁道,既在当前磁道之外,又是距离最近的。这样自里向外地访问,直至再无更外的磁道需要访问时,才将磁臂换向自外向里移动。此方法广泛用于大,中,小型机器和网络中的磁盘调度。
4循环扫描(CSCAN)
CSCAN算法规定磁头单向移动,例如,只是自里向外移动,当磁头移动到最外的磁头并方位后,磁头立即返回到最里的欲访问磁道,即将最小磁道紧接着最大磁道号构成循环,进行循环扫描。
5 N-STep-SCAN算法。
将磁盘请求队列分成若干个长度为N的子队列,按FCFS算法依次处理这些子队列,而每处理一个队列时又是按SCAN算法。
6FSCAN算法。
将磁盘请求队列分成2个子队列,一个是当前所有请求磁盘I/O的进程行程的队列,由磁盘调度按SCAN算法进处理,在扫描期间,将新出现的所有请求磁盘I/O的进程,放入另一个等待处理的请求队列。这样所有的请求都将被推迟到下次扫描时处理。
文件的存储
数据项:最低级的数据组织形式,分为基本数据项,组合数据项。
FCB:
设置原因--为了便于对文件进行控制和管理,在文件系统内部,给每个文件惟一地设置一个文件控制块,这种数据结构通常由下列信息项组成:
文件名——符号文件名,如 files,mydata,ml.c等。
文件类型——指明文件的属性,是普通文件,还是目录文件,特别文件,是系统文件还是用户文件等。
位置——指针,它指向存放该文件的设备和该文件在设备上的位置,如哪台设备的哪些盘块上。
大小——当前文件的大小(以字节、字或块为单位)和允许的最大值。
保护信息——对文件读、写及执行等操作的控制权限标志。
使用计数——表示当前有多少个进程在使用(打开了)该文件。
时间——日期和进程标志,这个信息反映出文件有关创建、最后修改、最后使用等情况,可用于对文件实施保护和监控等。
做什么--核心利用这种结构对文件实施各种管理。例如,按名存取文件时,先要找到对应的控制块,验证权限。仅当存取合法时,才能取得存放文件信息的盘块地址。
文件类型:
按用途分为:系统文件,用户文件,库文件。按文件中数据的形式分为:源文件,目标文件,可执行文件。按存取控制属性分为:只读文件,只写文件,只执行文件。
文件操作:创建,删除,读,写,截断。
文件的逻辑结构:有结构文件(又称记录式文件),无结构文件(又称流式文件)。
有结构文件:
记录的长度分为定长和不定长。存储方式有:顺序文件,索引文件,索引顺序文件。
磁盘存储的数据结构
数据在磁盘上的存储涉及的B树,B+树,B*树等结构体。
B树的概念

B树的类型和节点定义如下图所示:

