





Kryo作为一个优秀的Java序列化方案,在网上能找到不少测评,但未见系统的中文入门或说明文档。官方文档是最好的学习文档。虽然英文不差,但啃下来毕竟没母语来的舒服。这里抽出时间做些翻译,以方便大家查阅。为阅读流畅,文中选择性的未翻译某些专业词汇,如 buffer、scheme等, 并在双尖括号中给出了译者注释,形如 << 注释... >> 。如遇到逻辑错误、阅读不通等,请参阅原文文档,并感谢您的指正。
翻译的源官方文档更新于2017年5月,本文初次翻译于2017年5月底。
官方文档地址:
https://github.com/EsotericSoftware/kryo/blob/master/README.md
=============================以下为翻译正文=============================

Kryo是一种快速高效的Java对象图(Object graph)序列化框架。 该项目的目标是速度、效率和易于使用的API。 当对象需要持久化时,无论是用于文件、数据库还是通过网络,该项目都很有用。<<译者注:Object graph >>
Kryo还可以执行自动深层浅层的复制/克隆。这是从对象直接复制到对象,而不是object-> bytes-> object。
本文档适用于 Kryo v2.0 版本。 请参阅v1.x的 V1Documentation 。
如果您计划使用 Kryo 进行网络通信, KryoNet 项目对您可能会有帮助。
Content
- New in release 4.0.0(版本4.0.0中的新东东)
- Versioning Semantics, Upgrading (版本控制语义,升级)
- Installation(安装)
- Integration with Maven(与maven集成)
- Using Kryo without Maven(无maven的使用)
- Quickstart(快速开始)
- IO(IO)
- Unsafe-based IO(不安全IO)
- Serializers(序列化器)
- Registration(注册)
- Default serializers(默认序列化器)
- FieldSerializer
- KryoSerializable
- Class fields annotations(类字段注解)
- Java Serialization(Java序列化)
- Reading and writing(读与写)
- References(引用)
- Object creation(对象创建)
- Copying/cloning(复制 / 克隆)
- Context(上下文)
- Compression and encryption(压缩与加密)
- Chunked encoding(分块编码)
- Compatibility(兼容性)
- Interoperability(互通性)
- Stack size(栈大小)
- Threading(线程)
- Pooling Kryo instances(池化Kryo实例)
- Logging(日志)
- Scala(Scala)
- Objective-C(Objective-C)
- Benchmarks(基准测试)
- Projects using Kryo(使用Kryo的项目)
- Contact / Mailing list(联系 / 邮件组)
New in release 4.0.0(版本4.0.0中的新东东)
版本4.0.0为稳定性和性能带来了几项新功能和改进。以下是您应留意的一些亮点(此外,您还应仔细的研究变更日志并测试升级)。
- BREAKING(data):现在,通用处理更加强大,之前对于小数据的优化功能(但是增加了序列化时间)现在是可选的,默认未启用。
重要提示:此改变会破坏 FieldSerializer 对于通用字段的序列化格式,因此使用 Kryo 3 和 FieldSerializer 序列化的通用类默认不能使用 Kryo 4 进行反序列化。为了反序列化 Kryo 3 序列化过的普通类数据,你必须设置 kryo.getFieldSerializerConfig().setOptimizedGenerics(true);! 您需要在各种案例中,测试序列化/反序列化的升级工作。
- BREAKING(source/binary):protected Kryo.isClousre 被重命名为 Kryo.isClosure,泛型被移动到了别的包,不再作为公共api的一部分。
- 从 Kryo 4 起,公开的api减少了。由于java不允许细粒度地设置可见性,一些是 public 但不是公共 api 的部分类现在标有"INTERNAL API"。
- Kryo 4 为 Java 8 的 java.time.* 和 Optional.* 添加了序列化器(serializers)。
- 目前,我们为不同二进制格式的序列化兼容性和默认序列化器的每个改变都做了测试。
- 在这里感谢其他贡献者所做的更多其他改进和修复!
