







在此仅记录MapReduce的概念和配置运行,至于采用MapReduce架构的编程本篇不涉及,以后的文章中会记录。
1.MapReduce介绍
MapReduce是hadoop的计算框架。MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
MapReduce是一主多从架构,其主是指JobTracker、从指TaskTracker
- 主JobTracker
负责调度分配每一个子任务task运行于TaskTracker上,如果发现有失败的task就重新分配其任务到其他节点。每一个hadoop集群中只有一个JobTracker,一般它运行于Master节点上。 - 从TaskTracker
TaskTracker主动与JobTracker通信,接受作业,并负责直接指向每一个任务,为了减少网络带宽TaskTracker最好运行在HDFS的DataNode上。
下图是一副介绍MapReduce架构经典例子(统计单词个数)的截图
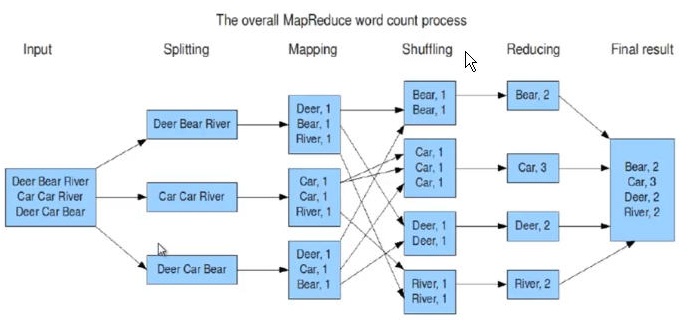
从上图我们可以看到,MapReduce框架包含Map端、Reduce端,中间还有一个shuffle过程,下面是一副MapReduce框架处理数据的示意图:
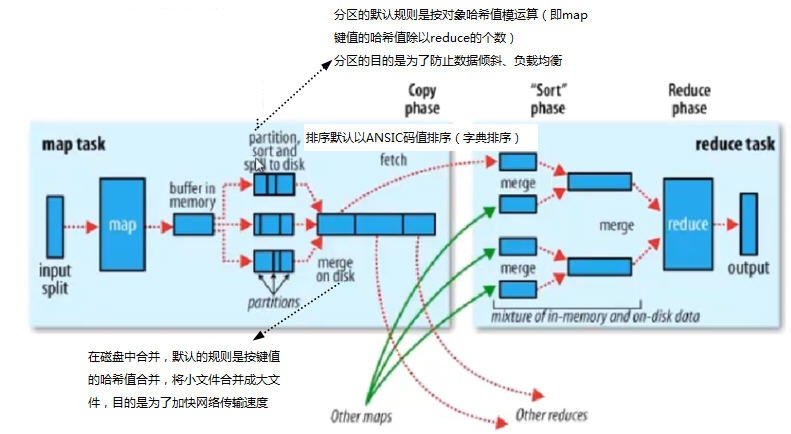
- Map端
1)每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2)在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据(这样做是为了数据负载平衡,避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面),其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combiner操作,这样做的目的是让尽可能少的数据写入到磁盘。
3)当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combiner操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4)将分区中的数据拷贝给相对应的reduce任务。分区中的数据匹配对应的reduce的过程:map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出的位置就行。 - Reduce端
1)Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接收的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则将数据合并后溢写到磁盘中。
2)随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作。这就是问什么很多人说“排序是hadoop的灵魂”。
3)合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。 - Shuffle
Shuffle是map和reduce之间的过程,包含combine和partition(在上面的map和reduce的描述中已经涉及到了shuffle)
combine和partition都是函数。
combine分为map端和reduce端,作用是把同一个key的键值对合并在一起,可以自定义。具体描述就是:把一个map函数产生的{key,value}对(多个key,value)合并成一个新的{key2,value2}.将新的{key2,value2}作为输入,送到reduce函数中。这个合并的目的是为了减少网络传输。
partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定义的。这里其实可以理解归类。默认的mapreduce使用哈希HashPartitioner帮我们归类了,这块儿也可以自行定义。
下图是一副Shuffle的处理流程图:

