







1.例子:
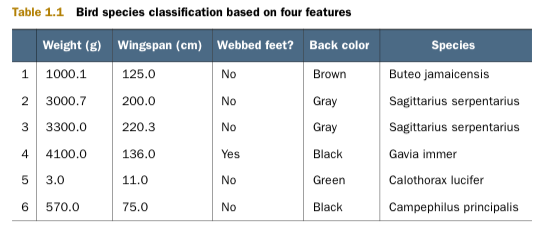
通过特征,预测鸟兽的种类。
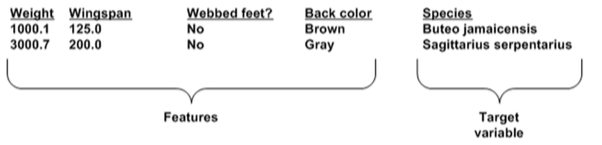
2.分类:
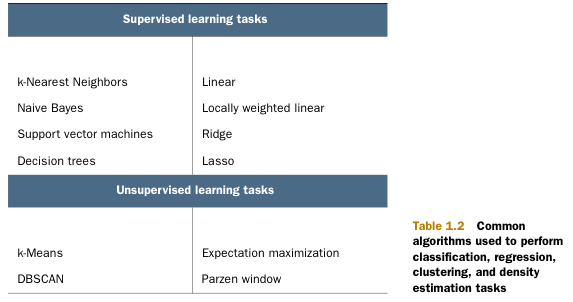
有监督学习:
分类和回归。分类主要任务是将实例数据划分到合适的分类中。回归的主要任务是预测熟知类型数据。
监督学习类算法必须要知道预测什么。
无监督学习:
数据没有类别信息,也不会给定目标值。在无监督学习中,将数据集合分成由类似的对象组成的多个类的过程被称为聚类(clustering)。将寻找描述数据统计值的的过程称之为密度估计(density estimatino)。
3.开发机器学习应用的步骤
(1)收集数据
(2)准备输入数据(使格式符合要求)
(3)分析输入数据(确保有没垃圾数据,是否有明显异常等)
(4)训练算法。(无监督无需)
(5)测试算法。
(6)使用算法。
4.选择合适的算法:
(1)考虑算法学习目的。如果想要预测目标变量的值,可以选择监督学习算法。否则可以选择无监督学习算法。
(2)考虑目标变量(Target variable)如果要预测数据,而目标变量是离散的,可以选择分类器。如果是连续的,可以选择回归算法。
如果不想要预测数据,只是想给数据分组,可以使用聚类算法。如果还要估计数据与每个分组的相似程度,则可能需要使用密度估计(density estimation)算法。
5.使用Python开发
NumPy library可以方便地进行矩阵计算
在终端输入Python(linux/mac os)
引入numpy Library,输入from numpy import *
获取一个随机矩阵数组
random.rand(4,4)
获取一个随机矩阵
mat(random.rand(4,4))
获取一个逆矩阵
randMat = mat(random.rand(4,4))
invRandMat = randMat.I
电脑计算会有误差,执行矩阵与逆矩阵相乘
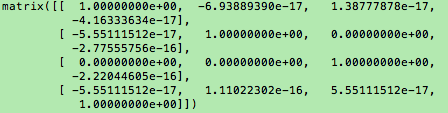
按理说应得单位矩阵,即主对角线为1,其余元素为0
获取误差得方法:
其中eye(4)生成一个四阶的单位矩阵。














 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









