







作者:华清远见讲师
Hadoop起源:hadoop的创始者是Doug Cutting,起源于Nutch项目,该项目是作者尝试构建的一个开源的Web搜索引擎。起初该项目遇到了阻碍,因为始终无法将计算分配给多台计算机。谷歌发表的关于GFS和MapReduce相关的论文给了作者启发,最终让Nutch可以在多台计算机上稳定的运行;后来雅虎对这项技术产生了很大的兴趣,并组建了团队开发,从Nutch中剥离出分布式计算模块命名为“Hadoop”。最终Hadoop在雅虎的帮助下能够真正的处理海量的Web数据。
Hadoop集群是一种分布式的计算平台,用来处理海量数据,它的两大核心组件分别是HDSF文件系统和分布式计算处理框架mapreduce。HDFS是分布式存储系统,其下的两个子项目分别是namenode和datanode;namenode管理着文件系统的命名空间包括元数据和datanode上数据块的位置,datanode在本地保存着真实的数据。它们都分别运行在独立的节点上。Mapreduce的两大子项目分别是jobtracker和tasktracker,jobtracker负责管理资源和分配任务,tasktracker负责执行来自jobtracker的任务。
Hadoop1升级成hadoop2后,为解决原来HDFS的namenode的单点故障问题,于是有了HA集群的出现;为解决原来mapreduce的jobtracker的单点故障以及负担过重的问题,于是有了mapreduce2也就是YARN的出现。
HA集群我们采取了QJM的方式进行;每个节点上安装hadoop,java JDK,子节点(datanode)安装zookeeper搭建journalnode集群(该集群数量必须是单数);HA结构具有高可用性, ACtive namenode和standby namenode之间元数据是同步的;ACtive namenode 每次完成操作后,生成edits log,会将edits log通过ZKFC发送给journalnode集群的多数派(当journalnode集群的大多数节点拿到edits log即视为成功),datanode拿到数据会将数据发送给standby namenode,同时datanode还会将自己的数据块的位置信息报告给standby namenode。client向active namenode发出请求,当active namenode无回应时,active会直接向standby namenode发出请求,此时standby namenode会转变为active namenode。
YARN是hadoop2里mapreduce的别称;它将一版本里的jobtracker的工作分为了两部分:ResourceManager 和AppMaster 分别管理mapreduce的资源和工作周期。除此之外,yarn同样解决了jobtracker的单点故障问题。
Hadoop作为一个分布式处理大数据的平台。它的内部机制挺复杂的,但是如果是仅仅作为使用者,我们只需要弄清楚它的工作机制,它的功能以及如何使用就行。Hadoop与其他的Hadoop项目比如说:Ambari,Hive,Hbase,Pig,Spark,zookeeper......一起组成hadoop生态圈,共同完成对大数据的处理和分析。Hadoop和其他一些大数据平台一起被称为大数据技术。
Hadoop 的核心子项目是 HDFS 和 Mapreduce,hadoop2.0 还包括 YARN资源管理器。图1.1为 hadoop 的生态系统。
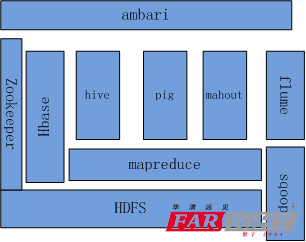
(1)HDFS:
是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS 简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序
(2)MapReduce
是一种计算模型,用以进行大数据量的计算。其中 Map 对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce 则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce 这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
(3)Hive:
数据仓库基础设施,提供数据汇总和特定查询。这个系统支持用户进行有效的查询,并实时得到返回结果,定义了一种类似 SQL 的查询语言(HQL),将 SQL 转化为 MapReduce 任务在 Hadoop 上执行。通常用于离线分析。
(4)Spark
Spark 是提供大数据集上快速进行数据分析的计算引擎。它建立在HDFS 之上,却绕过了 MapReduce 使用自己的数据处理框架。Spark 常用于实时查询、流处理、迭代算法、复杂操作运算和机器学习。
(5)Ambari:
Ambari 用来协助管理 Hadoop。它提供对 Hadoop 生态系统中许多工具的支持,包括 Hive、HBase、Pig、 Spooq 和 ZooKeeper。这个工具提供集群管理仪表盘,可以跟踪集群运行状态,帮助诊断性能问题。
(4)Pig:
Pig 是一个集成高级查询语言的平台,可以用来处理大数据集。
(5)HBase:
