









Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit。
接上篇,本篇分析该算法的最后一个job。
在上篇计算共生矩阵的乘积后,接下来又到了一个shouldRunNextPhase的方法了,这个方法里面含有三个prepareJob,但是本次只分析一个,为啥?因为在实战中没有设置filterFile,这里其实是可以设置filterFile的,设置这个参数的作用是什么,用源码中的英文解释就是过滤掉不不关心的用户,那我就会产生疑问了,在上个计算共生矩阵乘积的时候明明是可以设置一个文件,用于过滤掉我们不关心的用户了,这里还要过滤?所以这里不是很明白源码设计的思路。但是,这里是分析算法的,关于过滤,其实也可以这样说,把全部结果分析出来后,然后再进行过滤,全部结果的分析就是算法的大概,而后面进行过滤可做可不做(这种做法和原来设计的还是有点不同的,效率不一样,如果可以在前期过滤掉一些数据,那么后面的计算会加快)。整个系列blog都是分析算法,所以过滤这一块暂时不关心。
这里可以看到是有三个job调用的:
if (filterFile != null) {
Job itemFiltering = prepareJob(new Path(filterFile), explicitFilterPath, TextInputFormat.class,
ItemFilterMapper.class, VarLongWritable.class, VarLongWritable.class,
ItemFilterAsVectorAndPrefsReducer.class, VarIntWritable.class, VectorAndPrefsWritable.class,
SequenceFileOutputFormat.class);//extract out the recommendations
Job aggregateAndRecommend = prepareJob(
new Path(aggregateAndRecommendInput), outputPath, SequenceFileInputFormat.class,
PartialMultiplyMapper.class, VarLongWritable.class, PrefAndSimilarityColumnWritable.class,
AggregateAndRecommendReducer.class, VarLongWritable.class, RecommendedItemsWritable.class,
TextOutputFormat.class);if (filterFile != null) {
setS3SafeCombinedInputPath(aggregateAndRecommend, getTempPath(), partialMultiplyPath, explicitFilterPath);
}
setIOSort(aggregateAndRecommend);
aggregateAndRecommendConf.set(AggregateAndRecommendReducer.ITEMID_INDEX_PATH,
new Path(prepPath, PreparePreferenceMatrixJob.ITEMID_INDEX).toString());
aggregateAndRecommendConf.setInt(AggregateAndRecommendReducer.NUM_RECOMMENDATIONS, numRecommendations);
aggregateAndRecommendConf.setBoolean(BOOLEAN_DATA, booleanData);
boolean succeeded = aggregateAndRecommend.waitForCompletion(true);这个job是有mapper和reducer的,下面一个个分析:
首先来看下这个job的输入文件,输入文件就是前面计算共生矩阵的输出,如下:
{102={106:0.1497250646352768,105:0.14328432083129883,104:0.12789210677146912,103:0.19754962623119354,102:NaN,101:0.14201472699642181} [5, 1, 2] [3.0, 3.0, 2.5],
103={106:0.14243397116661072,105:0.11208890378475189,104:0.140376016497612,103:NaN,102:0.19754962623119354,101:0.15548737347126007} [4, 1, 2, 5] [3.0, 2.5, 5.0, 2.0],
101={107:0.10275248438119888,106:0.14243397116661072,105:0.11584573984146118,104:0.1601526141166687,103:0.15548737347126007,102:0.14201472699642181,101:NaN} [5, 1, 4, 2, 3] [4.0, 5.0, 5.0, 2.0, 2.5],
106={106:NaN,105:0.14201472699642181,104:0.1818181872367859,103:0.14243397116661072,102:0.1497250646352768,101:0.14243397116661072} [4, 5] [4.0, 4.0],
107={101:0.10275248438119888,107:NaN,105:0.22048120200634003,104:0.13472338020801544} [3] [5.0],
