






说明:标注有“飞说不可”的话就是俺说的了,鉴于本人英语水平和学习能力有限,有什么不对的地方敬请拍砖。如果有什么理解错误或者没有表述清楚的地方,请一定要跟我联系啊。在此多谢了。中文如果有版权就是俺feixeyes的了。转载请注明。翻译一半发现这篇文章已经有人翻译过了,不管了反正都是出于学习的目的,至少这个烂版本的版权是额滴。转载请注明。 飘红部分我没有完全理解,不知道为什么是这样,如果有人看懂了还请赐教。
I think that I shall never see
A poem lovely as a tree.
Poems are made by fools like me,
But only God can make a tree.
- JoyceKilmer
问题背景
字符串匹配,是计算机编程人员经常遇到的一个基本问题。一些编程问题,比如数据压缩或者DNA序列化,都可以从字符串匹配算法的改进中受益。本篇文章讨论了一个跟字符串匹配相关的但不常见的数据结构——后缀树。并说明了如何利用它的特性来解决很难的字符串匹配问题的。
想象一下,你刚成为一个DNA序列化项目中的程序员。研究人员正在对病毒的遗传物质进行切片和切块,以产生核苷酸序列的片段。他们把这些遗传物质序列片段送人你的服务器进行匹配,希望能够在基因组数据库中定位到这些序列。一个特定的病毒的基因组可能有数十万的核苷酸,并且在你的数据库中存储了成千上万的病毒的信息。希望你能够实现一个C/S结构的项目,来实时的为研究人员提供服务。怎么做才比较好呢?
很显然,用暴力搜索是一个很糟糕很低效的方式。这种方式需要匹配数据库中所有的基因组中的所有的核苷酸。你面临的挑战就是怎样高效的实现字符串匹配。
一个直观的解决方法
因为数据库是不变的,所以对它进行预处理以使得搜索变得简单,看起来像一个不错的主意。一种预处理的方式是建立一个字典树(trie)。对于查找的输入信息是文本的情况,用这种方式生成的字典树,称为后缀字典树(suffix trie),后缀字典树只差一步就是我最终要引入的数据结构——后缀树。字典树是一种N叉树,其中N是字母表的大小。‘后缀’一词说明,该字典树中存放的是给定字符串的所有后缀。
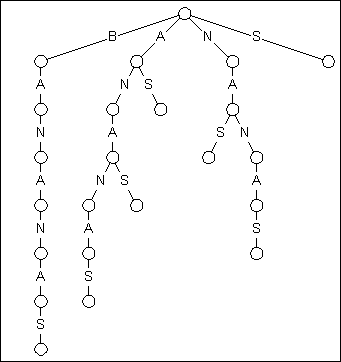
图1
"BANANAS"的后缀树
图1展示了字符串‘BANANAS’的后缀树。关于该字典树有两点需要特别指出:第一点,从根节点开始,‘BANANAS’的所有后缀都可以在该字典树中找到,他们分别是从字母A,B,N,S开始,以一个单独的S结束;第二点,根据这种结构,你只需要从根节点开始然后往下顺次匹配,就可以查找该字符串的任何子串。
什么造就了如此漂亮的一个数据结构——后缀字典树。如果你有一个输入文本长度为N和一个待查找串长度为M,传统的字符串暴力搜索算法需要N*M次字符比较。优化的搜索技术比如BMP算法可以在不多于N+M次比较就完成查找。但是后缀字典树完成搜索只需要M次字符比较,不用管待搜索的文本的长度!
