







多元线性方程
在上一周的学习中,我们给出了一个hθ(x)=θ0+θ1*x .这样的简单的线性方程,但是,我们一般得到的训练组都是有很多的数据,那么此时这个方程就变成了这样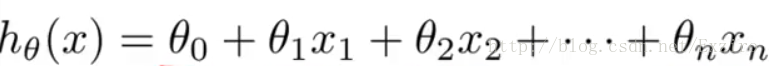
我们把其中的θ和X数据提取出来,用一个多维矩阵表示
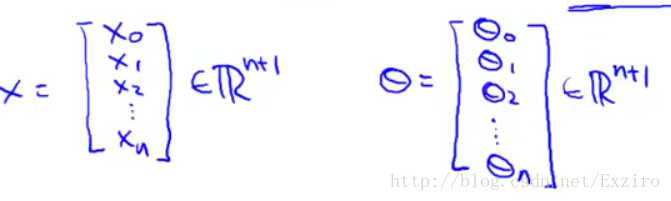
多元线性在梯度算法中的应用
在前面我们曾提到过代价函数,用来作为我们在梯度算法中的一种处理找出最优解的一种方法
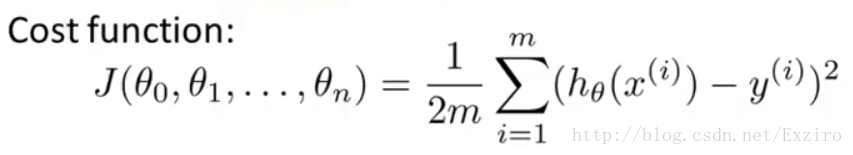
此时我们将多远线性方程代入这个式子,这样我们在处理梯度的时候的式子便可以化简为

我们将其中的J(θ)替换即可,图示仅为梯度算法的公式。将上面的式子展开得到。

这里我说一下X的下标代表的是第几个参数,而上标则表示在这个多维参数中的第几个确定的值。这就是多元线性回归式子在梯度中的算法。
特征缩放
在进行梯度算法时,我们假设有两个参数X1,X2。这里我们给X1的取值假设为0到10000而X2的取值范围为0到20.这时我们运用代价函数汇出梯度图。(这里是2D的但是你可以把它想象成一个漏斗)
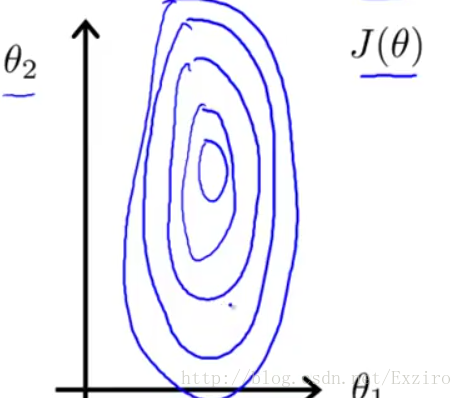
然后我们运用梯度算法查找最优值
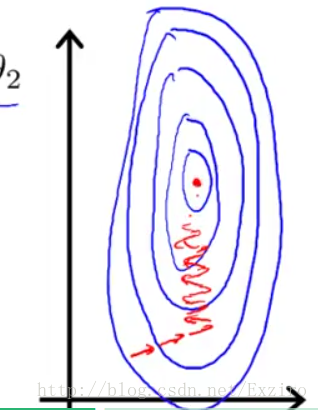
我们很明显能够感受到这样走下去有些繁杂,其原因使我们给出的两个参数值相差过大,我们给出的图只是一个简单的图。如果可能 实际划出的图或许会更加细长,这样我们在寻找最优解时会更加困难,此时我们就需要对我们的参数进行优化,这里有两种方法。
1.用数值除以其最大值。这里我们的意思是直接用我们得到的参数除以参数的最大值,以此来稍微修正一下我们的图形,因为这样得到的参数的大小会在0到1之间,所以,得出的梯度图会更加圆滑一点。这是特征算法的一种方式。
学习率

这里引用Ng的一张图来解释为什么我们要调整学习率,在这张图上,竖轴是我们的代价函数,而横轴则是我们的迭代,也就使我们梯度下降算法中的步数,一步一步,随着迭代的增加,我们发现函数趋于平稳,这也是我们能够找到最佳值的前兆。总结一下来讲,学习率需要确定在一个非常确切的阈值,如果学习率过小,那么我们想要使函数曲线更平稳就会十分缓慢,而如果我们给的学习率过大,则会造成我们的迭代无限循环,无法达到最低点,以至于无法收敛。
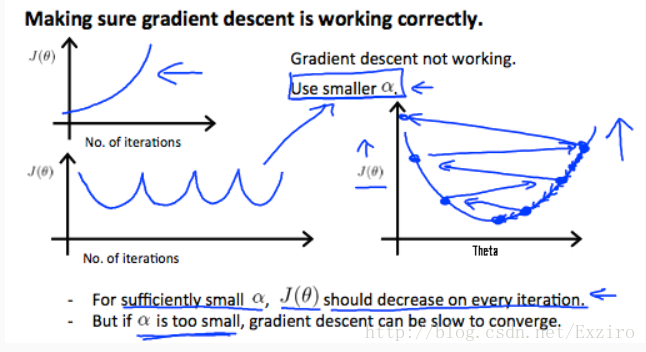
以上就是我的部分总结,望各位大佬们能够提出一些建议,谢谢。














 5453
5453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