104={107:0.13472338020801544,106:0.1818181872367859,105:0.16736577451229095,104:NaN,103:0.140376016497612,102:0.12789210677146912,101:0.1601526141166687} [4, 2, 5, 3] [4.5, 2.0, 4.0, 4.0],
105={107:0.22048120200634003,106:0.14201472699642181,105:NaN,104:0.16736577451229095,103:0.11208890378475189,102:0.14328432083129883,101:0.11584573984146118} [5, 3] [3.5, 4.5]}(1)mapper://PartialMultiplyMapper
(1.1)map:
protected void map(VarIntWritable key,
VectorAndPrefsWritable vectorAndPrefsWritable,
Context context) throws IOException, InterruptedException {
Vector similarityMatrixColumn = vectorAndPrefsWritable.getVector();
List<Long> userIDs = vectorAndPrefsWritable.getUserIDs();
List<Float> prefValues = vectorAndPrefsWritable.getValues();
VarLongWritable userIDWritable = new VarLongWritable();
PrefAndSimilarityColumnWritable prefAndSimilarityColumn = new PrefAndSimilarityColumnWritable();
for (int i = 0; i < userIDs.size(); i++) {
long userID = userIDs.get(i);
float prefValue = prefValues.get(i);
if (!Float.isNaN(prefValue)) {
prefAndSimilarityColumn.set(prefValue, similarityMatrixColumn);
userIDWritable.set(userID);
context.write(userIDWritable, prefAndSimilarityColumn);
}
}
}那么,其输出应该是<key,value> --> <5,[3.0,[{102={106:0.1497250646352768,105:0.14328432083129883,104:0.12789210677146912,103:0.19754962623119354,102:NaN,101:0.14201472699642181} [5, 1, 2] [3.0, 3.0, 2.5], ]]> 、<1,[3.0,[{102={106:0.1497250646352768,105:0.14328432083129883,104:0.12789210677146912,103:0.19754962623119354,102:NaN,101:0.14201472699642181} [5, 1, 2] [3.0, 3.0, 2.5], ]]> 、<2,[2.5,[{102={106:0.1497250646352768,105:0.14328432083129883,104:0.12789210677146912,103:0.19754962623119354,102:NaN,101:0.14201472699642181} [5, 1, 2] [3.0, 3.0, 2.5], ]]> ,即userIDs中有多少个用户就输出多少条记录。输出格式是:<key,value> --> <userID,[prefValue,[itemid:simi,itemid:simi,...]]> 。
(2)reducer://AggregateAndRecommendReducer
(2.1)setup:
在setup中初始化了四个变量,recommendationsPerUser,这个在实战中设置的是3;booleanData,这个设置的是false;indexItemIDMap这个是读取ITEMID_INDEX,即第一个job的输出了,即VarIntWritable和VarLongWritable的映射;itemsToRecommendFor,这个是要设置一个itemFile的文件的,由于在实战中没有进行设置,所以这个itemsToRecommendFor就是为null了。
(2.2)reduce:
protected void reduce(VarLongWritable userID,
Iterable<PrefAndSimilarityColumnWritable> values,
Context context) throws IOException, InterruptedException {
if (booleanData) {
reduceBooleanData(userID, values, context);
} else {
reduceNonBooleanData(userID, values, context);
}
}private void reduceNonBooleanData(VarLongWritable userID,
Iterable<PrefAndSimilarityColumnWritable> values,
Context context) throws IOException, InterruptedException {