很显然,我只需要七次字符比较就可以确定单词“BANANAS”是否在莎士比亚的所有文集中出现过。当然仅仅有一个小问题会拖后腿儿,那就是创建字典树所耗费的时间。
你没听说过后缀字典树有什么应用,原因很简单,因为它的构造需要O(N2)时间和空间复杂度。这种平方级的性能使它不能在最需要用到它的地方使用,即不能在大数据量场合使用。
后缀树
Edward McCreight 在1976年提出了一个合理的解决方法摆脱了后缀字典树在应用上的困境,他发表的论文中提出了后缀树(suffix tree)。一个指定的文本的后缀树和相应的后缀字典树有着相同的拓扑结构,但是它去除了只有一个子边(飞说不可:原文是后继,因为通常树结构中的后继是指节点。而这里是指从该节点发出的边,为了加以区分我这里称为子边)的节点。这个过程被称为路径压缩,意味着单个边现在可能表示一个字符串而不只是单个字符。
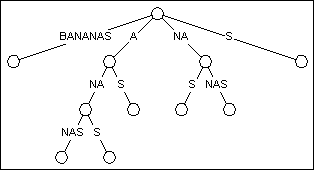
图 2
"BANANAS"的后缀树
图2展示了 图1 变换成后缀树的结构。你可以看出树的形状没有改变,只是节点更少了。它移除了只有一个子边的节点,节点的数量从23个减少到了11个。
事实上,节点数量的减少,使构造后缀树的时间和空间复杂度从O(N2)减少到了O(N)。在最坏的情况下,一个后缀树最多包含2N个节点,其中N是输入文本的长度。所以对输入文本的一次性投资,可以使我们的每次搜索都受益。
Even you can make a tree(飞说不可:一语双关既对应文章前面的诗句,又作为小标题,所以不翻译)
McCreight 最初构造后缀树的算法有很多缺点,最主要的一点是它需要以输入文本的逆序来构建后缀树,也就是说需要从文本的最后一个字符开始倒着构造。这使得它不可以用作在线算法(online algorithm),使它更难被用于数据压缩。
二十年后,Helsinki大学的Esko Ukkonen 对该算法做了小小的改进使它可以从左到右来处理数据,克服了后缀树在应用中面临的困难局面。我的所有的代码和算法描述都是基于ukkonen的成果,他的论文发表在isssue of algorithmica1995。
对于一个指定的字符串,TUkkonen的算法是从一个空树开始,然后依次迭代的向后缀树中插入该字符串的N个前缀。例如,当构建‘BANANAS’的后缀树时,首先在树中插入B,然后是BA,接着是BAN依次下去,当BANANAS插入树中时,整个后缀树就构建完成了。

图3
后缀树的构造过程
构建后缀树的技术性技巧
向后缀树中增加一个新的前缀,需要遍历到当前后缀树中的已经存在的所有的后缀。我们从最长的后缀(图3中的BAN)开始,然后依次遍历各个后缀,直到最短的后缀——空串,也就是根节点。每一个后缀都是以下面三种方式之一结束:
- 叶节点,在图4中,编号为1,2,4,5的节点是叶节点。
- 显式节点,非叶节点的节点称为显示节点,在图4中的0,3都是显示节点。
- 隐式节点,在图4中,前缀BO,BOO,OO,都是在一个边的中间结束的,这些位置被称为隐式节点。他们在后缀字典树(suffix trie)中是节点,但是在路径压缩时被剔除。在后缀树的构造过程中一个隐式节点可能会被转化成显式节点。
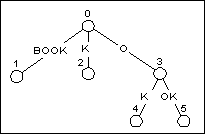
图4
BOOKKEEPER 已经构建到 BOOK时的后缀树结构
在图4,加入“BOOK”后,算上空后缀,一共有五个后缀。加入下一个前缀“BOOKK”,需要访问树中的每一个后缀,然后再在找到的后缀的结尾加上K。
前四个后缀,BOOK,OOK,OK,K都是在叶节点结束。由于使用了路径压缩,所以在叶节点上增加一个字符只需要在相应节点的字符串上增加相应字符。这种情况下并不会产生新的节点。
当所有的叶节点都更新完毕时,我们需要在空串上添加字符‘K’了,空串由节点0表示。因为已经有一个从节点0出发的边是以K开始的,所以我们不必做任何事。新添加的后缀K可以在节点0和节点2之间的边上的隐式节点中找到。
加入BOOKK后的最终树的结构在图5中显示。
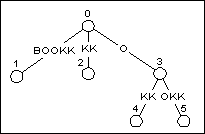