上面是MapReduce框架的主要构成部分的介绍,在第一张图中我们还可看到在map前还有一个阶段是split阶段,下面简单对这个阶段做个介绍:
输入分片(input split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片针对一个map任务,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片往往和hdfs的block(块)关系很密切,假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片,65mb则是两个输入分片,而127mb也是两个输入分片,换句话说我们如果在map计算前做输入分片调整,例如合并小文件,那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。因此map任务前进行数据的合并也对提升性能有帮助。
下面这张图也是介绍MapReduce架构的经典图(即:在hadoop中如何运行MapReduce的)
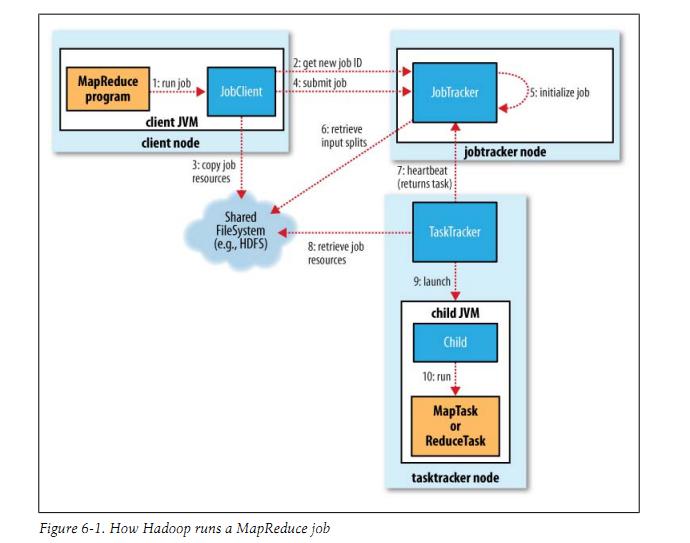
最后从物理实体讲一下MapReduce作业执行的4个独立实体,即:
1)客户端(client):编写MapReduce程序,配置作业,提交作业。(由程序员来完成)
2)JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行。
3)TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务,TaskTracker和JobTracker的不同有个很重要的方面,就是在执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个(JobTracker只能有一个就和hdfs里namenode一样存在单点故障)
4)Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面。
2.MapReduce在Hadoop中的配置
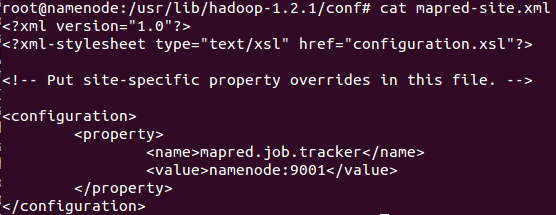
在Hadoop中我们需要配置MapReduce的JobTracker节点,我们需要在”hadoop源文件/conf/”文件夹下修改mapred-site.xml文件,如下图,图中我们配置的JobTracker节点为namenode这台机器:
我们不仅需要配置NameNode这台机器的mapred-site文件,其他的datanode节点也需要配置,通过scp命令将配置好的mapred-site.xml文件复制到其他datanode机器上
root@namenode:/usr/lib/hadoop-1.2.1/bin# scp /usr/lib/hadoop-1.2.1/conf/mapred-site.xml >> root@ datanode1:/usr/lib/hadoop-1.2.1/conf/
通过bin/start-all.sh启动hadoop,我们会看到如下信息:
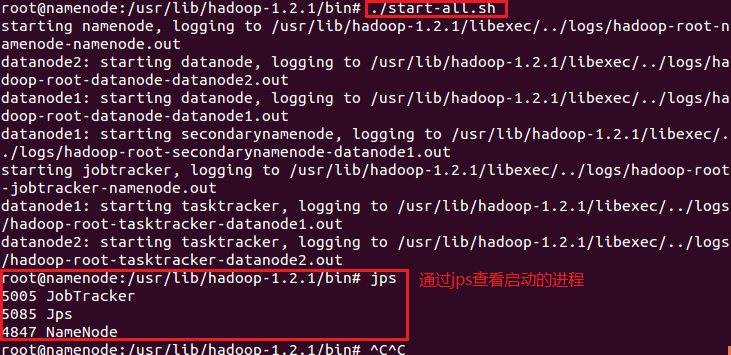
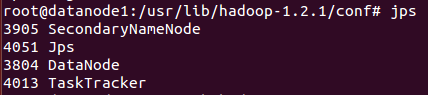
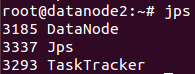
下图是datanode节点上的启动进程界面:
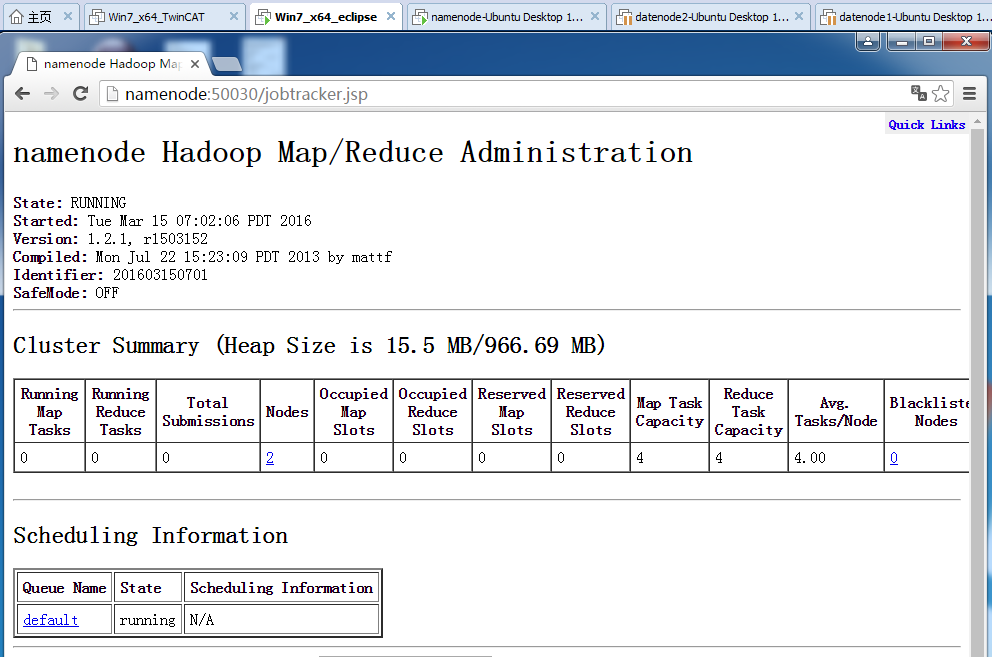
下图是从浏览器端看的MapReduce程序界面,web端的接口是50030,如下图:
本篇主要介绍MapReduce的运行机制和在hadoop上的环境配置。而MapReduce的编程、MapReduce程序的发布、Eclipse插件查看hadoop数据文件,这些将再以后进行记录。















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