/* each entry here is the sum in the numerator of the prediction formula */
Vector numerators = null;
/* each entry here is the sum in the denominator of the prediction formula */
Vector denominators = null;
/* each entry here is the number of similar items used in the prediction formula */
Vector numberOfSimilarItemsUsed = new RandomAccessSparseVector(Integer.MAX_VALUE, 100);
for (PrefAndSimilarityColumnWritable prefAndSimilarityColumn : values) {
Vector simColumn = prefAndSimilarityColumn.getSimilarityColumn();
float prefValue = prefAndSimilarityColumn.getPrefValue();
/* count the number of items used for each prediction */
Iterator<Vector.Element> usedItemsIterator = simColumn.iterateNonZero();
while (usedItemsIterator.hasNext()) {
int itemIDIndex = usedItemsIterator.next().index();
numberOfSimilarItemsUsed.setQuick(itemIDIndex, numberOfSimilarItemsUsed.getQuick(itemIDIndex) + 1);
}
numerators = numerators == null
? prefValue == BOOLEAN_PREF_VALUE ? simColumn.clone() : simColumn.times(prefValue)
: numerators.plus(prefValue == BOOLEAN_PREF_VALUE ? simColumn : simColumn.times(prefValue));
simColumn.assign(ABSOLUTE_VALUES);
denominators = denominators == null ? simColumn : denominators.plus(simColumn);
}
if (numerators == null) {
return;
}
Vector recommendationVector = new RandomAccessSparseVector(Integer.MAX_VALUE, 100);
Iterator<Vector.Element> iterator = numerators.iterateNonZero();
while (iterator.hasNext()) {
Vector.Element element = iterator.next();
int itemIDIndex = element.index();
/* preference estimations must be based on at least 2 datapoints */
if (numberOfSimilarItemsUsed.getQuick(itemIDIndex) > 1) {
/* compute normalized prediction */
double prediction = element.get() / denominators.getQuick(itemIDIndex);
recommendationVector.setQuick(itemIDIndex, prediction);
}
}
writeRecommendedItems(userID, recommendationVector, context);
}这个函数好长呀,要一点点看才行。在前面已经分析其map输出的结果了,这里整合一下,因为在reducer中是把相同的key整合起来的,所以,这里也把相同的key放在一起,方便reducer的分析,这个mapper输出主要是通过log信息打印出来(其实直接分析就可以的,这里图省事,直接设置log进行打印而已):
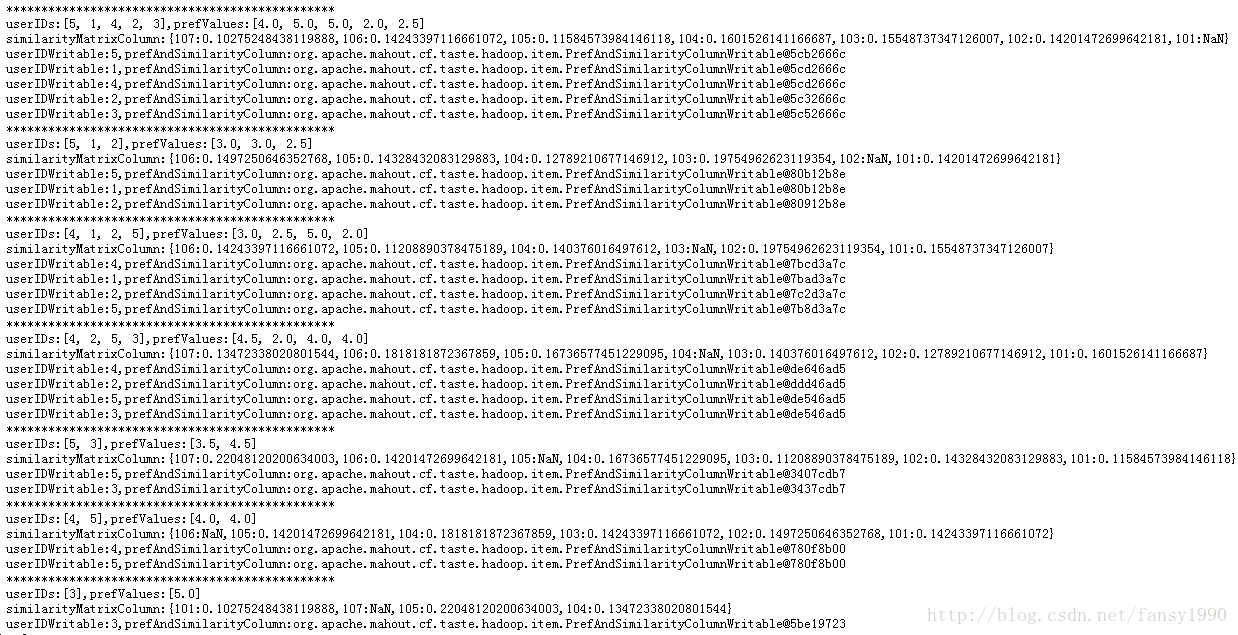
userIDWritable:5,prefAndSimilarityColumn:org.apache.mahout.cf.taste.hadoop.item.PrefAndSimilarityColumnWritable@5cb2666c类似这样的就是最后map的输出结果了,这个结果怎么解读?首先key就是userIDWritable了,后面就是实际值;后面的prefAndSimilarityColumn打印的是一个地址,同时看到不同的用户id输出的地址竟然是一样的?比如针对第一条输出(即上面的输出),其输出其实应该是<key,value> -->
<5,[4.0,[107:0.10275248438119888,106:0.14243397116661072,105:0.11584573984146118,104:0.1601526141166687,103:0.15548737347126007,102:0.14201472699642181,101:NaN]]>
而第二条的输出其实是:<key,value> -->