详细信息请参阅发布说明。
Versionning Semantics, Upgrading (版本控制语义,升级)
- 如果序列化兼容性被破坏了(之前版本的序列化数据不能使用新版本进行反序列化),我们会增加主版本号
- 如果文档公开api的二进制或源码兼容性被破坏,我们会增加次版本号
重定义规则 1.): 如果任何底层二进制格式被更改(参见 IO 和 Unsafe-based IO)或者常用序列化器生成的数据被改变了(例如一些默认的序列化器)。
重定义规则 2.): 由于java访问修饰符的限制,技术 api 比语义 api ( documented on this page ) 的作用域更广了。因此,在没有用户受到影响的情况下,技术上的二进制兼容性可能会被破坏。
<<译者注: 重定义规则 即 给出了规则1 和 规则2 的另一种表述>>
请牢记,序列化库的任何一次升级都是重大事件。升级 kryo 时,请检查升级带来的所有改变,并用您的数据结构和环境设置进行彻底的测试。
我们尽量使升级过程简易并安全:
- 在开发阶段,我们测试不同二进制格式和默认序列化器的兼容性
- 在开发阶段,我们采用 clirr 跟踪二进制和源码兼容性
- 对于每个版本,我们提供 ChangeLog,包括一个二进制和源码序列化兼容性的报告(我们使用japi-compliance-checker 来提供此报告)
Installation(安装)
Kryo JAR 可在发布页面和 Maven Central 上找到。 Kryo 的最新快照,包括 master 的快照构建,都在 Sonatype Repository 中。
Integration with Maven(与maven集成)
要使用Kryo的官方版本,请在 pom.xml 中使用以下代码段
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>4.0.0</version>
</dependency>
如果您因为在类路径中使用了不同版本的 asm 而遇到问题,可以使用包含这个 asm 版本的 kryo-shaded jar,并将其重新放置在不同的包中:
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo-shaded</artifactId>
<version>4.0.0</version>
</dependency>
如果要测试 Kryo 的最新快照,请在 pom.xml 中使用以下代码片段
<repository>
<id>sonatype-snapshots</id>
<name>sonatype snapshots repo</name>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
</repository>
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>4.0.1-SNAPSHOT</version>
</dependency>
Using Kryo without Maven(无maven的使用)
如果您使用没有 Maven 的 Kryo,请注意 Kryo jar 文件有几个外部依赖关系,它们的JAR也需要添加到类路径中。这些依赖关系是 MinLog logging library 和 Objenesis library。
Quickstart(快速开始)
向上翻页以查看类库的使用:
Kryo kryo = new Kryo();
// ...
Output output = new Output(new FileOutputStream("file.bin"));
SomeClass someObject = ...
kryo.writeObject(output, someObject);
output.close();
// ...
Input input = new Input(new FileInputStream("file.bin"));
SomeClass someObject = kryo.readObject(input, SomeClass.class);
input.close();
Kryo 类执行序列化。 输出和输入类处理缓冲字节,并可选地刷新到流(stream)。
本文档的其余部分详细介绍了它的工作原理和库的高级用法。
IO
Output 类是将数据写入字节数组 buffer 的 OutputStream。如果需要字节数组,则可以直接获取和使用该 buffer 。如果已经给定了OutputStream,当 buffer 满时,它将刷新 bytes 到 stream。Output有许多方法可以有效地将基本类型和字符串写为 bytes 。它提供类似于DataOutputStream,BufferedOutputStream,FilterOutputStream 和 ByteArrayOutputStream 类的功能。
在写入 OutputStream 时 buffer 后,请确保调用 flush() 或 close(),以便将缓冲的字节写入底层流。
Input 类是从字节数组缓冲区读取数据的 InputStream 类。如果需要从字节数组中读取,可以直接设置该缓冲区 (buffer) 。如果给定了InputStream,当缓冲区用尽时,它将从流中填充缓冲区。Input 有许多方法可以高效地从 bytes 读取基本类型和字符串。它提供类似于DataInputStream,BufferedInputStream,FilterInputStream 和 ByteArrayInputStream 类的功能。