图 5
加入BOOKK后的后缀树结构
问题变得棘手
更新图4中的后缀树相对比较简单,我们只需执行两种更新:第一种只需要简单的扩展一条边上的字符串就可以了,第二种是一种隐式更新,事实上什么也不需要做。在图5中加入BOOKKE需要引入另外两种新的更新方式。第一种,添加一个新的节点需要先把一条边在一个隐式节点分裂,然后加入一条新的边。第二种更新是在一个显式节点上增加一条新边。
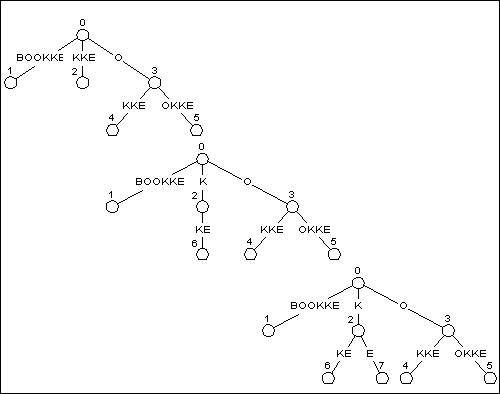
图 6
边的分裂和添加新边过程
当在图5中添加BOOKKE时,我们仍然从最长的串即BOOKK开始,然后是更短些的后缀,最后是空串。只在叶节点上的后缀更新起来还是很简单的。在图5中,以叶节点结束的后缀是BOOKK, OOKK, OKK和KK。图6中的第一棵树显示了只使用简单的字符串扩展的方式更新过这些后缀之后的树。
图5中第一个没有在叶节点结束的后缀是K。当更新一个后缀树时,第一个不是在叶节点结束的后缀被称作该树的激活点(active point)(此处也就是K了。所有比激活点定义的后缀更长的后缀都是在叶节点上结束(即后缀BOOKK,OOKK, OKK, KK 都是在叶节点上结束)。所有在激活点之后加入的后缀都不以叶节点结束。(这句话真心的不理解,原文粘出来大家分析下吧)(All of the suffixes that are longer than the suffix defined by the activepoint will end in leaf nodes. None of the suffixes after this point willterminate in leaf nodes.)
后缀K,在边KKE上的一个隐式节点上结束(在处理后缀K时,边KK已经扩展成KKE)。当处理一个非叶节点的时候,我们需要检查一下该节点是否有某个已经存在的子边和新添加的字符相匹配(对于隐式节点就是检查下一个字符)。这里就是看是否下一个字符是E。
因为在KKE的隐式节点处所以我们可以快速的观察到K的后继字符是K,这就意味着我们必须为K添加一个代表字母E的子边。这是一个两步的过程,第一步我们将包含隐式节点的那个边进行分裂,图6中的中间的那棵树显示了分裂后的树的结构。
一旦分裂已经完成,并且已经添加了新的节点,你就会得到一棵像图6中的第三棵树那样的树。注意节点K,已经成为了节点KE,并且成了一个叶节点。
更新一个显式节点
当更新过后缀K之后,我们还需要更新下一个更短的后缀——空串。空串在显式节点0结束,所以我们只需要检查一下节点0是否有一条子边以字符E开始。从图6中我们可以很快的看出,节点0没有以字符E开始的子边,所以一个新的叶节点被添加,最终产生了图7中的树结构。
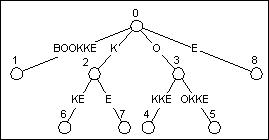
Figure 7
算法概括总结
利用后缀树的一些特性,我们可以得到一个相当高效的算法。首先最重要的特征是:叶节点永远是叶节点。叶节点一旦被创建成叶节点,就永远不会再产生后继节点,只会以字符连接的方式对边进行扩展。更重要的是,事实上这种扩展是必然发生的,每次我们将一个新的前缀添加进该树时,我们都会对指向叶节点的边添加一个字符来进行扩充。这个字符就是新的前缀的最后一个字符。(飞说不可:一个字符串的N个字符会依次的添加到当前的每一条指向叶节点的边中。)
这使得对一个指向叶节点的边进行管理变得简单。每次我们创建一个新的叶节点时,我们只需要设置它的边表示从相应的开始位置到整个字符串的结尾。甚至我们还不知道这些即将输入的字符串完整的数据,但是我们知道它们会被添加到树中。因此,一旦一个叶节点被创建了,我们就不必再管它了!如果它的边发生了分裂,它的开始位置将会改变,但是它仍然以输入文本的最后来结束。
这意味着我们只需要关心在激活点上的显式节点和隐式节点。也就是我们需要处理从激活点到空串的那些后缀,来看看它们是否需要更新。事实上,我们可以更早的结束更新。当我们处理后缀树时,我们将给那些没有相应字符开始的后继的节点增加一条新边。当我们最终发现了一个节点有相应的字符的边作为后继时,更新就可以停止了。一旦知道了构造算法是怎么运作的,你就会发现如果你找到了一个后缀有某个字符开始的子边时,你可以发现每一个更小的后缀也一定有相应的子边。