HBase 是一个非关系型数据库管理系统,以zookeeper做协同服务,运行在 HDFS 之上。它用来处理大数据工程中稀疏数据集。是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase 采用了 BigTable 的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase 提供了对大规模数据的随机、实时读写访问,同时,HBase 中保存的数据可以使用 MapReduce 来处理,它将数据存储和并行计算完美地结合在一起。数据模型:Schema-->Table-->Column Family-->Column-->RowKey-->TimeStamp-->Value。
(6)Zookeeper
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
(7)Sqoop(数据同步工具)
Sqoop 是 SQL-to-Hadoop 的缩写,主要用于传统数据库和 Hadoop 之前传输数据。数据的导入和导出本质上是 Mapreduce 程序,充分利用了 MR 的并行化和容错性。
(8)Pig:
基于 Hadoop 的数据流系统设计动机是提供一种基于 MapReduce 的 ad-hoc(计算在 query 时发生)数据分析工具定义了一种数据流语言—Pig Latin,将脚本转换为 MapReduce 任务在 Hadoop 上执行。通常用于进行离线分析。
(9)Mahout (数据挖掘算法库)
Mahout 起源于 2008 年,最初是 Apache Lucent 的子项目,它在极短的时间内取得了长足的发展,现在是 Apache 的顶级项目。Mahout 的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout 现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout 还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或 Cassandra)集成等数据挖掘支持架构。
(10)Flume(日志收集工具)
Cloudera 开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在 Flume中定制数据发送方,从而支持收集各种不同协议数据。同时, Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume 还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume 是一个可扩展、适合复杂环境的海量日志收集系统。
(11)资源管理器的简单介绍(YARN)
随着互联网的高速发展,基于数据密集型应用的计算框架不断出现,从支持离线处理的
MapReduce,到支持在线处理的 Storm,从迭代式计算框架 Spark 到流式处理框架 S4,…,各种框架诞生于不同的公司或者实验室,它们各有所长,各自解决了某一类应用问题。而在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方案如下:网页建索引采用 MapReduce 框架,自然语言处理/数据挖掘采用 Spark(网页 PageRank计算,聚类分类算法等),对性能要求很高的数据挖掘算法用 MPI 等。考虑到资源利用率,运维成本,数据共享等因素,公司一般希望将所有这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样,便诞生了资源统一管理与调度平台,典型代表是YARN。
hadoop其他的一些开源组件:
1) cloudera impala:
impala 是由 Cloudera 开发,一个开源的 Massively Parallel Processing(MPP)查询引
擎 。与 Hive 相同的元数据、SQL 语法、ODBC 驱动程序和用户接口(Hue Beeswax),可以直接在 HDFS 或 HBase 上提供快速、交互式 SQL 查询。Impala 是在 Dremel 的启发下开发的,第一个版本发布于 2012 年末。Impala 不再使用缓慢的 Hive+MapReduce 批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或者 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
2)spark:
Spark 是个开源的数据分析集群计算框架,最初由加州大学伯克利分校 AMPLab 开发,建立于 HDFS 之上。Spark 与 Hadoop 一样,用于构建大规模、低延时的数据分析应用。Spark 采用 Scala 语言实现,使用 Scala 作为应用框架。Spark 采用基于内存的分布式数据集,优化了迭代式的工作负载以及交互式查询。与Hadoop不同的是,Spark和Scala紧密集成,Scala 像管理本地collective对象那样管理分布式数据集。Spark 支持分布式数据集上的迭代式任务,实际上可以在Hadoop 文件系统上与Hadoop一起运行(通过 YARN、Mesos 等实现)。
3) storm
Storm 是一个分布式的、容错的实时计算系统,由BackType开发,后被Twitter捕获。Storm 属于流处理平台,多用于实时计算并更新数据库。Storm 也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式 RPC”,以并行的方式运行昂贵的运算。存储和并行计算完美地结合在一起。














 2962
2962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









