




 本文介绍了HotSpot关联规则算法在挖掘离散型数据中的应用,通过分析weka中的实现,探讨了算法参数如最小支持度、最大分指数等,并提供了数据处理和算法伪代码的解析,分享了作者对算法的理解和个人见解。
本文介绍了HotSpot关联规则算法在挖掘离散型数据中的应用,通过分析weka中的实现,探讨了算法参数如最小支持度、最大分指数等,并提供了数据处理和算法伪代码的解析,分享了作者对算法的理解和个人见解。
提到关联规则算法,一般会想到Apriori或者FP,一般很少有想到HotSpot的,这个算法不知道是应用少还是我查资料的手段太low了,在网上只找到很少的内容,这篇http://wiki.pentaho.com/display/DATAMINING/HotSpot+Segmentation-Profiling ,大概分析了一点,其他好像就没怎么看到了。比较好用的算法类软件,如weka,其里面已经包含了这个算法,在Associate--> HotSpot里面即可看到,运行算法界面一般如下:
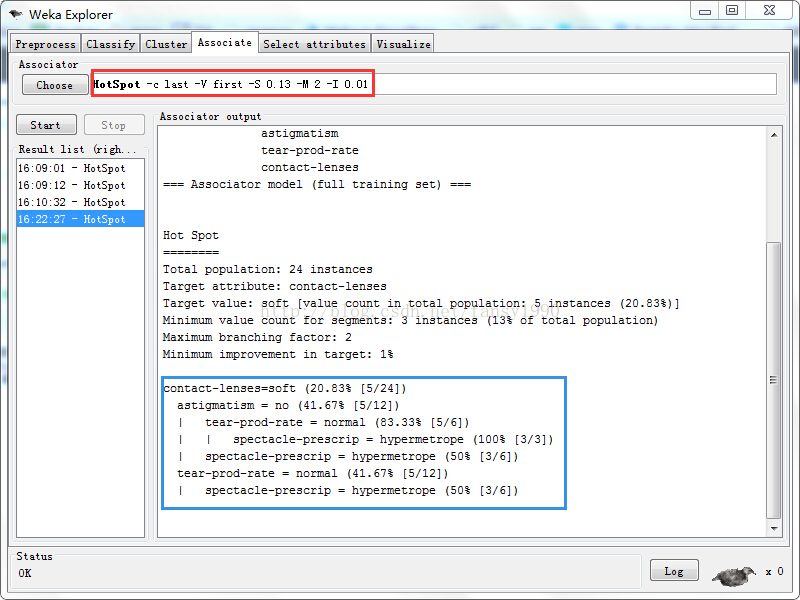
其中,红色方框里面为设置的参数,如下:
-c last ,表示目标所在的目标所在的列,last表示最后一列,也是是数值,表示第几列;
-V first, 表示目标列的某个状态值下标值(这里可以看出目标列应该是离散型),first表示第0个,可以是数值型;
-S 0.13,最小支持度,里面会乘以样本总数得到一个数值型的支持度;
-M 2 , 最大分指数;
-I 0.01 , 在weka里面解释为Minimum improvement in target value,不知道是否传统的置信度一样;
相关说明:本篇相关代码参考weka里面的HotSpot算法的具体实现,本篇只分析离散型数据,代码可以在(http://download.csdn.net/detail/fansy1990/8488971)下载。
1. 数据:
@attribute age {young, pre-presbyopic, presbyopic}
@attribute spectacle-prescrip {myope, hypermetrope}
@attribute astigmatism {no, yes}
@attribute tear-prod-rate {reduced, normal}
@attribute contact-lenses {soft, hard, none}
young,myope,no,reduced,none
young,myope,no,normal,soft
young,myope,yes,reduced,none
。。。
presbyopic,hypermetrope,yes,normal,none2. 单个节点定义:
public class HSNode {
private int splitAttrIndex; // 属性的下标
private int attrStateIndex; // 属性state的下标
private int allCount ; // 当前数据集的个数
private int stateCount ; // 属性的state的个数
private double support; // 属性的支持度
private List<HSNode> chidren;
public HSNode(){}}

splitAttrIndex 即对应属性astigmatism的下标(应该是第2个,从0开始);attrStateIndex 则对应这个属性的下标,即no的下标(这里应该是0);allCount即12,stateCount即5,support 对应41.57%(即5/12的值);children即其孩子节点;(这里的下标即是从文件的前面几行编码得到的,比如属性age为第一个属性,编码为0,young为其第一个状态,编码为0);
3. 算法伪代码,(文字描述,太不专业了,如果要看,就将就看?)
1. 创建根节点;
2. 创建孩子节点;
2.1 针对所有数据,计算每列的每个属性的’支持度‘support,
if support> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4896
4896





 到【灌水乐园】发言
到【灌水乐园】发言







