







JOS LAB4 PartB
PartB主要讲述了fork的写时复制的实现,为了满足实现的要求,需要page_fault的实现,即页面异常处理。

这里主要实现几个系统调用函数,以供后面的fork实现调用。这些系统调用都比较简单。这里就看下 sys_exofork的实现。
sys_exofork这个函数只是fork函数的一个雏形,他的功能就是新建立一个进程,这个进程没有任何的页面映射,唯一的要求就是它的寄存器需要和父进程相同,并且进程的状态要设置为不可运行,即ENV_NOT_RUNNABLE。其他的要求就是父进程需要返回子进程的eid,而新建立的子进程需要返回0.
下面是sys_expfork的实现代码:
static envid_t sys_exofork(void)
{
struct Env* childEnv=0;
struct Env* parentEnv = curenv;
int r = env_alloc(&childEnv, parentEnv->env_id);
if(r < 0)
return r;
//init the childEnv
childEnv->env_tf = parentEnv->env_tf;
childEnv->env_status = ENV_NOT_RUNNABLE;
childEnv->env_tf.tf_regs.reg_eax = 0;
return childEnv->env_id;
} 寄存器和状态的设置都比较简单,就是父进程和子进程分别的返回值需要注意下。对于父进程来说,比较简单,就是直接return childEnv->env_id就可以了,对于子进程,需要返回0.这个就要回顾一下JOS的系统调用的具体过程了。JOS的系统调用,由于发生了栈的切换,所以函数的返回值是通过寄存器eax来传递的,换句话说,对于父进程而言,相当于curenv->env_tf.tf_regs.reg_eax = sys_exofork(),这个eax是父进程在内核态中用来存储用户态信息的表项中的eax,并不是在内核态中的父进程真正的CPU的寄存器。当父进程回到用户态的时候,CPU的寄存器eax会被赋值为进程表项中的存储的用户态eax,这个操作的过程就是上下文的切换操作,然后父进程的sys_exofork()的返回值就是子进程的id号码。
那对于子进程,只需要给新建立的子进程的进程表项里面的eax寄存器赋值为0,那么当子进程被调用时,他的返回值自然就是0了。要理解上面的内容,需要lab3里面的系统调用的相关知识,忘记了可以看看lab3的部分来复习下:http://blog.csdn.net/fang92/article/details/48418127
总结exofork这个操作,主要的功能的就是建立一个进程,然后把进程的进程表里面的eax赋值为0。这些都是父进程在内核态完成的,等到这些基本功能完成之后,就可以直接返回子进程的id号了。对于子进程,现在子进程是一个可执行的进程,如果系统开了时钟中断,则进程调用程序会调用子进程,子进程开始的指令位置和父进程调用exofork的位置相同,因为父进程在exofork操作的内核态中把父进程的寄存器(eip)复制给了子进程,所以exofork创建了子进程之后,子进程会从exofork之后的指令开始执行。