如果要读写字节数组 (bytes)以外的对象,只需提供相应的 InputStream 或 OutputStream 即可。
Unsafe-based IO(不安全IO)
Kryo 提供了额外的基于 sun.misc.Unsafe 的 UnsafeInput,UnsafeOutput IO 类。因为他们来源于 Kryo 的 Input 和 Output 类,所以可以在支持sun.misc.Unsafe 的平台上进行替换。
当需要从直接内存 ByteBuffers 或非堆内存中进行序列化或反序列化,可用为其定制的专用类 UnsafeMemoryInput 和 UnsafeMemoryOutput,而不必使用通常的 Input 和 Output 类。
基于应用程序的具体情况,使用 Unsafe-based IO 会显着地性能提升(有时可达一个数量级)。特别地,将大型原始数组作为对象的一部分进行序列化时,这种方式会有很大的帮助。
**关于使用 Unsafe-based IO 的免责声明**
当涉及序列化数据的二进制格式时,不保证 Unsafe-based IO 与 Kryo 的输入和输出流完全兼容。
这意味着 Unsafe-based IO 的输出流只能被 Unsafe-based IO 的输入流读取,而不能由通常的输入流读取。反之亦然,普通的输出流产生的数据不能被 Unsafe-based IO 的输入流正确读取。
只要序列化和反序列化都采用 Unsafe IO 流,并且都在相同的处理器架构(更准确地说是,整数和浮点类型的字节顺序和内部表示相同)上执行,就能保证(should be)数据安全。
在 X86 架构上对 Unsafe IO 进行过全面的测试。其他的处理器架构上没有以相同的程度进行测试。例如,我们有收到过 SPARC 平台上的一些错误报告。
Serializers(序列化)
public class ColorSerializer extends Serializer<Color> {
public void write (Kryo kryo, Output output, Color object) {
output.writeInt(object.getRGB());
}
public Color read (Kryo kryo, Input input, Class<Color> type) {
return new Color(input.readInt(), true);
}
}
Serializer 有两种可以实现的方法。 write() 将该对象写入字节 (bytes)。 read() 创建对象的新实例,并用输入数据填充对象。
Kryo 实例可用于写入和读取嵌套对象。如果 Kryo 用于读取 read() 中的嵌套对象,且如果嵌套对象可以引用父对象,则必须先调用 kryo.reference() 引用父对象。如果嵌套对象不能引用父对象,或 Kryo 不被用于嵌套对象,或者没有使用引用,则没有必要调用 kryo.reference() 。如果嵌套对象可以使用相同的serializer,那么 serializer 必须是可重入的。
代码不应该直接使用 serializers,而应该使用 Kryo 的读写方法。这将使 Kryo 来协调序列化并处理诸如引用和空对象的特征。
默认情况下,serializers 不需要处理为空的对象。 Kryo 框架将根据需要写一个字节,以表示 null 或非 null。如果一个 serializers 想要更高效地自己来处理 nulls,可以设置 Serializer#setAcceptsNull(true)。这个设置也可以在已知类型的所有实例永不为空时,来避免写入空标识字节。
Register(注册)
当Kryo写出一个对象的实例时,首先可能需要写出一些标识对象类的东西。默认情况下,写入完整类名,然后写入该对象的字节。后续出现的同一类对象图的对象用变长的int来写(using a variable length int)。写类的名字有点低效,所以类可以事先注册:
Kryo kryo = new Kryo();
kryo.register(SomeClass.class);
// ...
Output output = ...
SomeClass someObject = ...
kryo.writeObject(output, someObject);
这里,SomeClass 注册到了 Kryo,它将该类与一个 int 型的 ID 相关联。当 Kryo 写出 SomeClass 的一个实例时,它会写出这个 int ID。这比写出类名更有效。在反序列化期间,注册的类必须具有序列化期间相同的 ID 。上面展示的注册方法分配下一个可用的最小整数 ID,这意味着类被注册的顺序十分重要。注册时也可以明确指定特定 ID,这样的话注册顺序就不重要了:
Kryo kryo = new Kryo();
kryo.register(SomeClass.class, 10);
kryo.register(AnotherClass.class, 11);
kryo.register(YetAnotherClass.class, 12);
当 IDs 是小的正整数时最有效。负数不能有效地序列化。 -1 和 -2 是保留值。<<译者注:-1 和-2 有其他含义>>
可以混合使用注册和未注册的类。默认使用 ID 0-9 注册所有基本类型,基本类包装器,String 和 void。所以要小心此范围内的注册覆盖的情况。
