










简介
通过合成和自动微分,网络同时定义了一个函数和其对应的梯度。通过合成各层的输出来计算这个函数,来执行给定的任务,并通过合成各层的后向传播过程来计算来自损失函数的梯度,从而学习任务。Caffe模型是端到端的机器学习引擎。
准确的说,Net是由一系列层组成的有向无环(DAG)计算图,Caffe保留了计算图中所有的中间值以确保前向和反向迭代的准确性。一个典型的Net开始于data layer——从磁盘中加载数据,终止于loss layer——计算如分类和重构这些任务的目标函数。 Net由一系列层和它们之间的相互连接构成,用的是一种文本建模语言。
例如
name: "LeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 64 dim: 1 dim: 28 dim: 28 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
......结构
一个Net由多个Layer组成。一个典型的网络从data layer(从磁盘中载入数据)出发到loss layer结束。
/**
* @brief Connects Layer%s together into a directed acyclic graph (DAG)
* specified by a NetParameter.
*
* TODO(dox): more thorough description.
*/
template <typename Dtype>
class Net {
public:
...
/// @brief Initialize a network with a NetParameter.
void Init(const NetParameter& param);
...
const vector<Blob<Dtype>*>& Forward(const vector<Blob<Dtype>* > & bottom,
Dtype* loss = NULL);
...
/**
* The network backward should take no input and output, since it solely
* computes the gradient w.r.t the parameters, and the data has already been
* provided during the forward pass.
*/
void Backward();
...
Dtype ForwardBackward(const vector<Blob<Dtype>* > & bottom) {
Dtype loss;
Forward(bottom, &loss);
Backward();
return loss;
}
...
protected:
...
/// @brief The network name
string name_;
/// @brief The phase: TRAIN or TEST
Phase phase_;
/// @brief Individual layers in the net
vector<shared_ptr<Layer<Dtype> > > layers_;
/// @brief the blobs storing intermediate results between the layer.
vector<shared_ptr<Blob<Dtype> > > blobs_;
vector<vector<Blob<Dtype>*> > bottom_vecs_;
vector<vector<Blob<Dtype>*> > top_vecs_;
...
/// The root net that actually holds the shared layers in data parallelism
const Net* const root_net_;
};
} // namespace caffe说明:
Init中,通过创建blob和layer搭建了整个网络框架,以及调用各层的SetUp函数。
blobs_存放这每一层产生的blobs的中间结果,bottom_vecs_存放每一层的bottom blobs,top_vecs_存放每一层的top blobs.
Net的类中的关键函数简单剖析:
- ForwardBackward:按顺序调用了Forward和Backward。
- ForwardFromTo(int start, int end):执行从start层到end层的前向传递,采用简单的for循环调用。
- BackwardFromTo(int start, int end):和前面的ForwardFromTo函数类似,调用从start层到end层的反向传递。
- ToProto函数完成网络的序列化到文件,循环调用了每个层的ToProto函数。
下面介绍几个比较关键的函数的运行过程。
Init
Net的初始化函数。Init主要包含的步骤有
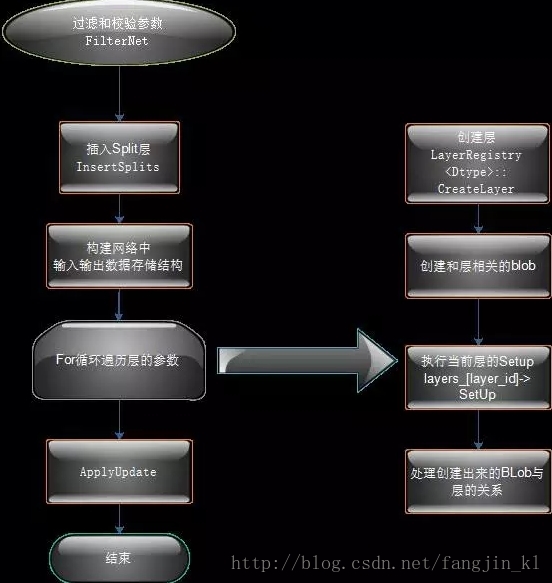
(1). FilterNet
此函数的作用就是模型参数文件(*.prototxt)中的不符合规则的层去掉。例如:在caffe的examples/mnist中的lenet网络中,如果只是用于网络的前向,则需要将包含train的数据层去掉.