<1,[5.0,[107:0.10275248438119888,106:0.14243397116661072,105:0.11584573984146118,104:0.1601526141166687,103:0.15548737347126007,102:0.14201472699642181,101:NaN]]>通过上面的两条比较发现其实value只有prefValue的值不一样而已,但是为什么地址居然是一样的呢?这个是因为prefAndSimilarityColumn变量是在for循环外面定义好了,所以其地址不会变,同时因为每条数据设置值后直接写入了文件中,不存在后面设置的值会覆盖前面值的情况;整合后的map输出如下所示(只列出了用户1和2的数据):
1:
{[3.0,[106:0.1497250646352768,105:0.14328432083129883,104:0.12789210677146912,103:0.19754962623119354,102:NaN,101:0.14201472699642181]],
[2.5,[106:0.14243397116661072,105:0.11208890378475189,104:0.140376016497612,103:NaN,102:0.19754962623119354,101:0.15548737347126007]],
[5.0,[107:0.10275248438119888,106:0.14243397116661072,105:0.11584573984146118,104:0.1601526141166687,103:0.15548737347126007,102:0.14201472699642181,101:NaN]]
}
2:
{[2.5,[106:0.1497250646352768,105:0.14328432083129883,104:0.12789210677146912,103:0.19754962623119354,102:NaN,101:0.14201472699642181]],
[5.0,[106:0.14243397116661072,105:0.11208890378475189,104:0.140376016497612,103:NaN,102:0.19754962623119354,101:0.15548737347126007]],
[2.0,[107:0.10275248438119888,106:0.14243397116661072,105:0.11584573984146118,104:0.1601526141166687,103:0.15548737347126007,102:0.14201472699642181,101:NaN]],
[2.0,[107:0.13472338020801544,106:0.1818181872367859,105:0.16736577451229095,104:NaN,103:0.140376016497612,102:0.12789210677146912,101:0.1601526141166687]],
}首先初始化三个向量,然后进行for循环,for循环遍历输入的values,这个values就是上面1后面大括号里面的内容,使用foreach进行遍历,首先prefAndSimilarityColumn遍历就会被赋值为[3.0,[106:0.1497250646352768,105:0.14328432083129883,104:0.12789210677146912,103:0.19754962623119354,102:NaN,101:0.14201472699642181]],然后针对上面的变量取出前面的prefValue和后面的similarityVector分别赋值给prefValue、simColumn,看while循环是干嘛的:
Iterator<Vector.Element> usedItemsIterator = simColumn.iterateNonZero();
while (usedItemsIterator.hasNext()) {
int itemIDIndex = usedItemsIterator.next().index();
numberOfSimilarItemsUsed.setQuick(itemIDIndex, numberOfSimilarItemsUsed.getQuick(itemIDIndex) + 1);
}接着是:
numerators = numerators == null
? prefValue == BOOLEAN_PREF_VALUE ? simColumn.clone() : simColumn.times(prefValue)
: numerators.plus(prefValue == BOOLEAN_PREF_VALUE ? simColumn : simColumn.times(prefValue));
simColumn.assign(ABSOLUTE_VALUES);
denominators = denominators == null ? simColumn : denominators.plus(simColumn);接着是simColumn.assign(ABSOLUTE_VALUES);,额,好吧,说实话,这个我的确是不知道这个是啥意思,感觉也没啥作用的,并没有对simColumn进行任何的操作,这行代码运行前后simColumn的值并没有改变。
然后就是denominators了,这个也是一个三目,其实前面的两个三目分析后,这个就是小儿科了,这个的意思即是遍历用户1的values然后使用simi乘以prefValue的值全部相加即是变量denominators的值了。
然后for循环就结束了,接下来判断下numerators是否是null,如果是的话直接返回,即说明这个用户没有推荐的项目了,如果不为null,那么就是有推荐的项目,但是要做些处理才能输出,比如把得分最大的输出在第一个等等操作。