当 Kryo#setRegistrationRequired 设置为true,可在遇到任何未注册的类时抛出异常。这能阻止应用程序使用类名字符串来序列化。
如果使用未注册的类,则应考虑使用较短的包名。
Default serializers(默认序列化器)
写入类标识符后,Kryo使用一个序列化器(serializer) 来写入对象的字节。当类被注册后,serializer 实例就能被确定了:
Kryo kryo = new Kryo();
kryo.register(SomeClass.class, new SomeSerializer());
kryo.register(AnotherClass.class, new AnotherSerializer());
如果一个类未注册或没有指定序列化器,则会自动从映射了类和序列化器的“ 默认序列化器 (default serializers)”列表中选择一个序列化器。以下类默认设置过序列化器:
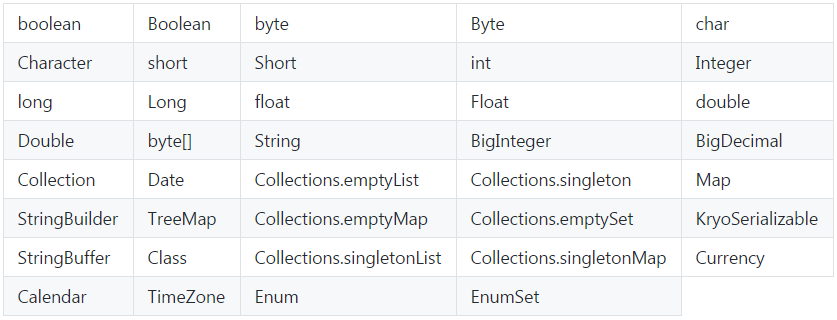
可以另外添加其他的默认序列化器:
Kryo kryo = new Kryo();
kryo.addDefaultSerializer(SomeClass.class, SomeSerializer.class);
// ...
Output output = ...
SomeClass someObject = ...
kryo.writeObject(output, someObject);
也可以使用 DefaultSerializer 注解:
@DefaultSerializer(SomeClassSerializer.class)
public class SomeClass {
// ...
}
如果类没有匹配默认序列化器,那么默认情况下会使用 FieldSerializer 。这也能改变:
Kryo kryo = new Kryo();
kryo.setDefaultSerializer(AnotherGenericSerializer.class);一些序列化器允许提供额外的信息,以减少输出字节数:
Kryo kryo = new Kryo();
FieldSerializer someClassSerializer = new FieldSerializer(kryo, SomeClass.class);
CollectionSerializer listSerializer = new CollectionSerializer();
listSerializer.setElementClass(String.class, kryo.getSerializer(String.class));
listSerializer.setElementsCanBeNull(false);
someClassSerializer.getField("list").setClass(LinkedList.class, listSerializer);
kryo.register(SomeClass.class, someClassSerializer);
// ...
SomeClass someObject = ...
someObject.list = new LinkedList();
someObject.list.add("thishitis");
someObject.list.add("bananas");
kryo.writeObject(output, someObject);
在这个例子中,FieldSerializer 用于 SomeClass 的序列化过程。因为配置了 FieldSerializer,所以“ list ”字段将始终为 LinkedList,并会使用指定的 CollectionSerializer。 因为配置了 CollectionSerializer,因此每个元素将是一个String,且都不为 null。这会使序列化过程更有效率。这种情况下,列表中每个元素节省了2到3个字节。
FieldSerializer
默认情况下,大多数类最终会使用 FieldSerializer。 它本质上是自动化的处理了手动的序列化过程。 FieldSerializer 会被直接分配给对象的字段。 如果这些字段是 public,protected,或默认的访问权限(package private),且不是final的,将采用字节码生成技术(bytecode generation)以求速度(参见 ReflectASM)。对于私有字段,使用 setAccessible 和缓存反射技术,速度也不慢。
也提供了其他通用的序列化器,如 BeanSerializer,TaggedFieldSerializer,CompatibleFieldSerializer 和 VersionFieldSerializer。更多的序列化器可在 github 和 kryo-serializer 上找到。
KryoSerializable
虽然 FieldSerializer 是大多数类的理想选择,但类也可以方便地进行自己的序列化。 这需要实现 KryoSerializable 接口(类似于 JDK 中的java.io.Externalizable 接口)。
public class SomeClass implements KryoSerializable {
// ...
public void write (Kryo kryo, Output output) {
// ...
}
public void read (Kryo kryo, Input input) {
// ...