你发现的第一个匹配子边称为结束点(是一个后缀)。结束点还有一个特性使它特别的有用。因为我们给激活点和结束点之间的每一个后缀都增加叶节点,我们现在可以知道每一个比结束点长的后缀是叶节点。这意味着,结束点在后缀树的下一趟遍历中将成为激活点!
通过限定我们的更新在激活点和结束点之间,我们减少了更新后缀树需要的操作。而且通过记录结束点,我们知道了下一次遍历中激活点的位置。根据以上的内容后缀树的一遍更新的伪代码如下:
C:
1. Update( new_suffix )
2. {
3. current_suffix = active_point
4. test_char = last_char in new_suffix
5. done = false;
6. while ( !done ) {
7. if current_suffix 在显式节点结束 {
8. if 该节点没有任何子边是以test_char开始的
9. 创建一个边从该显式节点开始的叶节点
10. else
11. done = true;
12. } else {
13. if 隐式节点的下一个字符不是 test_char {
14. 在该隐式节点处分裂对应的边
15. 创建一个新的边从这个隐式节点开始的叶节点
16. } else
17. done = true;
18. }
19. if current_suffix 是空串
20. done = true;
21. else
22. current_suffix =next_smaller_suffix( current_suffix )
23. }
24. active_point = current_suffix
25. }
后缀链接(The Suffix Pointer/suffix link)
上面展示的伪代码,基本上是正确的,但是它回避了一个问题——当我们遍历后缀树时,我们通过函数next_smaller_suffix()来移动到下一个更小的后缀(注意前面说过,该算法是从长到短顺次访问当前后缀树中的所有后缀)。这个函数用来找到关于一个特定后缀的显式节点或隐式节点。如果我们遍历整棵树来查找下一个我们需要的后缀,那么我们的算法就不是线性复杂度了。为了避免遍历整棵树,我们需要给树节点增加一个指针:后缀链接。
每一个内部节点会维护一个后缀链接指针。每一个内部节点表示从根节点到该节点的字符串,后缀链接指向代表这个字符串的第一个后缀的节点。所以如果一个字符串表示文本从第i个字符到第N个字符,那么它的后缀链接将指向代表从第i+1个字符到第N个字符的字符串的那个节点。
图8展示了ABABABC的后缀树。第一个后缀链接是属于表示字符串ABAB的节点。字符串ABAB的第一个后缀(除了它自身)是BAB,所以节点ABAB的后缀链接指向表示BAB的节点。同样的,BAB也有它自己的后缀链接,它的后缀链接指向表示AB的节点。
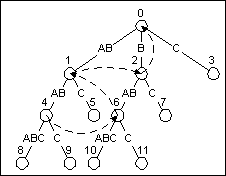
Figure 8
ABABABC 的后缀树,其中后缀链接用虚线表示
当更新后缀树的同时会建立相应的后缀链接。 当我从激活点向结束点移动时,我记录着创建的新的叶节点的父节点。每当我创建一条新边时,我都会创建一个后缀链接,从上一个我创建的叶节点的父节点指向当前的父节点。很显然,对一个创建的边我没法这样做,但是之后的边我都可以用这种方法。
Each time I create a new edge, I also create a suffix pointer from the parent node of the last leaf edge I created to the current parent edge. (Obviously, I can't do this for the first edge created in theupdate, but I do for all the remaining edges.)
