







参考自 :
http://www.jianshu.com/p/aa6f3a366727
http://www.powerxing.com/install-hadoop/
我利用两台机器搭建测试。
为了解决hdfs地址绑定127.0.0.1,修改和hostname。
分别修改/etc/sysconfig/network;/etc/hosts;hostname testdata;
重新登录,搞定。
testdata
testdesk1.下载最新的hadoop :http://hadoop.apache.org/releases.html
hadoop-2.7.3.tar.gz
2.下载最新的spark:https://spark.apache.org/downloads.html
这里下载的是spark-2.2.0-bin-hadoop2.7.tgz
3.搭建java环境 && 搭建scala环境 (搭建配置方法十分相似)。分别校验java -version ;scala -version
4.在两台机器上分别创建hadoop用户并授权(ubuntu和centos稍微不同),然后两台机器设置互信(当前用户目录下的.ssh下各自执行ssh-keygen -t rsa ;分别复制id_rsa.pub文件内容添加到其他机器的authorized_keys里面 ,ok。如果目录或者文件不存在手动创建。)。为了简单,直接解压hadoop ,spark到/home/hadoop目录下。
5.进入解压的hadoop目录下。cd /home/hadoop/hadoop-2.7.3;
配置hadoop 的7个文件。cd etc/hadoop;(最新版本的配置请参考官网)。
1.在hadoop-env.sh中配置JAVA_HOME
2.在yarn-env.sh中配置JAVA_HOME
3.在slaves中配置slave节点的ip或者host,
testdesk(172.16.10.21)
4.core-site.xml
...
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.16.10.20:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
</property>
</configuration>
5.hdfs-site.xml
...
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>172.16.10.20:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
6.修改mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7.修改yarn-site.xml
...
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>172.16.10.20:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>172.16.10.20:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>172.16.10.20:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>172.16.10.20:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>172.16.10.20:8088</value>
</property>
</configuration>把这些文件原封不动地发一份到从机器。
6.配置ok,启动 hadoop
cd /home/hadoop/hadoop-2.7.3;
先格式化 namenode
bin/hadoop namenode -format成功之后
启动hdfs sbin/start-dfs.sh
关闭使用 sbin/stop-dfs.sh输入 jps 命令
master 可以看到 NameNode和 SecondaryNameNode。
slaves 可以看到 DataNode
成功之后
启动yarn sbin/start-yarn.sh
关闭使用 sbin/stop-yarn.sh
输入 jps 命令
master 可以看到 ResourceManager
slaves 可以看到 NodeManager
分别在浏览器输入 testdataIp:50070 testdataIP:8088 查看
7.配置spark ( 根据自己的环境各异 )
cd /home/hadoop/spark-2.2.0-bin-hadoop2.7;
cd conf;
cp spark-env.sh.template spark-env.sh;
修改spark-env.sh
export SPARK_HOME=/home/hadoop/spark-2.2.0-bin-hadoop2.7
export SCALA_HOME=/usr/local/scala-2.12.2
export JAVA_HOME=/usr/local/jdk1.8.0
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$YARN_HOME/etc/hadoop
export SPARK_MASTER_IP=172.16.10.20
SPARK_LOCAL_DIRS=/home/hadoop/spark-2.2.0-bin-hadoop2.7
SPARK_DRIVER_MEMORY=100m
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native将配置原封不动发一份到slaves 机器;
启动 cd /home/hadoop/spark-2.2.0-bin-hadoop2.7;
sbin/start-all.sh;成功启动输入 jps
master 可以看到 Master
slaves 可以看到 Worker
浏览器输入testdataIp:8080
能看到 Workers 下面配置的slaves 机器及成功。
8.测试spark
ideal 集成scala 只需要添加一个插件即可,自行百度即可解决。
简单的scala代码如下
摘自 http://blog.csdn.net/trigl/article/details/70256914
import org.apache.spark.{SparkConf, SparkContext}
/**
* Copyright (c) 2017/7/27 by ShaoYongJun
* Company: Zoomy
*/
object SparkDemo {
// args:/test/test.log
def main(args: Array[String]) {
// 设置Spark的序列化方式
System.setProperty("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 初始化Spark
val sparkConf = new SparkConf().setAppName("CountDemo")
val sc = new SparkContext(sparkConf)
// 读取文件
val rdd = sc.textFile(args(0))
println(args(0) + "的行数为:" + rdd.count())
sc.stop()
}
}然后按照流程流程打包发布,测试。
我本地的测试机器配置比较低,测试一直报错,网上搜索得知是配置不够的原因,在测试的时候调整即可。
为了简单,上传好jar (我的jar包是 spark.jar )之后的测试的代码如下
bin/spark-submit --master spark://testdata.localdomain:7077 --executor-memory 512m --driver-memory 512m --executor-cores 2 --class com.SparkDemo ./spark.jar /README.md 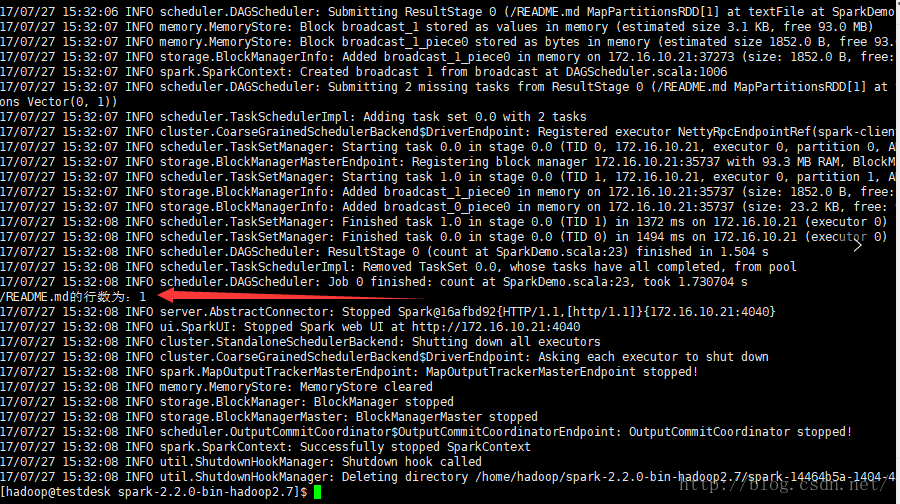
SparkSession 类替换了 Spark2.0 中的 SparkContext 和 SQLContext
,并为Spark集群提供了 "唯一的入口点"。
So I could do like this
val sb=spark.read.parquet("/apps-data/event_log/event_log.20170827.parquet");
sb.registerTempTable("table");
spark.sql("select * from table limit 3").show();













 1616
1616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