}
}
Using standard Java Serialization
虽然非常罕见,但有一些类不能被 Kryo 序列化。 在这种情况下,可以使用 Kryo 的 JavaSerializer 提供后备解决方案,并使用标准Java序列化。只要对象能被Java序列化,就能采用这种方案。虽然这种方案与通常的 Java 序列化一样低效,但至少能够完成序列化工作。 当然,在这种方案中,正如通常的 Java 序列化所要求的那样,你的类需要实现 Serializable 或 Externalizable 接口。
当您的类实现了 Java 的 Serializable 接口,那么您就能使用 Kryo 专用的 JavaSerializer 序列化器:
kryo.register(SomeClass.class, new JavaSerializer());
如果您的类实现了Java的 Externalizable 接口,那么您就能使用 Kryo 专用的 ExternalizableSerializer 序列化器:
kryo.register(SomeClass.class, new ExternalizableSerializer());
Class fields annotations(类字段注解)
为此,Kryo 提供了一组注解。 @Bind 可用于任何字段,@CollectionBind 用于类型为集合(collection)的字段,@MapBind 用于类型为 map 的字段:
public class SomeClass {
// Use a StringSerializer for this field
@Bind(StringSerializer.class)
Object stringField;
// Use a MapSerializer for this field. Keys should be serialized
// using a StringSerializer, whereas values should be serialized
// using IntArraySerializer
@BindMap(
valueSerializer = IntArraySerializer.class,
keySerializer = StringSerializer.class,
valueClass = int[].class,
keyClass = String.class,
keysCanBeNull = false)
Map map;
// Use a CollectionSerializer for this field. Elements should be serialized
// using LongArraySerializer
@BindCollection(
elementSerializer = LongArraySerializer.class,
elementClass = long[].class,
elementsCanBeNull = false)
Collection collection;
// ...
}
Reading and writing(读与写)
Kryo有三组读写对象的方法。
如果不知道对象的具体类,且对象可以为null:
kryo.writeClassAndObject(output, object);
// ...
Object object = kryo.readClassAndObject(input);
if (object instanceof SomeClass) {
// ...
}
如果类已知且对象可以为null:
kryo.writeObjectOrNull(output, someObject);
// ...
SomeClass someObject = kryo.readObjectOrNull(input, SomeClass.class);
如果类已知且对象不能为null:
kryo.writeObject(output, someObject);
// ...
SomeClass someObject = kryo.readObject(input, SomeClass.class);
References(引用)
默认情况下,图中每个对象从第二个开始的表象都以整数顺序存储。这种方式可以序列化相同对象和循环图的多个引用。它具有少量的开销,如果不需要,可以禁用以节省空间:
Kryo kryo = new Kryo();
kryo.setReferences(false);
// ...
当使用 Kryo 作为嵌套对象的序列化器时,必须在 read() 中调用 kryo.reference()。有关详细信息,请参阅 Serializers。
Object creation(对象创建)
特定类型的序列化器使用 Java 代码创建该类型的新实例。序列化器如 FieldSerializer 是泛型的,用于处理创建任何类的新实例。默认情况下,如果某个类有一个无参构造方法,那么它将通过 ReflectASM 或反射来调用,否则抛出异常。如果无参构造方法是私有的,则尝试通过setAccessible用反射来访问它。这样的过程,可以使 Kryo 在不影响公共API的情况下创建类的实例。
当不能使用 ReflectASM 或反射时,可以配置 Kryo 使用 InstantiatorStrategy 来创建类的实例。Objenesis 提供 StdInstantiatorStrategy,它使用JVM 特定的 API 来创建类的实例,而不会调用任何构造方法。虽然这适用于许多 JVM,但无参构造方法的移植性更好。
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());
请注意,需要设计类来按下述的方式创建。如果期望调用一个类的构造函数,那么当通过这种机制创建时,它可能处于未初始化的状态。
在许多情况下,您可能希望有这样的策略:Kryo 首先尝试使用无参构造方法,如果尝试失败,再尝试使用 StdInstantiatorStrategy 作为后备方案,因为后备方案不需要调用任何构造方法。这种策略的配置可以这样表示:
kryo.setInstantiatorStrategy(new Kryo.DefaultInstantiatorStrategy(new StdInstantiatorStrategy()));
然而,这样的默认行为需要一个无参构造方法。
Objenesis 还可以使用Java的内置序列化机制创建新对象。如此的话,类必须实现 java.io.Serializable,且在调用时会执行父类中的第一个无参构造方法。
kryo.setInstantiatorStrategy(new SerializingInstantiatorStrategy());
您也可以编写自己的 InstantiatorStrategy。
要定制特定类型的创建方式,可以设置一个 ObjectInstantiator。这会覆盖 ReflectASM,反射和 InstantiatorStrategy。
Registration registration = kryo.register(SomeClass.class);
registration.setObjectInstantiator(...);
另外,一些序列化器提供重写的方式定制对象的创建。
kryo.register(SomeClass.class, new FieldSerializer(kryo, SomeClass.class) {
public Object create (Kryo kryo, Input input, Class type) {
return new SomeClass("some constructor arguments", 1234);
}
});
Copying/cloning(复制 / 克隆)
Kryo kryo = new Kryo();
SomeClass someObject = ...