例如一个Net网络结构部分如下
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "number_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "number_test_lmdb"
batch_size: 100
backend: LMDB
}
}
...在NetParameter的定义中有一项
// The current "state" of the network, including the phase, level, and stage.
// Some layers may be included/excluded depending on this state and the states
// specified in the layers' include and exclude fields.
optional NetState state = 6;其中
message NetState {
optional Phase phase = 1 [default = TEST];
optional int32 level = 2 [default = 0];
repeated string stage = 3;
}简单的理解就是,每一层可以设定一个条件,如果是include,则满足条件的层就包含进去,也可以设定为exclude,则满足条件的层就会剔除。如LeNet中,
include {
phase: TRAIN
}这句话的意思就是如果phase是TRAIN,则这一层符合条件需要保留。如果phase是TEST,则这一层去掉。
FilterNet这个函数就是把不符合条件的层去掉。
(2). InsertSplits
此函数作用是,对于底层一个输出blob对应多个上层的情况,则要在加入分裂层,形成新的网络。这么做的主要原因是多个层反传给该blob的梯度需要累加。
例如:LeNet网络中的数据层的top label blob对应两个输入层,分别是accuracy层和loss层,那么需要在数据层在插入一层。如下图:
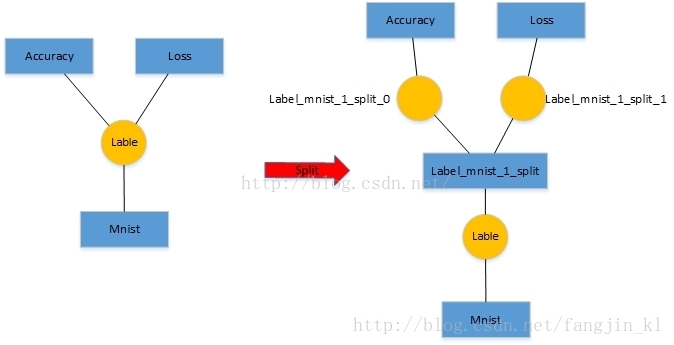
数据层之上插入了一个新的层,label_mnist_1_split层,为该层的创建两个top blob分别为,Label_mnist_1_split_0和Label_mnist_1_split_1。
新增的这一层的属性可以从代码里看出来,增加了一个Split层。
void ConfigureSplitLayer(const string& layer_name, const string& blob_name,
const int blob_idx, const int split_count, const float loss_weight,
LayerParameter* split_layer_param) {
split_layer_param->Clear();
split_layer_param->add_bottom(blob_name);
split_layer_param->set_name(SplitLayerName(layer_name, blob_name, blob_idx));
split_layer_param->set_type("Split");
for (int k = 0; k < split_count; ++k) {
split_layer_param->add_top(
SplitBlobName(layer_name, blob_name, blob_idx, k));
if (loss_weight) {
if (k == 0) {
split_layer_param->add_loss_weight(loss_weight);
} else {
split_layer_param->add_loss_weight(0);
}
}
}
}(3). 其他
步骤:
1. 调用InsertSplits()函数从in_param读入新网络到param
2. 定义name_,blob_name_to_idx,available_blobs,num_layers
3. param.input_size()返回输入层blob的个数;
param.input(i)表示第i个blob的名字;
param.layers_size()返回网络的层数。
4. 对每一个输入层的blob:
产生一块和当前blob一样大的空间 e.g. imput_dim=[12 55 66 39 20 24 48 64]表示第一个blob的四个维数为 12 55 66 39,第二个为 20 24 48 64 接着blob_pointer指向这块空间
blob_pointer压到blobs_中 vector<shared_ptr<Blob<Dtype>>> blobs_
blob_name压到blob_names_中 vector<string> blob_names_
param.force_backward()压到blob_need_backward_中vector<bool> blob_need_backward_
i 压到 net_input_blob_indices_中 net_input_blob_indices_ -> vector
blob_pointer.get() 压到 net_input_blobs_中
注意与blobs_的区别
vector<shared_ptr<Blob<Dtype>>> blobs_
vector<Blob<Dtype>*> net_input_blobs_
shared_ptr类型的参数调用.get()则得到Blob*类型
