







快速排序的算法:
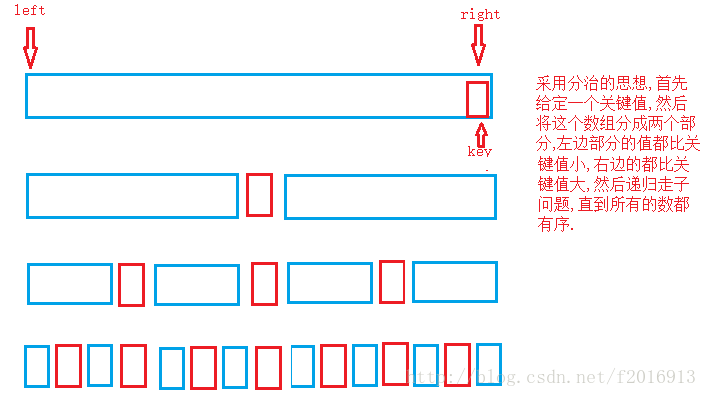
所谓的快速排序实际上用的是分治思想,将这个数组分成两个部分,左边部分的数据都比右边部分的数据要小,再按照此方法对子区间进行划分进行快速排序;
算法思想是:
1:开始时设置两个变量left,right,给定一个关键值key=a[right];
2:left向后移,找到第一个比key值大的数,否则继续向后走,
3:right向前移,找到第一个比key小的数,否则继续向前走;
4:判断是否满足条件left小于right,不满足则交换,否则重复步骤2和步骤3,直到left和right相遇,这样所有的数就有序;
递归法
void QuickSort(int*a, int left, int right)
{
if (left >= right)
return;
//小区间优化
if (right - left < 13)
{
InSertSort(a, right-left+1);
}
else
{
//int div = PartSort(a, left, right);//左右指针法
//int div = PartSort1(a, left, right);//挖坑法
int div = PartSort2(a, left, right);//前后指针
QuickSort(a, left, div - 1);//左区间
QuickSort(a, div + 1, right);//右区间
}
}方法一:左右指针法:
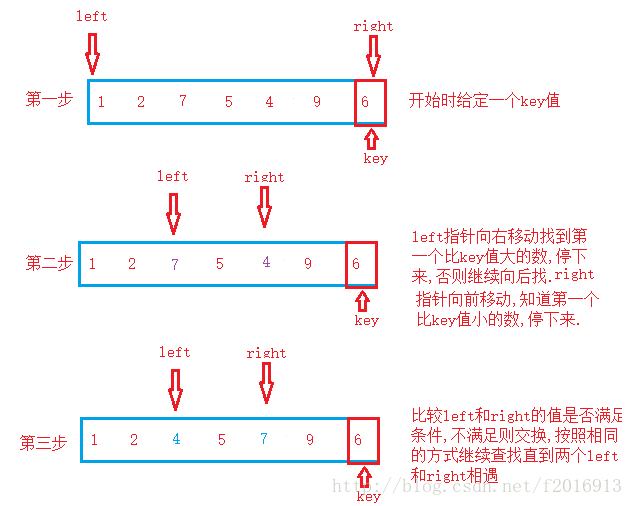
给定一个关键值key,可key值可以是数组的开始也可以是数组的结束,然后从头开始查找,找到比key值大的数,停下来否则继续向后找,然后从右边找比key小的数,如果找到就停下来,然后看是否满足昨变的值小于右边的值,不满足交换,,如果没有找到继续向前直到left和right相遇
我们举个栗子:
//部分排序(左右指针)
int PartSort(int *a, int left, int right)
{
assert(a);
int mid = GetMidIndex(a, left, right);
int key = a[right];//找到key的值(关键值)
int begin = left;
int end = right;
while (begin < end)
{
//找大
while (begin < end && a[begin] <= key)
{
++begin;
}
//找小
while (begin < end &&a[end] >= key)
{
--end;
}
//没有相遇
swap(a[begin], a[end]);
}
swap(a[begin], a[right]);
return begin;
}
这个有一个缺陷就是当key的值就是最大或者最小,,然后再余下的便利,这时的递归深度很深,排序的效率就会变的很慢,时间复杂度就是O(N^2);我们可以加上三数取中法就行优化
三数取中法:
与一般的快速排序方法不同,它并不是选择待排数组的第一个数作为中轴,而是选用待排数组最左边、最右边和最中间的三个元素的中间值作为中轴。这一改进对于原来的快速排序算法来说,主要有两点优势:
(1) 首先,它使得最坏情况发生的几率减小了。
(2) 其次,未改进的快速排序算法为了防止比较时数组越界,在最后要设置一个哨点。如果在分区排序时,中间的这个元素(也即中轴)是与最右边数过来第二个元素进行交换的话,那么就可以省略与这一哨点值的比较。
关于这一改进还有更进一步的改进,在继续的改进中不仅仅是为了选择更好的中轴才进行左中右三个元素的的比较,它同时将这三个数排好序后按照其顺序放回待排数组,这样就能够保证一个长度为n的待排数组在分区之后最长的子分区的长度为n-2,而不是原来的n-1。也可以在选取中轴值时,可以从由左中右三个中选取扩大到五个元素中或者更多元素中选取,一般的,会有(2t+1)平均分区法(median-of-(2t+1)。
int GetMidIndex(int *a, int left, int right)
{
assert(a);
int mid = left + (right - left) >> 1;
//三个数中找次大的数
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left]>a[right])//left>right
{
return right;
}
else
{
return left;
}
}
//left>mid
else
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[right] > a[left])
{
return left;
}
else
{
return right;
}
}
}
方法二:挖坑法
思路:先将最左边或者最右边为起始坑,然后保留坑中的值,然后从左边开始遍历,找到第一个比坑里面的值大的数就交换,也就是把大的数填坑,以前的位置就会形成新的坑,然后我们可在右边找比坑的值小的数入坑, 又会形成新的坑,这样不断遍历走子问题直到两个坑相遇.