接下来的while循环就是求得分的算法了,主要是使用numerators除以denominators中对应的项,得到的值即是每个项目的得分了,但是这里还要使用前面的numberOfSimilarItemsUsed向量进行过滤,如果次数没有大于1,那么这个项目不用计算得分,那就是说这个项目不用输出了,根据上面的数据,用户1的输出如下:
106:3.491611584457462,105:3.4731628623748563,104:3.583812122426105,103:NaN,102:NaN,101:NaN}107:0.5137624219059944,106:1.5174299776554108,105:1.2893039211630821,104:1.5353794321417809,103:NaN,102:NaN,101:NaN107:0.10275248438119888,106:0.43459300696849823,105:0.3712189644575119,104:0.4284207373857498,103:NaN,102:NaN,101:NaN然后就是调用函数writeRecommendedItems进行输出了,看这个函数:
private void writeRecommendedItems(VarLongWritable userID, Vector recommendationVector, Context context)
throws IOException, InterruptedException {
TopK<RecommendedItem> topKItems = new TopK<RecommendedItem>(recommendationsPerUser, BY_PREFERENCE_VALUE);
Iterator<Vector.Element> recommendationVectorIterator = recommendationVector.iterateNonZero();
while (recommendationVectorIterator.hasNext()) {
Vector.Element element = recommendationVectorIterator.next();
int index = element.index();
long itemID;
if (indexItemIDMap != null && !indexItemIDMap.isEmpty()) {
itemID = indexItemIDMap.get(index);
} else { //we don't have any mappings, so just use the original
itemID = index;
}
if (itemsToRecommendFor == null || itemsToRecommendFor.contains(itemID)) {
float value = (float) element.get();
if (!Float.isNaN(value)) {
topKItems.offer(new GenericRecommendedItem(itemID, value));
}
}
}
if (!topKItems.isEmpty()) {
context.write(userID, new RecommendedItemsWritable(topKItems.retrieve()));
}
}private static final Comparator<RecommendedItem> BY_PREFERENCE_VALUE =
new Comparator<RecommendedItem>() {
@Override
public int compare(RecommendedItem one, RecommendedItem two) {
return Floats.compare(one.getValue(), two.getValue());
}
};
看while循环里面就是把前面得到的得分向量加入TopKItems中,每次使用offer函数进行加入,offer函数:
public void offer(T item) {
if (queue.size() < k) {
queue.add(item);
} else if (queueingComparator.compare(item, queue.peek()) > 0) {
queue.add(item);
queue.poll();
}
}[RecommendedItem[item:105, value:3.473163], RecommendedItem[item:106, value:3.4916115], RecommendedItem[item:104, value:3.5838122]]RecommendedItem[item:107, value:2.0], RecommendedItem[item:106, value:2.8146582], RecommendedItem[item:105, value:2.7573717]然后最后输出的时候使用了retrieve函数,看这个函数:
public List<T> retrieve() {
List<T> topItems = Lists.newArrayList(queue);
Collections.sort(topItems, sortingComparator);
return topItems;
}1=[104:3.5838122,106:3.4916115,105:3.473163],
2=[106:2.8146582,105:2.7573717,107:2.0]
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990














 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