map<string, int> blob_name_to_idx
初始化为输入层的每个blob的名字 set<string> available_blobs
计算所需内存 memory_used += blob_pointer->count()
5. 存每一层的输入blob指针 vector<vector<Blob<Dtype>*> > bottom_vecs_
存每一层输入(bottom)的id vector<vector<int> > bottom_id_vecs_
存每一层输出(top)的blob vector<vector<Blob<Dtype>*> > top_vecs_
用网络的层数param.layers_size()去初始化上面四个变量
vector<vector<int> > top_id_vecs_
6. 对第i层(很大的一个for循环):
param.layers(i)返回的是关于第当前层的参数:
layer_param = param.layers(i)
把当前层的参数转换为shared_ptr<Layer<Dtype>>,并压入到layers_中
把当前层的名字压入到layer_names_:vector<string> layer_names_
判断当前层是否需要反馈 need_backward = param.force_backward()
下面开始产生当前层:分为处理bottom的blob和top的blob两个步骤
对第j个bottom的blob:
layer_param.bottom_size()存的是当前层的输入blob数量
layer_param.bottom(j)存的是第j个输入blob的名字
读取当前blob的id,其中blob_name_to_idx在输入层初始化过了
blob_name_to_idx[blob_name] = i
输出当前blob的名字
存入第j个输入blob的指针bottom_vecs_[i].push_back(blobs_[blob_id].get())
存入第j个输入blob的id bottom_id_vecs_[i].push_back(blob_id)
更新need_backward
从available_blobs中删除第j个blob的名字
对第j个top的blob:
layer_param.top_size()存的是当前层的输出blob数量
layer_param.top(j)存的是第j个输出blob的名字
判断是否进行同址计算
输出当前blob的名字
定义一块新的blob空间,用blob_pointer指向这块空间
把这个指针存入到blobs_中
把blob_name、force_backward、idx存入对应的容器中
向available_blobs插入当前blob的名字
top_vecs_[i]对于第i层,插入当前blob的指针
top_id_vecs_[i]对于第i层,插入当前blob的id
输出当前层位于top的blob的信息
计算所需内存
判断当前层i是否需要backward
7. 所有名字在available_blobs中的blob为当前层的输出blob,存入net_output_blobs_中
8. 建立每个blob的name和index的对应关系map:blob_names_index_
9. 建立每个层的name和index的对应关系map:layer_names_index_
10. 调用GetLearningRateAndWeightDecay函数ForwardFromTo
前向过程,就是把每一层的loss加起来。
Dtype Net<Dtype>::ForwardFromTo(int start, int end) {
CHECK_GE(start, 0);
CHECK_LT(end, layers_.size());
Dtype loss = 0;
for (int i = start; i <= end; ++i) {
// LOG(ERROR) << "Forwarding " << layer_names_[i];
Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
loss += layer_loss;
if (debug_info_) { ForwardDebugInfo(i); }
}
return loss;
}BackwardFromTo
反向过程,把具有反向传播的层进行反向传播运算。
template <typename Dtype>
void Net<Dtype>::BackwardFromTo(int start, int end) {
CHECK_GE(end, 0);
CHECK_LT(start, layers_.size());
for (int i = start; i >= end; --i) {
if (layer_need_backward_[i]) {
layers_[i]->Backward(
top_vecs_[i], bottom_need_backward_[i], bottom_vecs_[i]);
if (debug_info_) { BackwardDebugInfo(i); }
}
}
}Update
更新,每一层的权重分别更新。
template <typename Dtype>
void Net<Dtype>::Update() {
for (int i = 0; i < learnable_params_.size(); ++i) {
learnable_params_[i]->Update();
}
}













 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