SomeClass copy1 = kryo.copy(someObject);
SomeClass copy2 = kryo.copyShallow(someObject);
Serializer 类有一个复制方法可以完成复制工作。如果实现了特定于应用程序的序列化器而不使用复制功能时,可以忽略这些方法。 Kryo 提供的所有序列化器都支持复制。多个对同一个对象的引用和循环引用由框架自动处理。
与 read() Serializer 方法类似,必须先调用 kryo.reference(),然后才能使用 Kryo 来复制子对象。有关详细信息,请参阅序列化器。
类似于 KryoSerializable,类可以实现 KryoCopyable 进行自己的复制:
public class SomeClass implements KryoCopyable<SomeClass> {
// ...
public SomeClass copy (Kryo kryo) {
// Create new instance and copy values from this instance.
}
}
Context(上下文)
Compression and encryption(压缩与加密)
Kryo 支持流,因此在所有序列化字节上使用压缩或加密是不太必要的:
OutputStream outputStream = new DeflaterOutputStream(new FileOutputStream("file.bin"));
Output output = new Output(outputStream);
Kryo kryo = new Kryo();
kryo.writeObject(output, object);
output.close();
如有需要,可以使用序列化器来压缩或加密对象图字节中的一个部分字节。 例如,请参阅 DeflateSerializer 或 BlowfishSerializer。 这些序列化器包装了另一个序列化器,并对字节进行编码和解码。
Chunked encoding(分块编码)
有时先写一些数据的长度,然后再写入数据的机制是很有用的。如果数据长度不能提前知道,则需要缓冲所有数据以确定其长度,然后写入长度,再然后写入数据。这种缓冲能防止流式传输并且潜在地需要非常大的缓冲区(buffer),这并不理想。
分块编码通过使用小的缓冲区(buffer)来解决这个问题。当缓冲区已满时,其长度被写入,然后是数据。这是一个数据块的机制。当多个块时,缓冲区被清除,这样继续直到没有更多的数据写入。长度为零的块表示块的结尾。
Kryo 提供了简单的分块编码的类。 OutputChunked 用于写分块数据。它扩展了 Output,所以有方便的方法来写入数据。当 OutputChunked 缓冲区已满时,它将该块刷新到包装的 OutputStream。 endChunks() 方法用于标记一组块的结尾。
OutputStream outputStream = new FileOutputStream("file.bin");
OutputChunked output = new OutputChunked(outputStream, 1024);
// Write data to output...
output.endChunks();
// Write more data to output...
output.endChunks();
// Write even more data to output...
output.close();
如要读取分块数据,使用 InputChunked。它继承了 Input,所以有方法来读取数据。当读取时,InputChunked 将在到达一组块的末尾时作为数据的末尾。nextChunks() 方法前进到下一组块,即使当前块组中的数据并未读取完。
InputStream outputStream = new FileInputStream("file.bin");
InputChunked input = new InputChunked(inputStream, 1024);
// Read data from first set of chunks...
input.nextChunks();
// Read data from second set of chunks...
input.nextChunks();
// Read data from third set of chunks...