So 子进程其实是因为时钟中断,进程调度的原因才能得到执行的机会,所以最先开始的是子进程还是父进程是不一定的,因为可能在exofork那条指令回来之后,父进程的时间片用完了,从而执行了进程调度函数,选择下一个执行的进程。而且父子进程具体的执行顺序应该还是和fork这个函数的操作有关,比如在fork函数里面直接执行进程调度函数………
所以一般说的fork会返回2次这个话有点不对,其实从实际上来分析,父进程返回了1次,剩下的的那个子进程是因为进程调度程序,它开始的指令就是fork的下一个指令,但是其实和fork并没有什么关系。因为子进程开始的指令就是fork的下一条指令,才会让fork看起来像返回了两次。
Copy-on-Write Fork
接下来就是要实现一个真正的写时复制的fork了。在实现fork之前,首先要看看页面异常的处理。因为真正的fork,在刚开始的时候,子进程是不复制父进程的页面里面的具体的内容的,子进程是和父进程共享页面映射的,换句话说,他们的相同的虚拟地址,暂时指向的是一样的物理地址。但是要注意,他们的内存空间是分开的。要做到这个,就需要以下的步骤:
1.当父进程fork新的子进程的时候,需要给子进程建立新的内存地址,其中子进程的地址映射从父进程复制过来。
2.父进程和子进程中,用户地址的页面都标记为只读。
3.在父进程或者子进程回到用户态后,如果对相关页面进行了写操作,这时由于页面是只读的,所以会进入页面异常,在页面异常处理中,判断出引起异常的页面是父子共同映射的页面,而且页面是因为被改为了只读才进入页面异常程序的,页面异常程序就会为进程新申请一个页面,并且复制只读页面里面的内容到新页面,然后改变进程的页面映射到新申请的页面。简单来说,操作系统为引发页面异常的进程新申请了一个物理页面,使发生页面异常的虚拟地址指向新的物理地址,从而达到两个进程的地址空间的真正的独立。
从上面可以看到,要实现写时复制的fork,首先就是要完成页面异常的程序。PartB的最开始的部分就是关于页面异常的相关内容。
update:11.25
快一个月没有看这个了,前段时间事情比较多,老板脑洞太大,读这个研,怎么偏偏我是地狱模式呢%>_<%
page_fault
在JOS里面,不考虑内核态的page fault, 只考虑用户态态的page fault,即只在内核态引发page fault。
和其他的中断函数不同,当引发page fault中断时,page fault的处理函数是在用户态中执行的,其处理函数也是在用户态时设置的,其中栈要换成异常栈。找了一张图,是整个page fault的执行过程,感觉蛮清晰的:
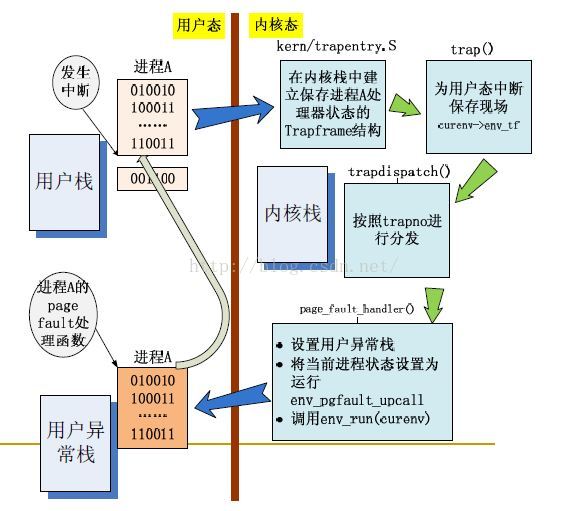
这张图片面熟了整个page fault的过程。首先,用户进程在用户态触发一个page fault,在内核态中,trapentry.s 和trap()函数保存用户进程的上下文内容,然后执行相应的trapdispatch()函数,具体的过程见图,然后执行page fault的处理函数。这是page fault的总体的一个执行方式,具体的看下面的。