算法思想和第一种类似只是把key值的换成坑,然后不断找新的值去填坑,直到相遇.
int PartSort1(int *a, int left, int right)
{
assert(a);
int key = a[right];//坑的值
while (left<right)
{
//左边找大
while (a[left]<key)
{
++left;
}
a[right] = a[left];//找到一个比key大的值放到坑里,形成新的坑
//右边找小
while (a[right]>=key)
{
--right;
}
a[left] = a[right];//找到一个比key小的值放到新坑里
}
a[left] = key;
return left;
}
方法三:前后指针法:
我们有两个指针prev和cur,开始到时候cur在最左边,prev在cur的前一个位置,给定一个key值,cur不断向后移找到一个比key值小的数,找到就停下来,然后prev++,判断cur和prev是否相等,不相等则交换,否则继续向后移动,
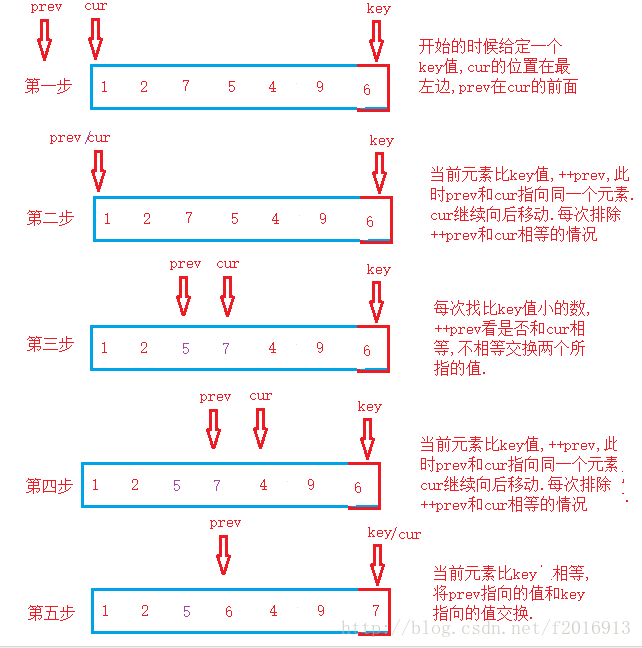
实现:
int PartSort2(int *a, int left, int right)
{
assert(a);
int cur = left;
int prev = left - 1;
int key = a[right];
//每一次当前的值比中间值小,cur先停下来,prrv向后移动,观察此时prev和cur的是否相等,不相等交换,相等则不作任何处理
while (cur<right)
{
if (a[cur] < key&&++prev != cur)
{
swap(a[cur], a[prev]);
}
++cur;
}
//cur和key指向同一个位置,将++prev所指向的值与key位置的值交换.
swap(a[++prev], a[right]);
return prev;
}
我们知道递归有缺陷就是当递归的深度很深时效率就会变得很慢,有的时候我们也会使用非递归.
方法四:非递归
void QuickSortNonR(int *a, int left, int right)
{
assert(a);
stack<int> s;
if (left < right)
{
s.push(right);
s.push(left);
while (!s.empty())
{
int begin = s.top();
s.pop();
int end = s.top();
s.pop();
//小区间优化
if (end - begin < 20)
{
InSertSort(a, end - begin + 1);
}
else
{
int div = PartSort2(a, begin, end);
if (begin < div - 1)
{
s.push(div - 1);
s.push(begin);
}
if (div + 1 < end)
{
s.push(end);
s.push(div + 1);
}
}
}
}
}总结:
1:普通的快速排序,可能会出现最坏的情况,就是当key值最大或者最小时,此时递归的深度就是O(N),时间复杂度就是O(N^2),这时候我们可以加上三数取中法进行优化,避免最坏的情况产生.
2:如果我们使用挖坑法,当区间很小时,仍然会开很多空间,这样就会造成空间的浪费,我们可以加上小区间优化,在小区间时可以使用插入排序
3:如果递归的深度很深时,我们也可以使用非递归.
总结我们发现快速排序的时间复杂度最坏是O(N^2),最好的情况是O(n^lg^N),一般在这里我们考虑最坏的情况而是最好的,因为和哈希表类似,加了很多优化,使它的变得很高效.














 6474
6474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