input.close();
Compatibility(兼容性)
对于某些需求,特别是长期存储序列化后的bytes,序列化如何处理类的变化至关重要。这被称为 forward(读取较新类的序列化生成的字节)和 backword(读取由旧类序列化产生的字节)兼容性。
FieldSerializer 是最常用的 serializer。它是通用的,可以序列化大多数类而无需任何配置。它是高效的,只写字段数据,没有任何额外信息。它不支持添加,删除或更改字段类型,不会使先前的序列化字节无效。大多情况下,这可以接受,例如通过网络发送数据,但是作为长期数据存储,这不是个好方法,因为Java 类不能演化。由于 FieldSerializer 默认尝试读写非 public 字段,因此评估将被序列化的每个类是很重要的工作。
当没有指定序列化程序时,默认情况下使用 FieldSerializer。如有必要,可以使用另一种通用的序列化器:
kryo.setDefaultSerializer(TaggedFieldSerializer.class);
BeanSerializer 非常类似于 FieldSerializer,除了它使用 bean getter 和 setter 方法,而不是直接的字段访问。速度上来说,这稍慢些,但因为它使用公共 API 来配置对象,可能会更安全。
VersionFieldSerializer 扩展了 FieldSerializer,并允许字段具有 @Since(int) 注解来指示它们被添加的版本。对于特定字段,@Since 中的值不应该在创建后改变。这不如 FieldSerializer 那么灵活,后者可以处理大多数类而不需要注解,但前者提供向后兼容性。这意味着可以添加新的字段,但删除,重命名或更改任何字段的类型将使先前的序列化字节失效。与 FieldSerializer 相比,VersionFieldSerializer 具有非常少的开销(一个额外的变量)。
TaggedFieldSerializer 将 FieldSerializer 扩展为仅序列化具有 @Tag(int) 注解的字段,提供向后兼容性,从而可以添加新字段。并且它还通过setIgnoreUnknownTags(true) 提供向前兼容性,因此任何未知的字段 tags 将被忽略。 对比 VersionFieldSerializer,TaggedFieldSerializer 有两个优点:1)字段可以被重命名,2)标记有 @Deprecated 注解的字段,在读取旧字节时或写出新字节时将被忽略。尽管字段和 @Tag 注解必须保留在类中,弃用机制有效地从序列化中删除了废弃的字段。废弃的字段能被设置私有和/或重命名,这样他们不会弄乱类的信息(例如,ignored, ignored2)。基于这些原因,TaggedFieldSerializer 为类的演化提供更多的灵活性。缺点是与 VersionFieldSerializer(每个字段需额外的一个变量)相比,它具有少量额外的开销。
CompatibleFieldSerializer 扩展了 FieldSerializer 以提供向前和向后兼容性,这意味着可以添加或删除字段,而不会使先前的序列化字节无效。它不支持更改字段的类型。像 FieldSerializer 一样,它可以序列化大多数类而不需要注解。前向和后向兼容性有一些代价:在序列化中第一次遇到某个类时,会写入一个包含字段名称字符串的简单 scheme。同时,在序列化和反序列化期间,缓冲区用以执行分块编码。这种机制使得CompatibleFieldSerializer 能够忽略它不认识的字段的字节。当 Kryo 配置为使用引用时,如果某个字段被删除,可能引发CompatibleFieldSerializer 的问题。如果您的类继承层次结构包含相同的命名字段,请使用 CachedFieldNameStrategy.EXTENDED 策略。
class A {
String a;
}
class B extends A {
String a;
}
...
// use `EXTENDED` name strategy, otherwise serialized object can't be deserialized correctly. Attention, `EXTENDED` strategy increases the serialized footprint.
kryo.getFieldSerializerConfig().setCachedFieldNameStrategy(FieldSerializer.CachedFieldNameStrategy.EXTENDED);
可以轻松开发额外的序列化器,用于向前和向后兼容性,例如使用外部手写 schema 的序列化器。
Interoperability(互通性)
Stack size(栈大小)
Threading(线程)
Pooling Kryo instances(池化Kryo实例)
因为 Kryo 实例的创建/初始化是相当昂贵的,所以在多线程的情况下,您应该池化 Kryo 实例。一个非常简单的解决方案是使用 ThreadLocal 将 Kryo实例绑定到 Threads,如下所示:
// Setup ThreadLocal of Kryo instances
private static final ThreadLocal<Kryo> kryos = new ThreadLocal<Kryo>() {
protected Kryo initialValue() {
Kryo kryo = new Kryo();
// configure kryo instance, customize settings
return kryo;
};
};
// Somewhere else, use Kryo
Kryo k = kryos.get();
...