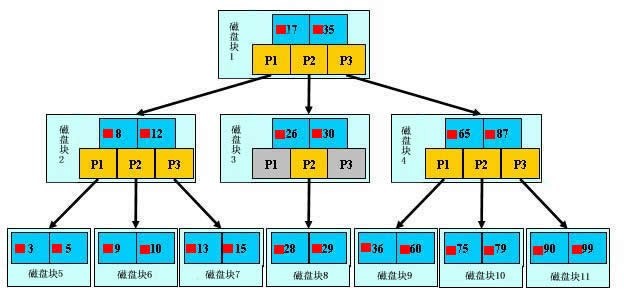
文件查找的具体过程(涉及磁盘IO操作)
为了简单,这里用少量数据构造一棵3叉树的形式,实际应用中的B树结点中关键字很多的。上面的图中比如根结点,其中17表示一个磁盘文件的文件名;小红方块表示这个17文件内容在硬盘中的存储位置;p1表示指向17左子树的指针。
其结构可以简单定义为:
typedef struct {
/*文件数*/
int file_num;
/*文件名(key)*/
char * file_name[max_file_num];
/*指向子节点的指针*/
BTNode * BTptr[max_file_num+1];
/*文件在硬盘中的存储位置*/
FILE_HARD_ADDR offset[max_file_num];
}BTNode;
假如每个盘块可以正好存放一个B树的结点(正好存放2个文件名)。那么一个BTNODE结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件29的过程:
-
根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘 IO 操作 1次】
-
此时内存中有两个文件名17、 35 和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针 p2 。
-
根据 p2 指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘 IO 操作 2次】
-
此时内存中有两个文件名26, 30 和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针 p2 。
-
根据 p2 指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘 IO 操作 3次】
-
此时内存中有两个文件名28, 29 。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。
当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘4次,最多5次,而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
B+是应文件系统所需而产生的一种B树的变形树。
一棵m阶的B+树和m阶的B树的差异在于:
1.有n棵子树的结点中含有n个关键字; (而B 树是n棵子树有n-1个关键字)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
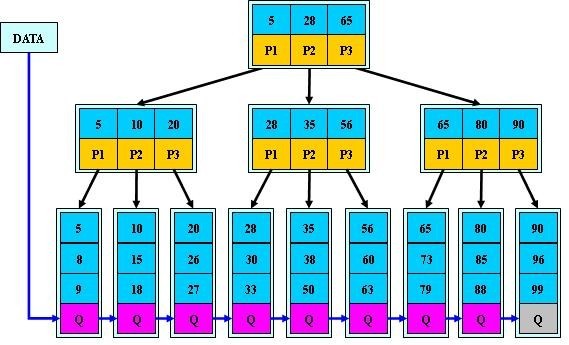
为什么说B+比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B树(一个结点最多8个关键字)的内部结点需要2个盘快。而B+树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B*-tree
B*-tree是B+-tree的变体,在B+树非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。给出了一个简单实例,如下图所示:
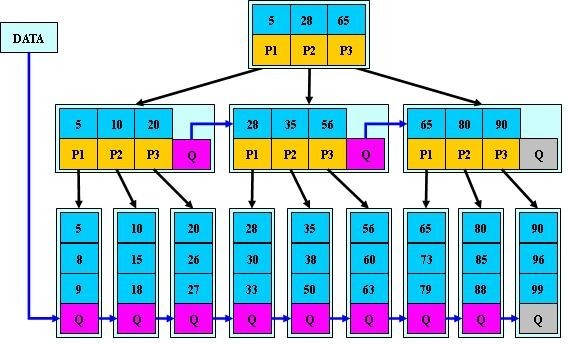
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
参考:http://blog.csdn.net/v_JULY_v/article/details/6530142
常见磁盘类型
常见磁盘类型有SATA,IDE,下面讲讲SATA跟IDE的对比。
1 .SATA硬盘比IDE硬盘传输速度高。目前SATA可以提供150MB/s的高峰传输速率。今后将达到300 MB/s和600 MB/s。到时我们将得到比IDE硬盘快近10倍的传输速率。
2. 相对于IDE硬盘的PATA40针的数据线,SATA的线缆少而细,传输距离远,可延伸至1米,使得安装设备和机内布线更加容易。连接器的体积小,
这种线缆有效的改进了计算机内部的空气流动,也改善了机箱内的散热。
3. 相对于IDE硬盘系统功耗有所减少。SATA硬盘使用500毫伏的电压就可以工作。
4. SATA可以通过使用多用途的芯片组或串行——并行转换器来向后兼容PATA设备。由于SATA和PATA可使用同样的驱动器,不需要对操作系统进行升级或其他改变。
5. SATA不需要设置主从盘跳线。BIOS会为它按照1、2、3顺序编号。这取决于驱动器接在哪个SATA连接器上(安装方便)。而IDE硬盘需要设置通过跳线来设置主从盘。
6. SATA还支持热插拔,可以象U盘一样使用。而IDE硬盘不支持热插拔。
NAS:Network Attached Storage
IP-SAN的发展 其实是由 NAS 和SAN 发展过来的。
NAS SAN IP-SAN 从应用的角度来看,其实不难看出 SAN 应用于大型的数据中心(比如银行 保险业)IP-SAN 应用于中型的企业(在一个整体的大型的数据中心 IP-SAN是无法和SAN相比
的。毕竟一条专用的存储区域网要比再IP网络中,在速率上要快很多。但成本就比SAN要低很多了)NAS应用于小型企业(无法实现数据库的备份。只工作在文件级的应用上)
磁盘问题
1磁盘容错?
2磁盘上,删除的数据如何恢复?















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