exercise8,sys_env_set_pgfault_upcall()系统调用的实现,作用就是设置用户态的page fault处理函数。代码如下:
static intsys_env_set_pgfault_upcall(envid_t envid, void *func)
{
struct Env *e =0;
int r =0;
if((r = envid2env(envid, &e, 1)) < 0)
return r;
e->env_pgfault_upcall = func;
return 0;
} 代码比较简单,就是把一个函数指针赋值给e->env_fgfault_upcall。

接下来,就是完成在内核态里面的page fault的处理函数了(不是真正的page fault处理函数,处理函数是在用户态下的,内核态的处理函数只是类似于一个准备工作).
先给出相关的代码:
void page_fault_handler(struct Trapframe *tf)
{
uint32_t fault_va;
if(tf->tf_cs == GD_KT)
panic("page fault happens in the kern mode");
if(!curenv->env_pgfault_upcall){
// Destroy the environment that caused the fault.
cprintf("[%08x] user fault va %08x ip %08x\n",
curenv->env_id, fault_va, tf->tf_eip);
print_trapframe(tf);
env_destroy(curenv);
}
unsigned int newEsp=0;
struct UTrapframe UT;
//the Exception has not been built
if( tf->tf_esp < UXSTACKTOP-PGSIZE || tf->tf_esp >= UXSTACKTOP)
{
newEsp = UXSTACKTOP - sizeof(struct UTrapframe);
}
else
newEsp = tf->tf_esp - sizeof(struct UTrapframe) -8;
user_mem_assert(curenv, (void*)newEsp, 0, PTE_U|PTE_W|PTE_P);
UT.utf_err = tf->tf_err;
UT.utf_regs = tf->tf_regs;
UT.utf_eflags = tf->tf_eflags;
UT.utf_eip = tf->tf_eip;
UT.utf_esp = tf->tf_esp;
UT.utf_fault_va = fault_va;
user_mem_assert(curenv,(void*)newEsp, sizeof(struct UTrapframe),PTE_U|PTE_P|PTE_W );
memcpy((void*)newEsp, (&UT) ,sizeof(struct UTrapframe));
tf->tf_esp = newEsp;
tf->tf_eip = (uintptr_t)curenv->env_pgfault_upcall;
env_run(curenv);
} 分析上面的代码,在函数里面,新建了一个结构体UT,这个结构体UT保存部分用户进程的上下文信息,用于在页面错误处理程序之后返回原来的进程。
接下来,判断了用户进程的栈指针,由于假设在用户态时,会引发页错误,而页错误处理程序也是在用户态下的的,所以会有两种情况:1,在用户态进程中,引发了页错误;2,在页错误处理程序中引发了页错误。
两种情况下的栈基址是不同的。对于第一种情况下,栈基址就是异常栈的首地址。第二种情况,则类似于一般程序中的函数调用,此时异常栈中存在数据,所以,栈基址需要在原有数据的基础上往下走。而判断两种情况的方法,就是查看用户进程中的esp寄存器。当esp寄存器处于用户栈时,即使第一种情况,当esp处于异常栈时,则是第二种情况。
if( tf->tf_esp < UXSTACKTOP-PGSIZE || tf->tf_esp >= UXSTACKTOP)
newEsp = UXSTACKTOP - sizeof(struct UTrapframe);
else
newEsp = tf->tf_esp - sizeof(struct UTrapframe) -8;
user_mem_assert(curenv,(void*)newEsp, sizeof(struct UTrapframe),PTE_U|PTE_P|PTE_W );
memcpy((void*)newEsp, (&UT) ,sizeof(struct UTrapframe));
tf->tf_esp = newEsp; 这部分表示的就是上面的内容。可以看到,在原来的异常栈的基址的基础上,先把UT结构体复制到上去,然后赋值新的esp的变量。即整个异常栈的结构和下面这幅图是一样的。在这个过程中,UT结构体中包含了原来的用户进程的所有上下文信息,所以,可以直接根据这些信息,在异常处理程序结束之后,回到用户进程,:

再看上面部分的代码,可以看到,两种情况下,新的esp的起始地址还是不同的。这个在后面分析整个处理过程时,再具体分析。


直接先看接下来的两个练习,先给出代码:
.text
.globl _pgfault_upcall
_pgfault_upcall:
// Call the C page fault handler.
pushl %esp // function argument: pointer to UTF
movl _pgfault_handler, %eax
call *%eax
addl $4, %esp // pop function argument
// LAB 4: Your code here.
// trap-eip -> eax
movl 0x28(%esp), %eax
// trap-ebp-> ebx
movl 0x10(%esp), %ebx
// trap->esp -> ecx
movl 0x30(%esp), %ecx
movl %eax, -0x4(%ecx)
movl %ebx, -0x8(%ecx)
leal -0x8(%ecx), %ebp
movl 0x8(%esp), %edi
movl 0xc(%esp), %esi
movl 0x18(%esp),%ebx
movl 0x1c(%esp),%edx
movl 0x20(%esp),%ecx
movl 0x24(%esp),%eax
// Restore eflags from the stack.
leal 0x2c(%esp), %esp
popf
// Switch back to the adjusted trap-time stack.
leave
// Return to re-execute the instruction that faulted.
retvoid
set_pgfault_handler(void (*handler)(struct UTrapframe *utf))
{
int r;
if (_pgfault_handler == 0) {
// First time through!
// LAB 4: Your code here.
void* addr = (void*) (UXSTACKTOP-PGSIZE);
r=sys_page_alloc(thisenv->env_id, addr, PTE_W|PTE_U|PTE_P);
if( r < 0)
panic("No memory for the UxStack, the mistake is %d\n",r);
//panic("set_pgfault_handler not implemented");
}
// Save handler pointer for assembly to call.
_pgfault_handler = handler;
if(( r= sys_env_set_pgfault_upcall(sys_getenvid(), _pgfault_upcall))<0)
panic("sys_env_set_pgfault_upcall is not right %d\n", r);
}感觉这个耗得时间有点太长了,先写到这里,等以后再来补充这部分的东西和fork还有下面的进程通信部分。
上面的page_fault处理函数从处理函数跳转到用户进程的主要思想是采用了一般程序里面的函数跳转时,用户栈的跳转方法。即用ebp和esp两个寄存器来配合,达到跳转的目的。可以看看:http://blog.csdn.net/fang92/article/details/46494665
下次在详细的写这些内容吧。现在还是先把这个课程给搞定吧!















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