或者您也可以使用 kryo 提供的 KryoPool。 KryoPool 允许使用 SoftReferences 保留对 Kryo 实例的引用,这样当 JVM 开始耗尽内存时,Kryo 实例就可以被 GC 回收(当然你也可以使用 ThreadLocal 和 SoftReferences)。
以下是一个示例,显示如何使用KryoPool:
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.pool.*;
KryoFactory factory = new KryoFactory() {
public Kryo create () {
Kryo kryo = new Kryo();
// configure kryo instance, customize settings
return kryo;
}
};
// Build pool with SoftReferences enabled (optional)
KryoPool pool = new KryoPool.Builder(factory).softReferences().build();
Kryo kryo = pool.borrow();
// do s.th. with kryo here, and afterwards release it
pool.release(kryo);
// or use a callback to work with kryo - no need to borrow/release,
// that's done by `run`.
String value = pool.run(new KryoCallback() {
public String execute(Kryo kryo) {
return kryo.readObject(input, String.class);
}
});
Logging(日志)
Kryo利用低开销,轻量级的MinLog日志库。可以通过以下方法之一设置日志记录级别:
Log.ERROR();
Log.WARN();
Log.INFO();
Log.DEBUG();
Log.TRACE();
Kryo在INFO(默认)和以上级别没有记录。 DEBUG方便在开发过程中使用。调试一个特定的问题时,TRACE很好用,但是通常输出的信息太多。
MinLog支持固定的日志记录级别,这会导致javac在编译时删除低于该级别的日志记录。在Kryo发行版ZIP中,"debug"JAR启用日志记录。 "production"JAR使用NONE的固定日志记录级别,这意味着所有日志记录代码已被删除。
Scala
请参阅以下为Scala类提供序列化的项目:
- Twitter's Chill (Kryo serializers for Scala)
- akka-kryo-serialization (Kryo serializers for Scala and Akka)
- Twitter's Scalding (Scala API for Cascading)
- Kryo Serializers (Additional serializers for Java)
- Kryo Macros (Scala macros for compile-time generation of Kryo serializers)
Clojure
- Carbonite (Kryo serializers for Clojure)
Objective-C
请参阅以下项目,它是Kryo的Objective-C端口:
Benchmarks(基准测试)
可以将 Kryo 与 JVM Serializers 项目中的许多其他序列化库进行比较。使用基准测试很难彻底比较序列化库。这些序列化库有不同的目的,并擅长完全不同的问题。为了理解这些基准测试,运行代码和序列化的数据应该根据您的具体需求进行分析和对比。一些序列化程序是高度优化的,代码可能多达几页,而有些仅只有几行。这很好的说明了有些测试可能有用,但在许多情况下可能并不实用。
“kryo”是典型的 Kryo 使用方式,类是注册的,序列化自动完成。 “kryo-opt”显示了如何配置序列化器以减少序列化数据的大小,但序列化仍然是自动完成的。 “kryo-manual”寿命了如何使用手写的序列化代码来优化大小和速度,同时仍然利用 Kryo 进行大部分工作。
Projects using Kryo(使用Kryo的项目)
有不少项目使用了Kryo,以下仅列出一些。如果您希望您的项目也列在此,请提交一个申请。
- KryoNet (NIO networking)
- Twitter's Scalding (Scala API for Cascading)
- Twitter's Chill (Kryo serializers for Scala)
- Apache Fluo (Kryo is default serialization for Fluo Recipes)
- Apache Hive (query plan serialization)
- Apache Spark (shuffled/cached data serialization)
- DataNucleus (JDO/JPA persistence framework)
- CloudPelican
- Yahoo's S4 (distributed stream computing)
- Storm (distributed realtime computation system, in turn used by many others)
- Cascalog (Clojure/Java data processing and querying details)
- memcached-session-manager (Tomcat high-availability sessions)
- Mobility-RPC (RPC enabling distributed applications)
- akka-kryo-serialization (Kryo serializers for Akka)
- Groupon
- Jive
- DestroyAllHumans (controls a robot!)
- kryo-serializers (additional serializers)
Contact / Mailing list(联系 / 邮件组)
您可以使用 kryo mailing list 以咨询、讨论和获取支持














 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









