










1. hbase:
hbase + phoenix: 强大的大数据 key-value + 大数据关系型引擎 (无 join,join 性能差)
单节点,可靠性差.
详细模块图,和流程图 读写流程模块图, 无读写时序图.
启动注册流程,读写流程.
水平扩容, rowKey 设置要小心. 写快,读慢 (通过副本,和 分区 split )
base 很巧妙的把数据和数据指令处理队列变成了两部分. 利用 nameNode 来记录 文件在哪个 regionServer 上. 然后所有的指令就排队了.
另外一种数据一致性和可靠性的思路. region 可以无状态 (如果不采用 lsm-tree )就能保证了数据一致性.
这个和 zk 的类 paxos 思路是截然不同的.
但是 hbase 的 region 需要进行 replication .
HBase 系统架构
HBase原理-RegionServer宕机数据恢复
https://stackoverflow.com/questions/46318946/why-hbase-lsm-do-significant-influence-on-read-perfomance-but-mysql-buffer-dirt
2. mysql:
传统的关系型数据库. 分库分表,性能好,运维成熟.
详情区别 请查看, hbase 替换 mysql
3. hive:
基于 hdfs 的分析使用, 不能改, map-reduce.慢
详细区别请 HDFS只支持文件append操作, 而依赖HDFS的HBase如何完成增删改查功能
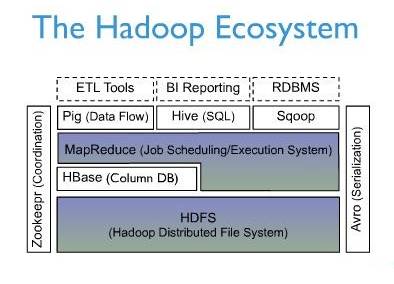
4. elsearch elasticsearch es 适合非结构化搜索. 延迟大.精准度低.
适合混合查询用, 延迟比较慢30s.可能会搜索不到最近的订单.同时搜索 n 个字段.场景:支付宝搜索自己的账单
mongodb没有显式的schema但是如果把不同的schema的文档插入进去,会报错某个字段的类型不一致. es有显示的index (schema)
一个es的index(我称之为doc_schema)可以有多个文档,每个文档有一个id, 一个文档可以有多行数据.不超过100M. 一旦文档中list太多, 建议每行存成不同的文档. Elasticsearch 单个文档的大小上限一般是默认限制在 100MB。然而,建议单个文档的大小最好不要超过几兆字节,这将有助于提高搜索效率和响应速度。"
Elasticsearch的增删改查(含数组) - from chatgpt
算法中的特征的保存, es 和 mysql 和 odps hadoop hbase的区别_个人渣记录仅为自己搜索用的博客-CSDN博客
Elasticsearch底层存储结构 和 一些上限 from chatgpt
5. mongodb
水平扩容能力. 动态扩容. 分片.
分片后写性能不错. 哪怕是微分片,也有提高.
使用YCSB测试MongoDB的微分片性能 分片性能还可以
新鲜出炉,PCIE卡SQLServer和SSD Mongodb集群4千万数据insert测试
为什么你不应该使用 MongoDB http://www.open-open.com/news/view/198c59b . phil 注: 1. 把文档当做大表用. 出现很多问题. 应该还是把 mongodb 的文档当做实体表用. 这样后期有助于搜索性能. 统一的 schema 还是要的.
2.除了利用地理位置信息外,不要使用 复杂属性.
备份策略: 简单的备份和 日志. 不如 hbase 的 hdfs 三份策略.
微分片:
就是使用MongoDB的分片技术,但是多个或者全部分片Mongod运行在同一台服务器(服务器可以是物理机或者虚机)上。由于库级锁的存在,以及MongoDB对多核CPU的利用率不是很高的特性,微分片在满足以下条件的场景下会是一个不错的性能调优手段
Mongodb支持集合查找,正则查找,范围查找,支持skip和limit等等,是最像mysql的nosql数据库,而hbase只支持三种查找:通过单个row key访问,通过row key的range,全表扫描
.mongodb的update是update-in-place,也就是原地更新,除非原地容纳不下更新后的数据记录。而hbase的修改和添加都是同一个命令:put,如果put传入的row key已经存在就更新原记录,实际上hbase内部也不是更新,它只是将这一份数据已不同的版本保存下来而已,hbase默认的保存版本的历史数量是3。
hbase 和 cassandra 区别对比
采用的LSM思想(Log-Structured Merge-Tree), 区别: 副本一致性协议用的hdfs. memstore 无. 分片用的是range, 不hash. 直接rowkey.
cassandra:
也是lsm ,区别: 但是副本一致性协议用的是gossip. 分片用的是一致性hash.














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