有了后缀链接之后,通过指针就可以很简单的得到下一个后缀。这个关键的改进使算法的复杂度减少到了O(N)。
Tree houses(小木屋—代码库)
为了方便展示文章的思想,我写了一个简短的程序,它从标准输入中读入字符串然后构建一个后缀树。另一个版本加入了更多的调试信息。它们都可以从文章下面的链接来得到。
要想理解这个程序,关键是理解其中的数据结构。其中最重要的一个数据结构是 Edge ,它的定义如下:
C++:
1. class Edge {
2. public :
3. int first_char_index;
4. int last_char_index;
5. int end_node;
6. int start_node;
7. void Insert();
8. void Remove();
9. Edge();
10. Edge( int init_first_char_index,
11. int init_last_char_index,
12. int parent_node );
13. int SplitEdge( Suffix &s );
14. static Edge Find( int node, int c );
15. static int Hash( int node, int c );
16. };
每次后缀树中增加一个新边时,就创建一个新的 Edge 对象来表示它。 Edge 的四个数据成员对象定义如下:
first_char_index, last_char_index:
(飞说不可:这两个参数表示Edge对应的字符串在原文本中的起止位置)
后缀树中的每一个边都有输入文本中的一段字符串与它相关联。为了保证每一条边的存储大小相同,我们使用输入文本的两个索引来表示对应的字符序列。
start_node:
边对应的起始节点的编号。根节点的编号为0。
end_node:
边对应的终止节点的编号。每次创建一个新的边时,就会创建一个新的对应的终止节点。在树的整个生命周期里,一个边的终止节点是不会改变的,所以end_node还可以用作一个边的ID。
构造后缀树的过程中很常见的一个操作是,在一个特定节点的所有子边中查找以某个字符开始的子边。在一个字节编码的系统中,从一个节点最多会有256个边。(飞说不可:一个节点会有多少个子边还是由字母表的大小决定的,在一个中文系统中字母表的大小可比256大的多了)为了快速准确的查找一个边,我使用哈希表来存储边,我使用边的开始节点和对应的字符串的第一个字符来作为哈希key。Insert() 和 Remove() 函数通过操作哈希表来管理边的添加与删除。
构造后缀树时用到的第二个重要的数据结构是 Suffix 。你应该还记得更新一个后缀树,是通过从最长的后缀开始直到最短的后缀(空串)依次遍历树中当前存储的每一个后缀来完成的。一个后缀其实就是一个从节点0开始,在树中的某一个位置结束的字符串序列。很明显通过以上分析我们知道,只需要记录后缀最后一个字符所在的的节点就可以确定的精确的表示该后缀。因为我们知道它第一个字符一定是从节点0(根节点)开始的。
下面给出 Suffix 的定义:
C++:
1. class Suffix {
2. public :
3. int origin_node;//closet parent node to the last char
4. int first_char_index;
5. int last_char_index;
6. Suffix( int node, int start, int stop );
7. int Explicit();
8. int Implicit();
9. void Canonize();
10. };
飞说不可:这段有点儿绕,我只说明一下其中的成员变量,原文也粘贴出来大家自己分析下吧:
l origin_node: 后缀最后一个字符所在的边对应的节点。(事实上如果一个后缀在一条边的除了最后一个字符上面停止,那么origin_node等于该边的开始节点。但如果后缀在一条边的最后一个字符上停止,那么origin_node等于该边的结束节点。(图7中,后缀K对应的origin_node是2,后缀KK对应的origin_node也是2, 后缀KKE对应的origin_node是6,这个有点儿绕)
l first_char_index和last_char_index 标记出从origin_node开始到后缀结束的字符串。
The Suffix objectdefines the last character in a string by starting at a specific node, thenfollowing the string of characters in the input sequence pointed to by thefirst_char_index and last_char_index members.
举个例子,在图8中,最长的后缀“ABABABC”的origin_node 是0,first_char_index 为0, last_char_index 是6。(飞说不可:不要以为跟前面说的不一致。这是这个后缀的真实信息,但是并不是suffix这个数据结构中存储的信息,suffix存储的是后缀的canonical的形式)Ukkonen算法要求suffix以canonical形式表示。当一个Suffix对象被修改时,会调用函数Canonize( )来执行这种转换,即把后缀变成canonical形式。Canonical形式要求suffix的origin_node是距离对应字符串结尾最近的节点。(飞说不可:前面刚提过,为了加强理解再赘述一遍,如果一个后缀在一条边的除了最后一个字符上面停止,那么origin_node等于该边的开始节点。但如果后缀在一条边的最后一个字符上停止,那么origin_node等于该边的结束节点。)这就意味着,表示后缀”ABABABC”的结构,最初是(0, "ABABABC")经过canonical转换变成 (1, "ABABC"), 继续canonical转换变成(4, "ABC"), 直到转换成(8,"")。
当一个后缀在一个显式节点结束时,canonical形式的后缀结构中用一个空字符串来表示剩余的字符串。使用first_char_index大于last_char_index来表示空字符串,即此时说明后缀是在一个显式节点处结束。当first_char_index小于等于last_char_index时,说明后缀是在一个隐式节点结束的。
给出以上数据结构的定义后,我相信你已经知道STREE.CPP是直接按照ukkonen的基本思想实现的。而STREED.CPP在运行时会输出更多的调试信息。
致谢
I was finally convinced to tackle suffix tree construction by readingJesper Larsson's paper for the 1996 IEEE Data Compression Conference. Jesperwas also kind enough to provide me with sample code and pointers to Ukkonen'spaper.
飞说不可:人家的感谢我就不翻译了,在此我感谢一下原文作者 Mark Nelson,没有他写的这篇文章和代码,想要弄懂ukkonen算法我还得一段时间努力呢。
参考文献
E.M. McCreight. A space-economical suffix treeconstruction algorithm. Journal of the ACM, 23:262-272, 1976.
E. Ukkonen. On-line construction of suffixtrees. Algorithmica, 14(3):249-260, September 1995.
飞说不可:上面是原文的参考文献,而我的参考文献很显然就是原文了下面给出原文链接:
http://marknelson.us/1996/08/01/suffix-trees/ Posted in August1st, 1996
by Mark Nelson in Computer Science, Data Compression, Magazine Articles
Source Code
Good news - this source code has been updated. It was originally publishedin 1996, pre-standard, and needed just a few nips and tucks to work properly intoday's world. These new versions of the code should be pretty portable - thebuild properly with g++ 3.x, 4.x and Visual C++ 2003.
飞说不可:这些也不重要就不翻译了 ,简单的说,在2006年他对原先写的那份代码进行了更新,大家就使用2006年他重新写的版本就行了。其中streed2006.cpp比stree2006.cpp多了更多的调试信息。事实上streed.cpp每加入一个字符就会输出很多信息并且暂停。运行很简单,不需要任何配置,直接编译运行就可以了。然后控制台上会提示你输入一个字符串,输入之后,程序会显示出后缀树中包含的所有边信息。然后会询问你需不需要验证一下树的有效性。输入的字符串如果结束的字符在字符串中出现多次,构造出的后缀树将不是有效的,因为会有一些后缀在非叶节点上结束。
Asimple program that builds a suffix tree from an input string.
这个版本加入了更多的调试信息。
下面是最初的版本,但是不建议使用:
Asimple program that builds a suffix tree from an input string.
Thesame program with much debugging code added.














 1870
1870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









